Oct 29, 2024 · 11 min read
Easier, Better, Faster, Cuter
Benjamin Spector, Simran Arora, Aaryan Singhal, Daniel Y. Fu, Chris Ré
Paper | Code | TK Part 1 | Brr
Fiveish months ago, we put out our posts on ThunderKittens and GPUs, and were pleasantly surprised by their warm reception on The Platform Formerly Known as Twitter.
We now return in a continuation of our long-standing efforts to throw compute to the wolves. We offer you, dearest reader, several new and improved gifts:
- Lots of new, exciting kernels;
- Talking models;
- Extra adorable kittens;
- Attention kernels: faster and more flexible;
- Us!
And purrfect medieval kitten masterpieces throughput!

Moar Architectures
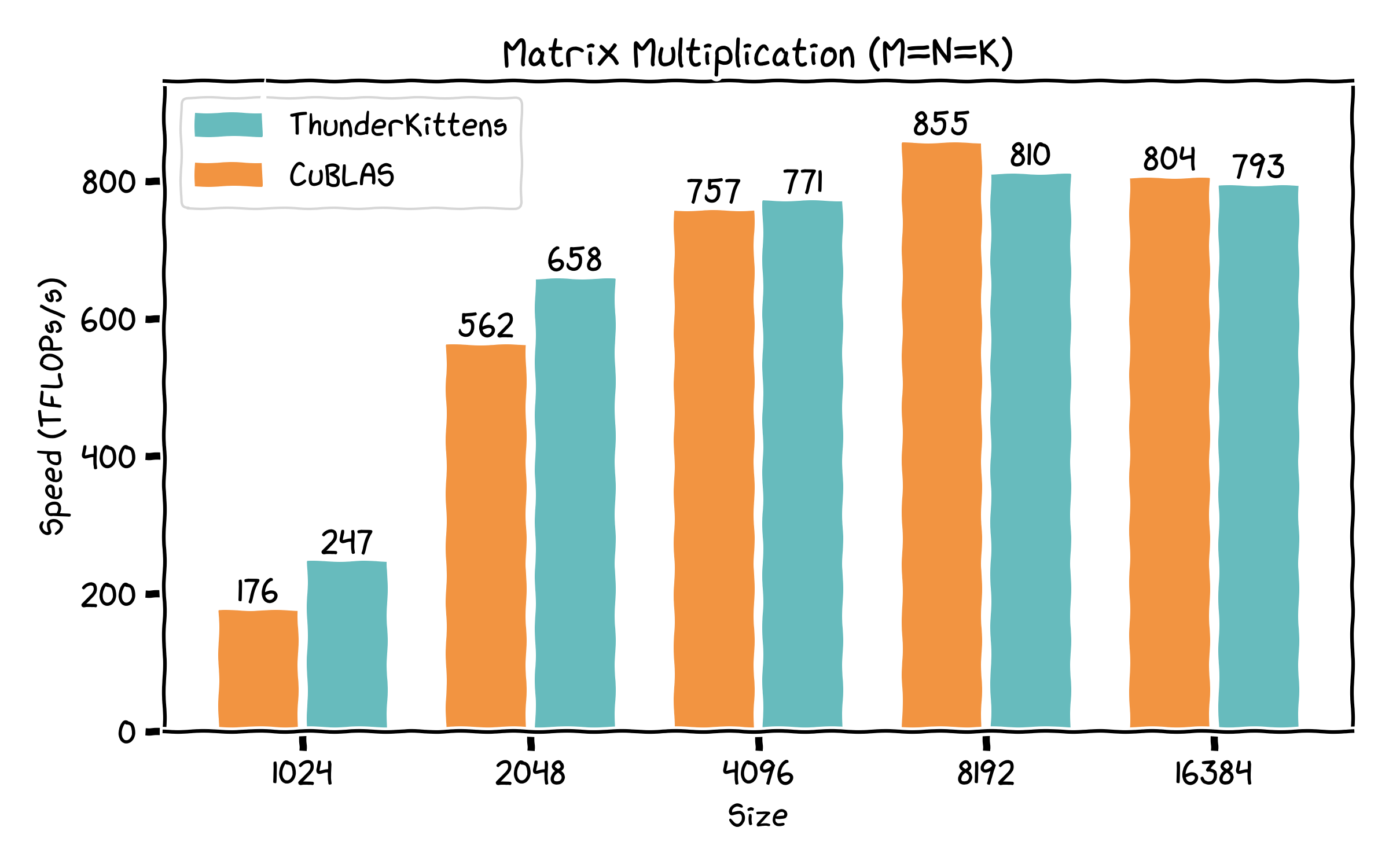
