Mar 3, 2024 · 12 min read
Based: Simple linear attention language models balance the recall-throughput tradeoff
Full team: Simran*, Sabri*, Michael*, Aman, Silas, Dylan, James, Atri, Chris
Arxiv: https://arxiv.org/abs/2402.18668
Code: https://github.com/HazyResearch/based
In an ICLR paper (and blogpost) we posted towards the end of last year, we share the finding that many efficient architectures (e.g. Mamba, RWKV, Hyena, RetNet) underperform Transformers on recall, the ability to ground generations on information seen in-context, which is critical for in-context learning and copying. We used this analysis to design a new architecture called Based (previewed in this blogpost). We’re excited to share the latest progress in this line of work.
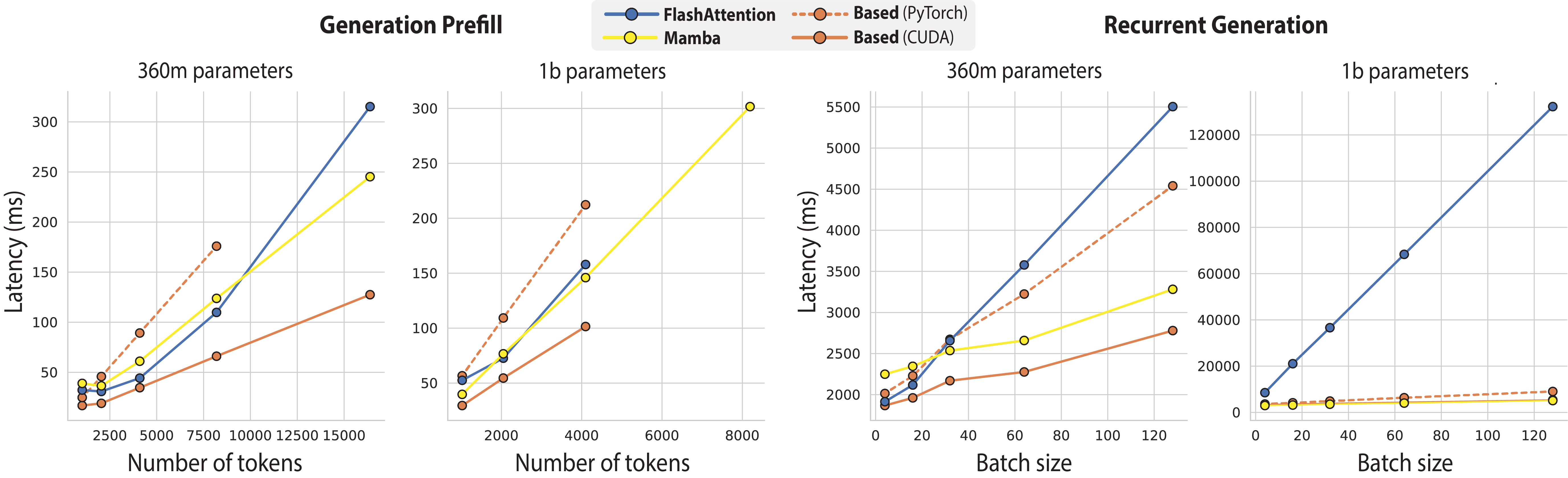
Our recent work digs deeper into the recall challenge. We begin by illustrating a fundamental tradeoff between a model’s recall abilities and its memory consumption during generation. This analysis informs the design of Based, a simple recurrent architecture that outperforms prior sub-quadratic models on real-world recall-intensive tasks (information extraction, reading comprehension) and in-context learning. At the same time, Based offers fast generation speeds: Based is 56% and 44% faster at processing prompts than FlashAttention-2 and Mamba respectively. Based achieves 24x higher text generation throughput than FlashAttention-2.
We’re particularly excited about the simplicity of Based. Using just two well-known, attention-like building blocks, sliding window attention (with tiny window sizes) and linear attention (with Taylor series approximation of ), we can outperform the strongest sub-quadratic architectures on language modeling and achieve massive speedups over optimized Transformers!
This blogpost provides an overview of our 1) analysis on recall in sub-quadratic architectures that leads to the Based design and 2) how we make Based go brrrr!
Motivating analysis: the recall-memory tradeoff. The main question driving our exploration is: can we drastically improve the real-world speed and memory consumption of language models without compromising on recall and in-context learning capability?
