
It’s been a bit over a year since we released BASED ✌️ at NeurIPS 2023 and we’ve been humbled by the response! This post is a quick retrospective of what’s stood out to us — beyond learning that using the word “BASED” can get you blacklisted on Twitter...
TL;DR: Over the past year, BASED ✌️ quietly reshaped the landscape of efficient architectures. Its fingerprints are all over today’s fastest and most capable efficient LMs — even when they go by different names (Mamba-v2, RWKV-v5/v6, MetaLA, MiniMax, Liger attention). In this post, we reflect on what made BASED work and how its ideas spread.
BASED Paper with Sabri*, Michael*, Aman, Silas, Dylan, James, Atri, and Chris!
Today's Transformer-based language models are just way too inefficient and a key question is whether we can get our AI capabilities using asymptotically cheaper modeling choices. Our work on BASED tackles this objective. As a reminder, BASED is a high-quality, efficient recurrent architecture built from two key principles:
- a short mixing operation (e.g., convolution, sliding window attention) to precisely compute the interactions between locally spaced, nearby words in text, and
- a linear attention with large state sizes to approximately compute the expensive interactions between far apart words
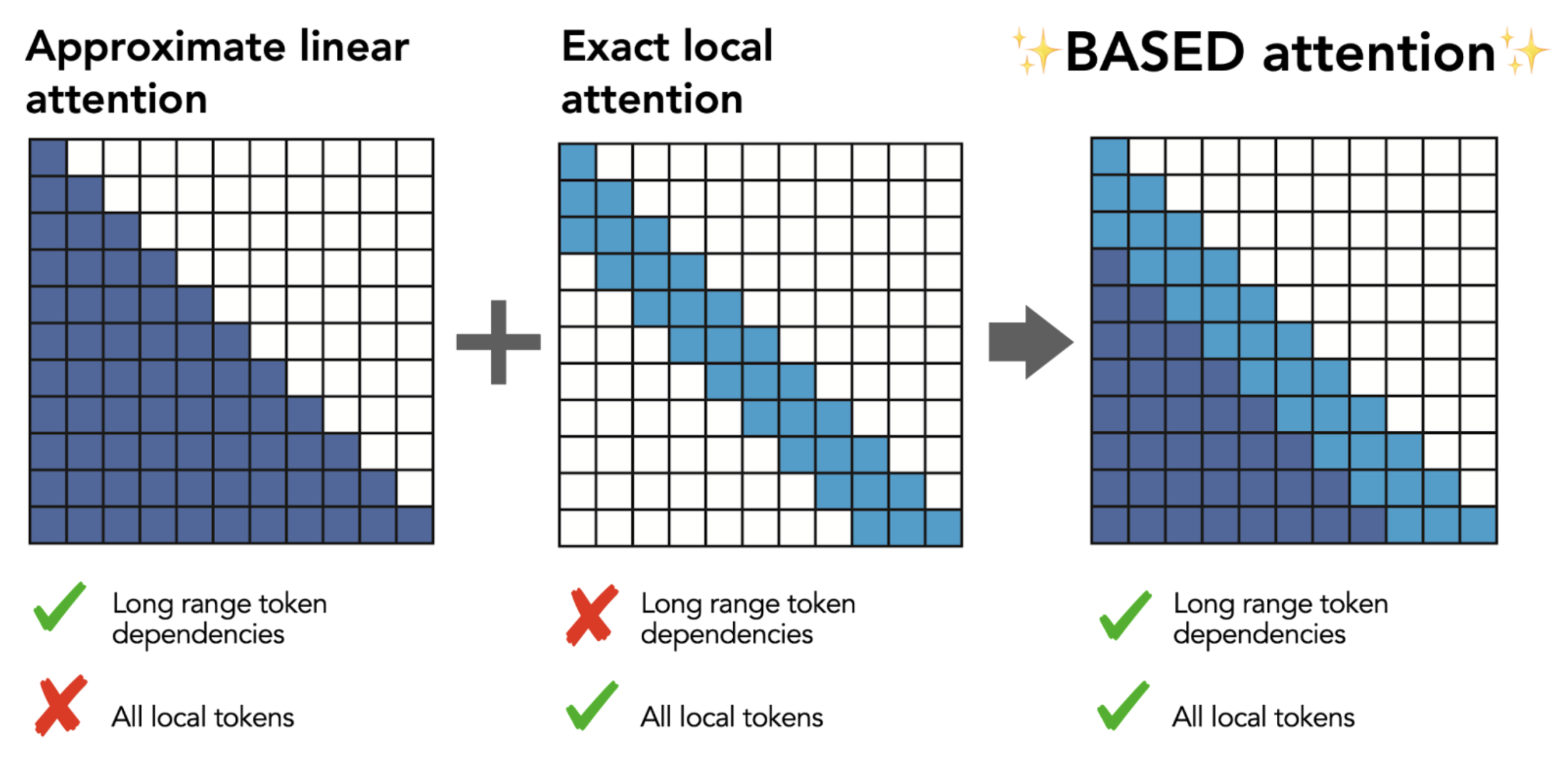
Key advances of BASED
While the BASED recipe is simple, we needed to get a lot of tricky pieces right to make it work. We had to map the true efficiency frontier — and cut through the hype: This year, headlines like the one on the right “efficient models outperform expensive Transformers everywhere” created excitement, but also a lot of confusion in the field. Our No free lunch studies helped add clarity — showing where efficient models shine, and where the tradeoffs really are.
