Full team: Michael, Simran, Rahul, Alan, Ben, Aaryan, Krithik, and Chris Ré.

In addition to making models go fast, we’re excited about creating fast models faster. And so in this first part of a two-post release, we’re happy to share LoLCATs (Low-rank Linear Conversion via Attention Transfer), a new approach for quickly creating subquadratic LLMs from existing Transformers.
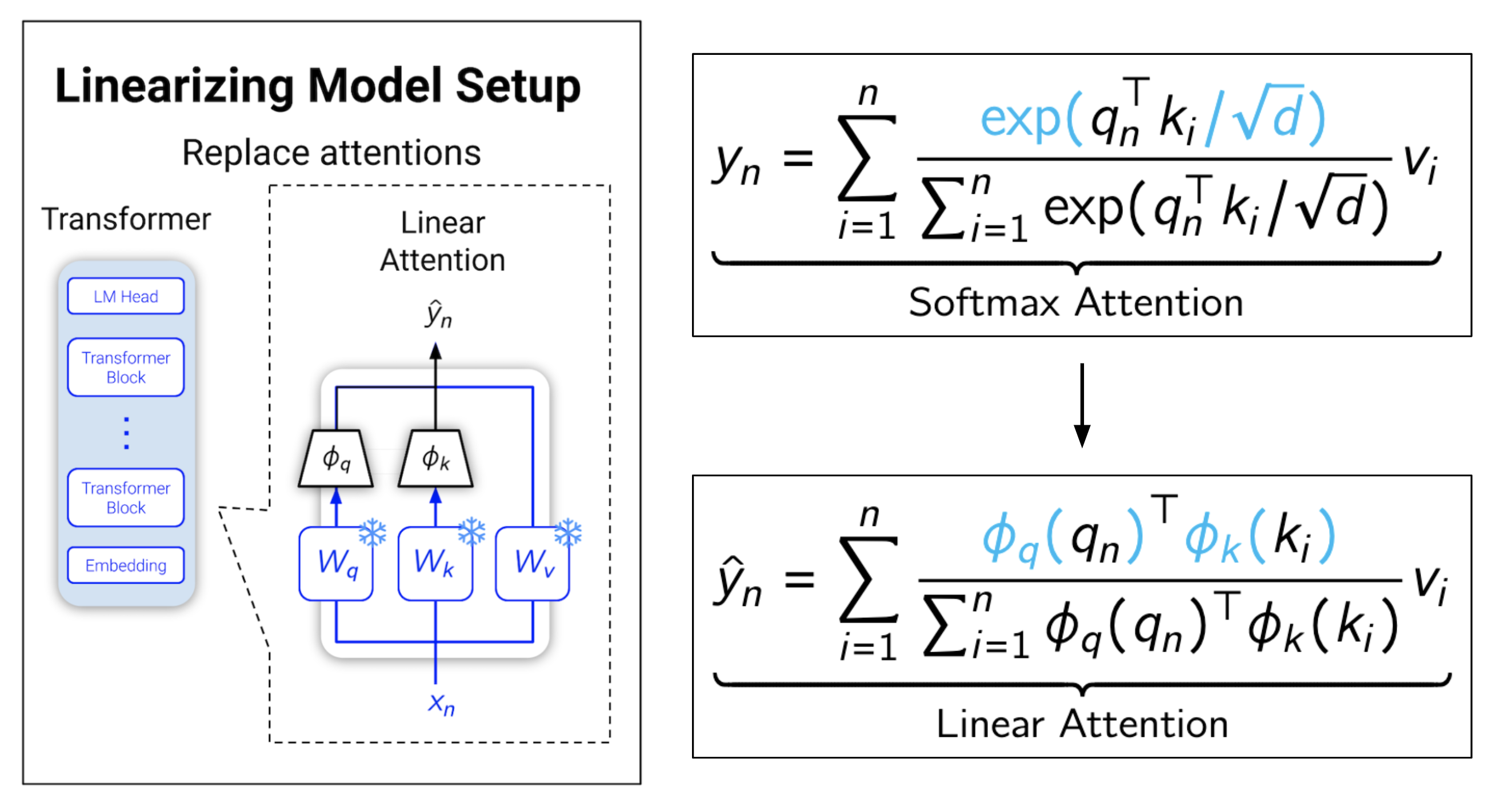
Rather than invent and pretrain new architectures from scratch, LoLCATs builds on a recent playbook 12345 that simply (1) swaps out softmax attentions for efficient alternatives (e.g., linear attentions), before (2) further training the model to recover from this layer swapping. This "linearizing" lets us bring the joys of linear-time and constant-memory generation to powerful and popular open-source LLMs (cheaper test-time compute, more reasoning for all!).
However, we developed LoLCATs to make linearizing even more painless and quality-preserving. As our own test, LoLCATS let us create linear versions of the complete Llama 3.1 family (8B, 70B, and 405B) for the first time, doing so no less on the same budget of a parameter-efficient finetune.
To do so, we found that we could do two simple things:
-
Make swapping more seamless: replacing softmax attentions with linear attentions trained to approximate their softmax counterparts ("attention transfer").
-
Make recovery cheaper: avoiding full model training after swapping, and recovering quality by only adjusting with parameter-efficient finetuning (e.g., low-rank adaptation).