To begin answering this question, we had to first think about what slows architectures down. Efficient architectures (e.g. Mamba) are much faster than Transformers at inference time (e.g. 5x higher throughput) in large part because they have a reduced memory footprint. Smaller memory footprint means larger batch sizes and less I/O. However, it also makes intuitive sense that reducing memory footprint too much could hurt a model’s capacity to recall information seen earlier in the sequence. This looked to us like a classic “no free lunch” situation, so we took a number of popular architectures, varied the hyperparameters that affected the memory footprint, and evaluated performance on a challenging synthetic associative recall task.
The recall-memory tradeoff. We found that all architectures obeyed a fundamental tradeoff: the less memory the model consumed during inference, the worse it did on associative recall. We focused on the recurrent state size, the number of bytes used to represent previously seen tokens when generating tokens one-by-one (i.e. recurrently).
In attention, the state is commonly referred to as the KV-cache, and it grows with the length of the sequence. In the top right of Figure 1, we can see that attention performs recall perfectly, albeit at the cost of a huge recurrent state. Sliding window attention provides a way to cap the size of the KV-cache, but we found (unsurprisingly) that recall performance drops off rapidly as we reduce the size of the recurrent state (e.g. from 100% with 1MB recurrent state to 50% with a 65 KB recurrent state) (Figure 1, light blue).
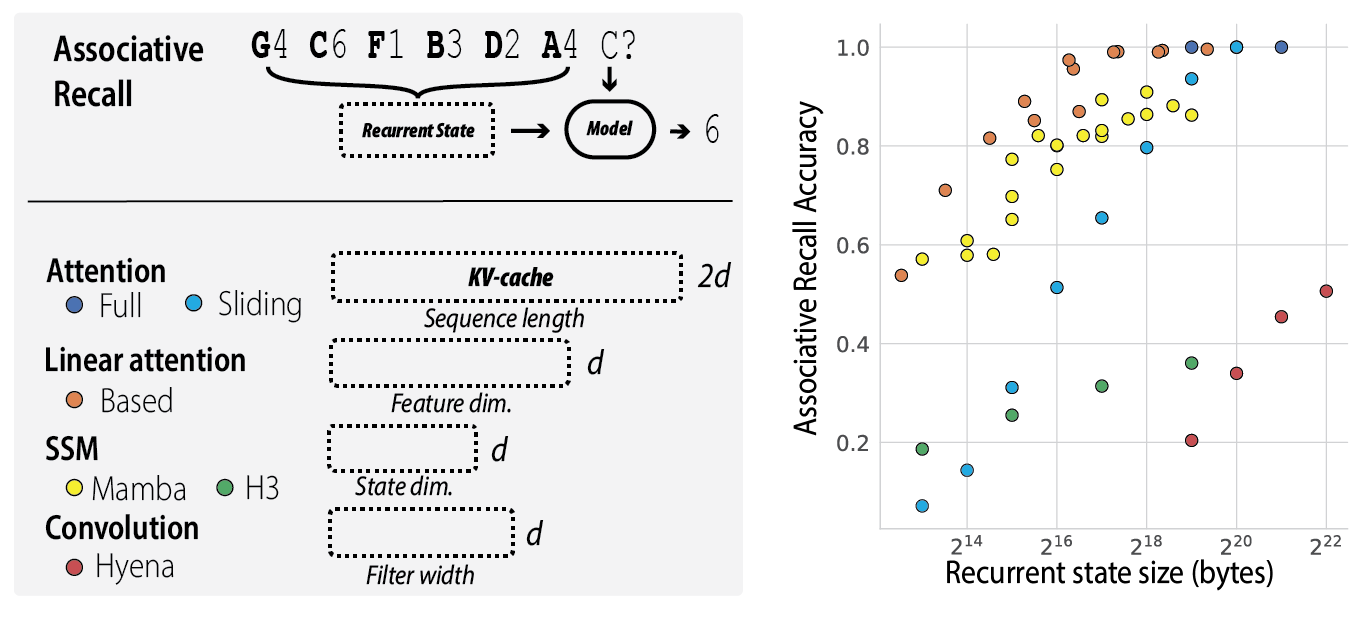
Excitingly, we found that Mamba expands the pareto frontier of the recall-memory tradeoff curve beyond sliding window attention. This means it is making better use of limited recurrent state size than approaches like sliding window attention.