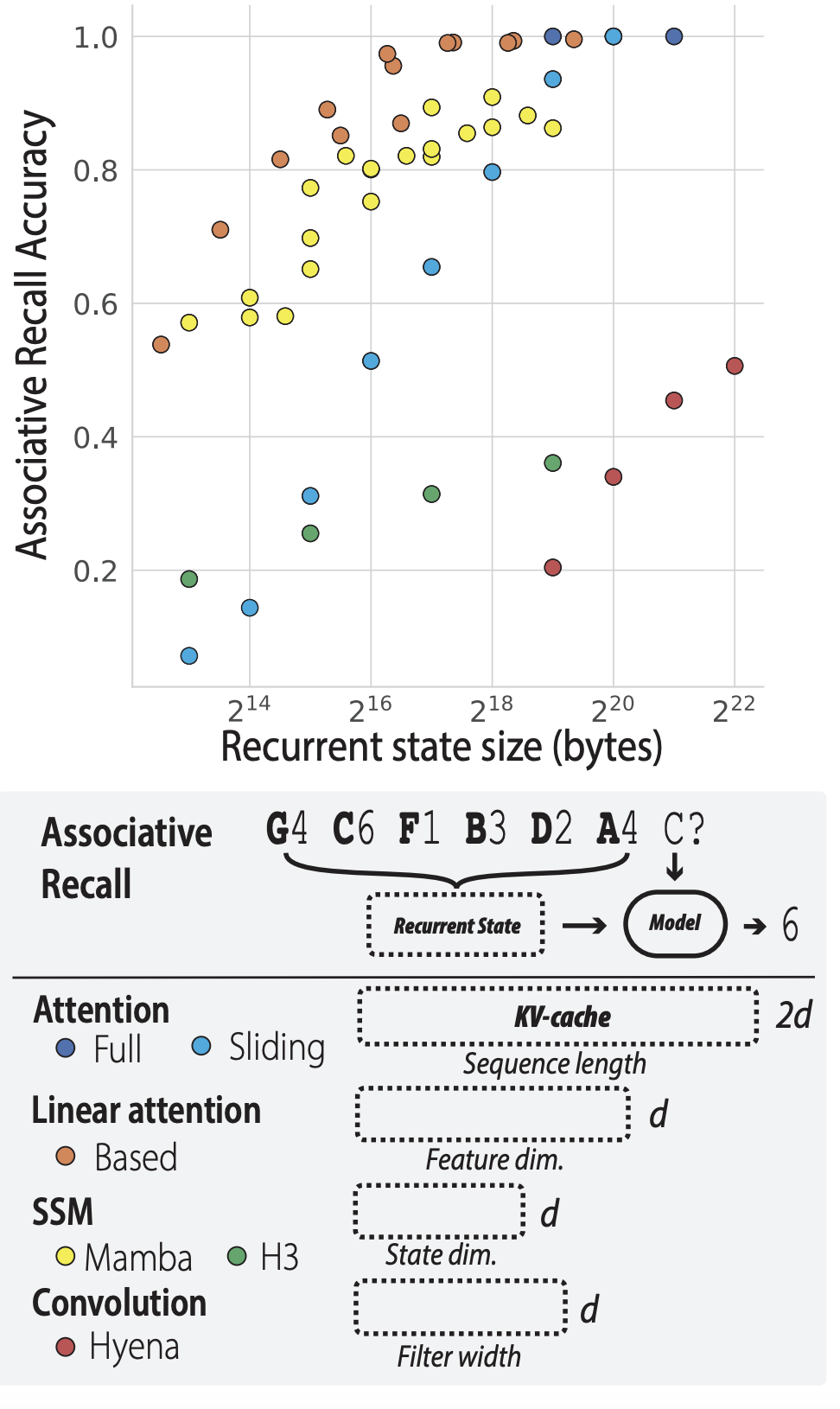
In particular, we showed: there is a fundamental tradeoff between the amount of information a model can recall from its context during inference and the amount of memory it utilizes during inference, called its "state size". Some models are better than others at using limited state. Transformers use massive state sizes making it trivial to recall info, gated state space models struggle in recall quality compared to alternatives, and BASED expanded the Pareto frontier.