With this release, we’re sharing our paper, code, and reference checkpoints, so you can linearize your own LLMs too!

Left: Rather than try to design expressive linear attentions, we simply learn them! Right: With minimal training (just LoRA!), this lets us recover LLM yapping abilities.
In Part 2, we'll go deeper into some details and results of LoLCATs. But for some quick highlights, LoLCATs lets us:
-
Achieve state-of-the-art linearized quality: improving the zero-shot accuracy of linearizing popular 7B and 8B LLMs (Mistral 7B, Llama 3 8B) by 6.7 to 8.8 points on average over standard LM Eval zero-shot tasks (20+ points on 5-shot MMLU), while also outperforming strong subquadratic models pretrained from scratch (like Mamba 7B, RWKV-6 World, TransNormer 7B, Hawk 7B, Griffin 7B, and StripedHyena-7B). LoLCATs LLMs further matched original Transformer-based LLMs on zero-shot LM Eval tasks.
-
Drastically reduce linearizing costs: getting this quality by training under 0.2% of the parameters in prior linearizing methods, while using only 40 million training tokens. This amounts to a 2,500x improvement in tokens-to-model efficiency versus prior linearizing methods, and a 35,000x improvement versus pretraining strong 7B subquadratic models from scratch).
-
Scale up linearizing to 70B and 405B LLMs: using these advances to linearize the complete Llama 3.1 family (8B, 70B, and 405B). We created the first linearized 70B and 405B LLMs, and all on "academic compute" (Llama 3.1 405B took less GPU hours than recent methods used for 50x smaller 8B LLMs).
For even more details, please check out our paper, along with the LoLCATs method repo and some sample checkpoints. While we started with simple linear attentions, we hope that our findings + code can help you linearize your Llamas, Mistrals, Gemmas or whatevers into the architectures of your hearts’ desires.

- Paper: (arXiv)
- Method + Training Repo: https://github.com/HazyResearch/lolcats
- Checkpoints: (Hugging Face Collection)
- Part 2: link
- Finetuning Pretrained Transformers into RNNs https://arxiv.org/abs/2103.13076↩
- The Hedgehog & the Porcupine: Expressive Linear Attentions with Softmax Mimicry https://arxiv.org/abs/2402.04347↩
- Linearizing Large Language Models https://arxiv.org/abs/2405.06640↩
- Transformers to SSMs: Distilling Quadratic Knowledge to Subquadratic Models https://arxiv.org/abs/2408.10189↩
- The Mamba in the Llama: Distilling and Accelerating Hybrid Models https://arxiv.org/abs/2408.15237↩