The natural question is: are there other, perhaps simpler, models that can also expand the pareto frontier?
Based: a simple model at the pareto frontier. To answer this question, we started studying why the simplest alternatives to softmax attention fail to strike a favorable tradeoff. As a further design principle, we searched for primitives that could scale well on current and future hardware. For instance, it would be nice if our primitives could leverage GPU Tensor Cores, specialized hardware on modern GPUs that can perform matrix multiplications (GEMMs) 16x faster for 16x16 matrices than the default (CUDA cores)!
In our ICLR paper, we did a deep dive on why any model with a convolutional view (e.g. H3 or Hyena) will struggle on recall. Next, we considered two of the simplest efficient attention techniques out there: (1) sliding window attention and (2) linear attention (i.e. attention without softmax).
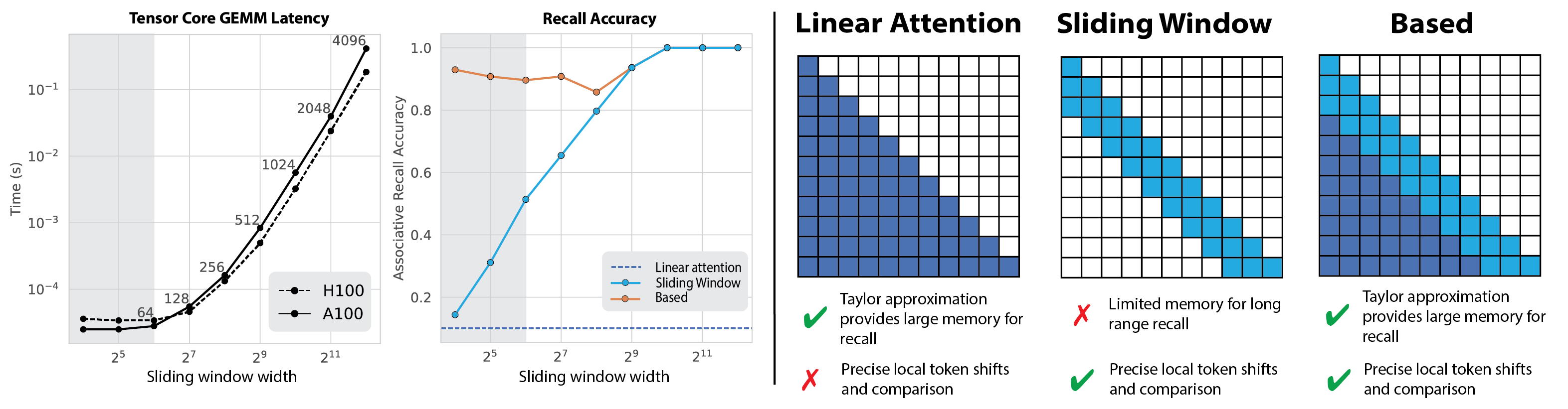
Our experiments on real-world language modeling (up to 1.4bn parameters) and synthetic associative recall suggested to us that neither primitive alone would suffice to navigate the pareto frontier.
-
We found that pure linear attention models struggled to perform precise local token shifts and token comparisons, skills important in recall (Fu et al., 2023; Arora et al., 2023a), as well as dense attention. Expanding on our findings, we do find that our pure linear attention model improves over earlier sub-quadratic architectures. Focusing on the recall-intensive slice of the Pile test set (i.e. next token predictions that force the model to use the prior context vs. memorized knowledge), the 355M pure linear attention model outperforms RWKV-v5 by 0.1 ppl and H3 by 2.6 ppl (Table 1, paper). Pure linear attention is even comparable to the Mamba architecture on this recall-slice – 2.21 ppl for Mamba vs. 2.29 for pure linear attention! However, we observe a sizeable gap to Transformers, which achieve 1.87 ppl on the recall slice.
-
In sliding window attention, models can only recall tokens within the sliding window (Figure 2, center). As we increase the window size, the recurrent state grows linearly and has a non-linear effect on speed during parallel training and inference (Figure 2, left).
However, we find the two primitives are complementary – linear attention for modeling long-range token interactions and sliding window for local token interactions in the sequence. We combined them into a single architecture, called Based (Figure 2, right).