The whole game of efficient models is figuring out how to use limited state as effectively as possible and many have since built on our work to push even further. We’ve been thrilled to see our tools for evaluating model recall abilities – like the MQAR synthetic and EVAPORATE task suite – become the de-facto evaluation standards in both academia and industry’s work on pushing this Pareto frontier for efficient models.

Once we cleaned up our understanding -- state size is the true fundamental tradeoff -- it became clear how to push forward with the BASED design. There were two key principles we used:
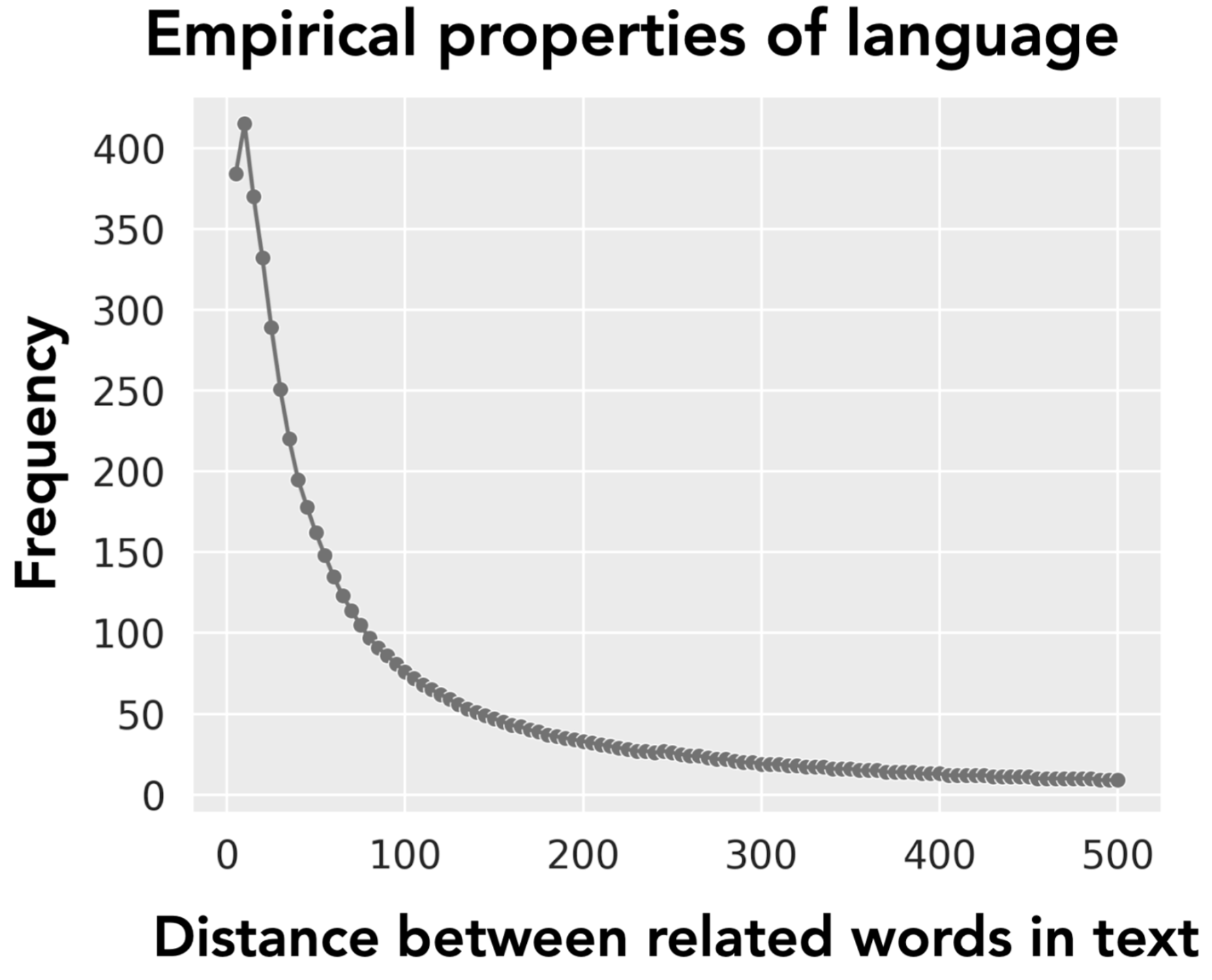
-
We built architectures from the data up! We observed and exploited the power-law distribution in language. Nearby words are often related — that’s where the precise local mixers in BASED help. Far-apart words may be related too, but infrequently — that’s where global approximate linear attention comes in.