-
Sliding window attention can perform the precise local shifts needed for associative recall. We use tiny window sizes (e.g. 64 in experiments) contrasting the larger window sizes in architectures like Mistral-7B and the recently proposed Griffin. Intuitively more attention (larger window sizes) is nice from a quality perspective, but we’d like to balance quality and wall-clock speed. To balance these objectives, let’s take a look at the left plot in the above figure. Observe that the latency of matrix multiplication for 16x16 vs. 64x64 matrices are roughly equal, and beyond 64, latency grows non-linearly with the window size. Note that the rough similarity between 16x16 and 64x64 is because the latter keeps the GPU tensor core occupancy high enough to saturate!
-
Linear attention enables global token interactions, while maintaining a fixed size recurrent state. Unlike softmax attention, the size of linear attention’s recurrent state is a function of hyperparameters (e.g. choice of feature map) and not sequence length. This allows us to traverse the tradeoff space smoothly. We use a Taylor approximation of the exponential function as the feature map, that was first used in our prior work on linear attentions!
Critically, the recurrent state size in Based does not grow with the sequence length, as it does in attention. Instead, it is determined by the linear attention feature dimension and the window size. By dialing these hyperparameters, we can tradeoff recall for throughput and navigate the pareto frontier in Figure 1.
Despite its simplicity, on real language modeling experiments (up to at least 1.3 billion parameters), Based is competitive with Mamba in terms of overall Pile perplexity and standard zero-shot benchmarks from the LM eval harness (shown under Question Answering - Common).

These commonly-used zero-shot benchmarks are limited to extremely short text, so they don’t stress test models’ recall capabilities. To address this shortcoming, we curated a small suite of real world recall-intensive benchmarks that require recalling information from long documents (e.g. information extraction from FDA documents and raw HTML, and reading comprehension). __Based is the strongest sub-quadratic architecture on these tasks, outperforming Mamba by 6.22 accuracy points on average. However, both Based and Mamba still underperform the strongest Transformer baseline, sometimes by large margins. This is consistent with our “no free lunch” observation above.
It’s important to note that we don’t believe Based is the only architecture that can operate at this point on the tradeoff curve. For example, we show in our paper that we can replace the sliding window attention with short-convolutions (filter size 3) and achieve similar performance within 0.1 perplexity points. We suspect that there are lots of other architectures that can also match this pareto frontier and we’re hopeful there are even others that can even expand beyond it!
How we use our fixed-size recurrent state matters too!
There are many recurrent architectures that might have the same hidden state size, but our work highlights how the featurization (e.g. linear attention feature map, state update mechanism) matters as well. Our choice for the map in Based is surprisingly simple (high-school calculus is all you need): it approximates the exponential with a Taylor series. We compute such that . We use just the second-order Taylor series as in our prior work, where ! Note that if has dimension then the term will have dimension ! The result of the key-value outer product (step 1 above) grows quickly in , expanding the state size for Based.
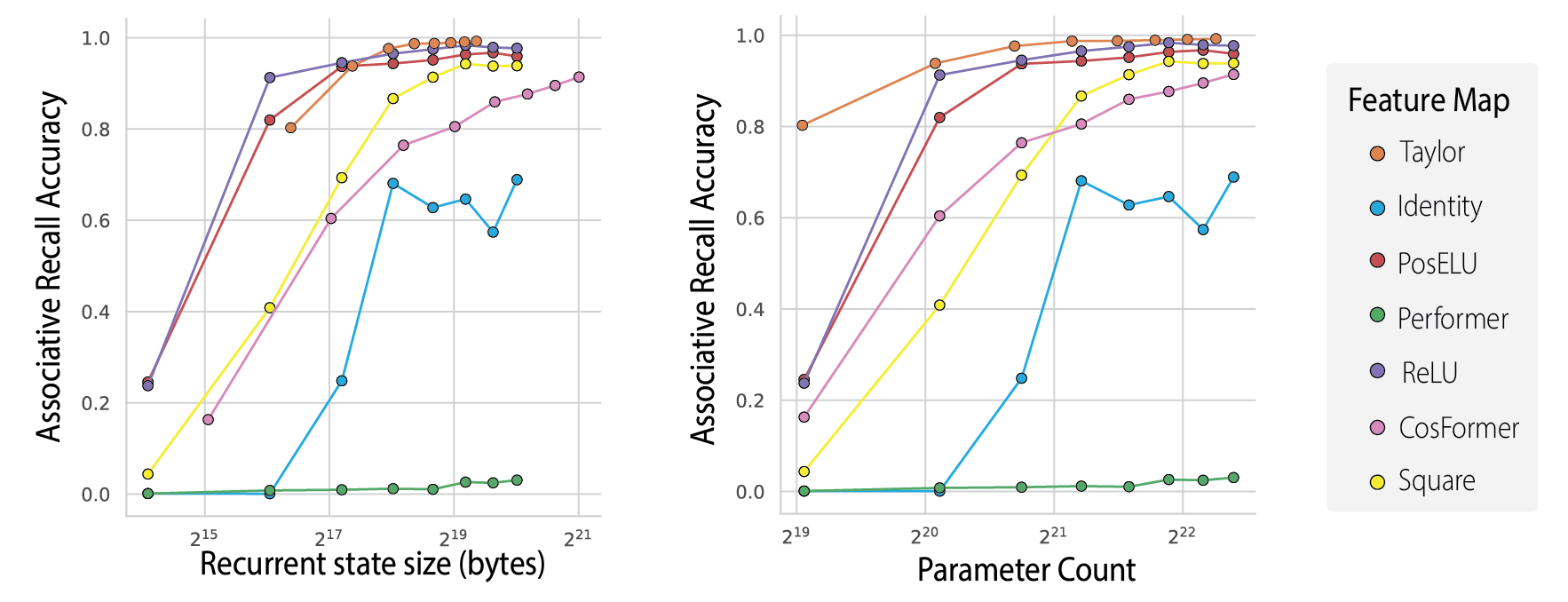
How much does our choice of featurization vs. the expanded state size matter when leading to the quality of Based? The model’s ability to use the state effectively is key. Shown in the accuracy vs. recurrent state size tradeoff curves, several alternatives to the Taylor map fall below the pareto frontier. Below we compare to models that expand the state size using learned projections and then apply popular feature maps (Performer, CosFormer, PosELU) from the literature. We train these models on the MQAR synthetic test for associative recall and sweep hyperparameters (learning rate) for all points shown in the plot below, finding that the Taylor map is most effective. This trend carries to real world experiments on the Pile language modeling corpus (see our paper for more).
IO and dataflow-aware implementation.
The next key question is how to make Based competitive in wall clock efficiency. Linear attention is theoretically more efficient than standard attention as a function of sequence length. However, existing implementations of linear attention methods are often slower than well-optimized attention implementations like FlashAttention.
In Based, we use the 2nd degree Taylor approximation, which expands the dimension of the keys, leading to large state sizes and large memory consumption , in sequence length , key dimension , and value dimension (discussed above). The large resulting key-value state makes naïve implementations of Taylor linear attention quite slow.
First let’s revisit a bit of context on how the hardware works. GPUs have small amounts of fast-to-access memory (thread-specific registers, shared memory at the warp/32-threads level using SRAM) and large amounts of slow-to-access memory (HBM). It is important to reduce the number of reads-and-writes between slow HBM and SRAM as well as SRAM and registers to unlock efficiency. We present new IO-aware algorithms for the Taylor linear attention forward pass and inference that reduce the HBM to SRAM data movement by bytes and the SRAM to register data movement by bytes. Our algorithm allows holding the KV state in-thread-register at feature dimension = 16, which we use in experiments.