BASED proved that efficient doesn’t have to mean weird. Before BASED, many efficient modeling efforts relied on choices like gated long convolutions (Together’s StripedHyena and RWKVs) or state space models (Mambas and Deepmind’s Griffin) with complex initializations and hard-to-optimize inductive biases, or large sliding window attentions which are hard to make hardware efficient (Mistral, Microsoft Samba). BASED showed that familiar attention-like primitives suffice for both high quality and efficiency. This was great, since the community has already spent a decade studying attention!
-
We built architectures from the hardware up! Prior architectures like Mamba and Griffin offered the quality, but ran into efficiency bottlenecks since they require tensor-core-unfriendly parallel scans. A lot of AI tries to take high-quality ideas and make them run fast — but that’s a tricky proposition. In our work, we were excited about flipping that status quo and starting from what the hardware prefers. This allowed us to use the state size of Mamba, while still running at the hardware utilization1
A year later, our BASED kernels remain the fastest linear attention kernels we know of! We demonstrated how to get linear attention to run fast on modern hardware by:
- Leveraging advanced hardware features: H100 WGMMA instructions alleviate pressure on precious register memory by allowing us to compute matrix multiplies directly from shared memory. H100 TMA instructions help us efficiently load/store data from/to HBM.
- Choosing hardware-efficient algorithms: We approximated the softmax kernel using the first 2 terms of a Taylor expansion of attention’s softmax . This structure gives great data reuse: polynomial terms share data across terms, letting us grow the state size while keeping HBM reads minimal. To put this another way, as the number of terms increases --- e.g., in --- this increases the recurrent state size (size of the resultant tensor), but each term reuses the same input (data reuse)! We found (a second order polynomial) was a sweet spot for running BASED on H100s — balancing quality and kernel throughput.
To dive even deeper into the technical details, check out some of our older blogposts here!
The impact
The BASED ✌️ blueprint has quietly become the new standard along multiple dimensions:

-
BASED featured in a slew of new architectures this year — like MiniMax and Liger attention! Within the 6-8 months from BASED ’s NeurIPS 2023 debut, teams that previously used state space models (Mamba-v1, RWKV-v4) have switched to BASED-inspired structures — linear attention with large states + local mixers — in Mamba-v2, RWKV-v5/v6, MetaLA, and more. Mamba-v2 has been used in Tencent’s Hunyuan-T1, Nemotron-H, Vamba, and more! These models aren’t just Mambas — they’ve embraced the BASED philosophy!
-
BASED ideas crushed in quality! In work led by Michael Zhang, we released state-of-the-art 8B parameter Transformer-free models. We showed that we could convert Transformer checkpoints to BASED style models with minimal loss — or even gains — in quality and major speedups, without training from scratch. Our models outperformed efforts by Nvidia Mamba, Google Deepmind Griffin, Together AI Mamba-2, Together AI StripedHyena, and Toyota Research SUPRA ... with 35%–103% higher 5-shot MMLU accuracy across the board.
We scaled our recipe to 50x the size of other Transformer-free models, releasing the largest such models to date at 405B parameters — on an academic budget. What do we mean by academic budget? Well we trained our 405B models using 16 GPUs for 2 days contrasting the 16000 GPUs for 54+ days, which Meta used for Llama 405B!!!
-
We needed to build new systems and tools along the way! To help ourselves and others build AI from the hardware up, we spent the last year developing ThunderKittens (TK) — our opinionated DSL for AI kernel programming. TK makes writing AI kernels fun and fast. Turns out others agreed — it’s now used in industry (GPU Mode, Meta, Cruise, Jump Trading, Together AI, etc.) and academia (Berkeley, Stanford, University of Italy, UCSD, and more)... Emphasizing the impact, now one year after TK’s Mother’s Day 2024 release, NVIDIA GTC 2025 was all about TK-inspired DSLs like CuTile and Cutlass 4.0, which adopt TK’s Pythonic design and tile-based abstractions!
Signing off
So to summarize the lessons, we strongly recommend that future work on efficient models: think more about designing efficiency optimizations based on downstream workload properties (like the power law distribution of recall in language); embrace simple, effective operations like the short sliding windows in BASED to avoid overly complex solutions; and build architectures from the hardware up! Of course, there's still no free lunch with BASED and we need to push hard to keep expanding the Pareto frontier. We've explored some creative solutions as well.

Looking forward to continuing to build on this line of work and to seeing what the community uses it to create! Where BASED ✌️ Could Help You Next:
-
On-device models: Eliminate the KV-cache for resource-constrained hardware
-
Speculative decoding: Use BASED as fast draft models
-
High-throughput data processing: Classify, extract from, or answer questions over millions of documents orders of magnitude faster than Transformers
Keep us posted and reach out to collaborate! We’re so excited 💫