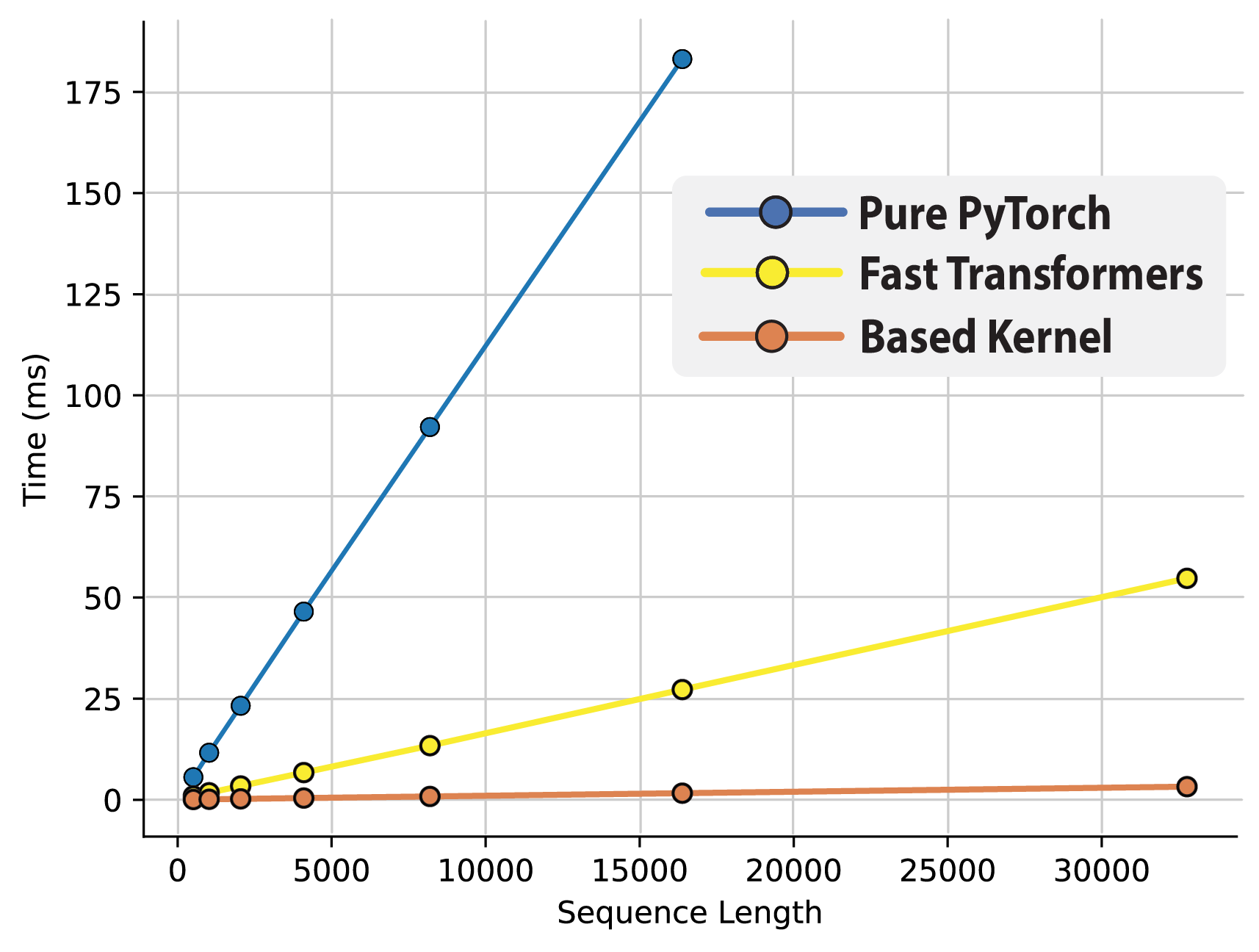
Below we include a comparison between the naive Taylor attention forward pass, an implementation that leverages the popular linear attention kernels from Fast Transformers, and our custom kernels are shown below across batch size (sequence length 1024).
We then compare the end-to-end generation speeds of FlashAttention-2, Mamba, and Based 360M and 1.3Bn parameter models using our IO-aware algorithms. We hold the batch size to 2 for prefill, and generate 1024 tokens for next token prediction. Strikingly, Based achieves up to 24x higher throughput than FlashAttention-2!
Stay tuned! These algorithms are implemented in an exciting new CUDA DSL called ThunderKittens, that’s being developed by our lab. Stay tuned for more on this soon – we hope the DSL improves the accessibility of CUDA development! In contrast to frameworks like Triton, which makes opinionated decisions about the supported scope of operations the user can perform, our DSL is embedded in C++. We’re really excited to share it and get your feedback! We’re cooking up more model artifacts alongside in the coming weeks, motivated by the question: What models does the hardware want?
You can play with our checkpoints and evaluations on Hugging Face and in this code repository: https://github.com/HazyResearch/based! Huge thank you to Together AI, Stanford HAI, and Stanford CRFM for supporting this work! Please send your feedback and questions to: Simran (simarora@stanford.edu), Sabri (eyuboglu@stanford.edu), and Michael (mzhang@cs.stanford.edu).