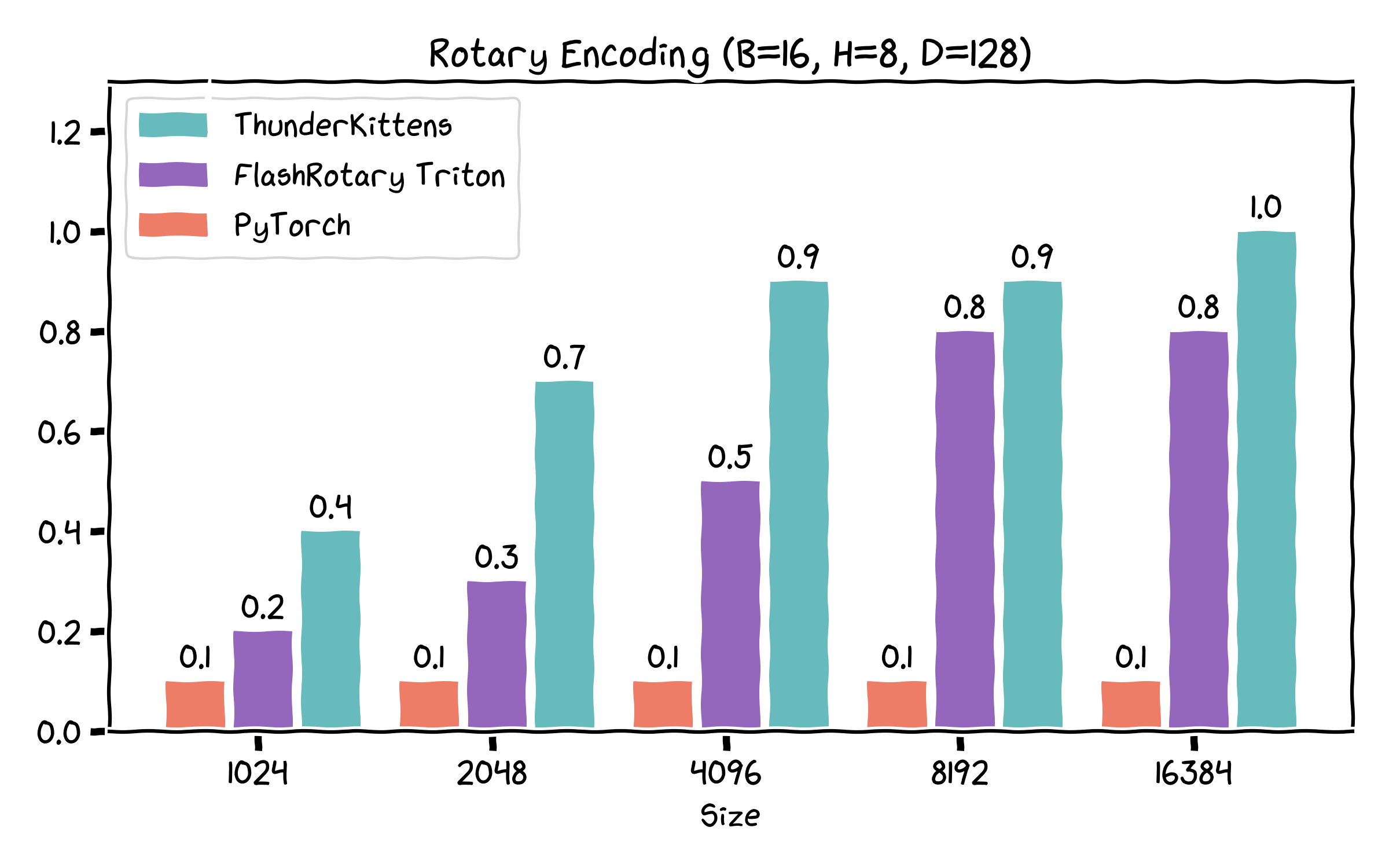
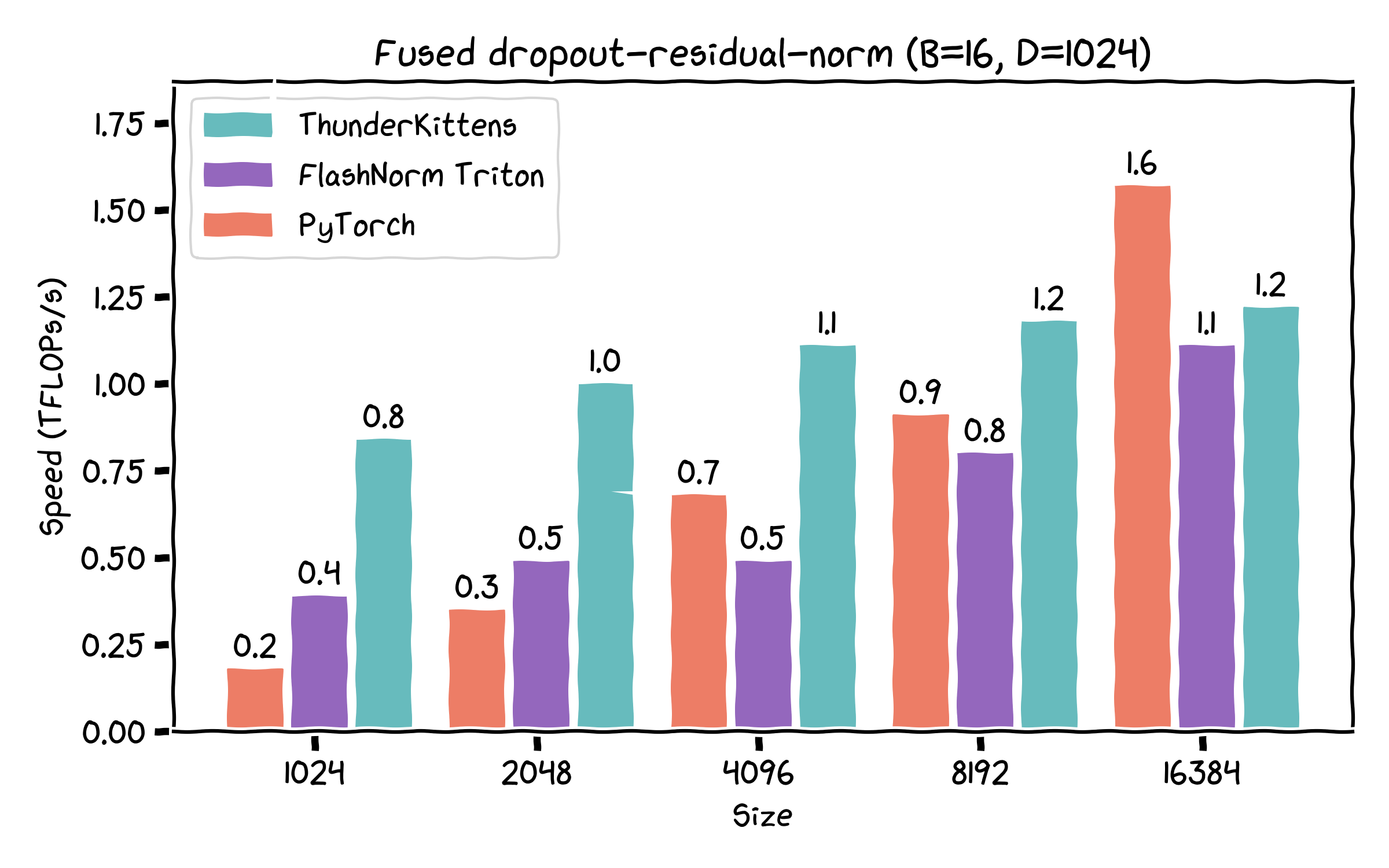
The main raison d’etre for TK has always been to help us write kernels for -- and do research on -- new architectures. Correspondingly, we’re releasing a bunch of kernels for various new operations (and some old ones, too); these range from “a bit” to “much” faster than comparable implementations.
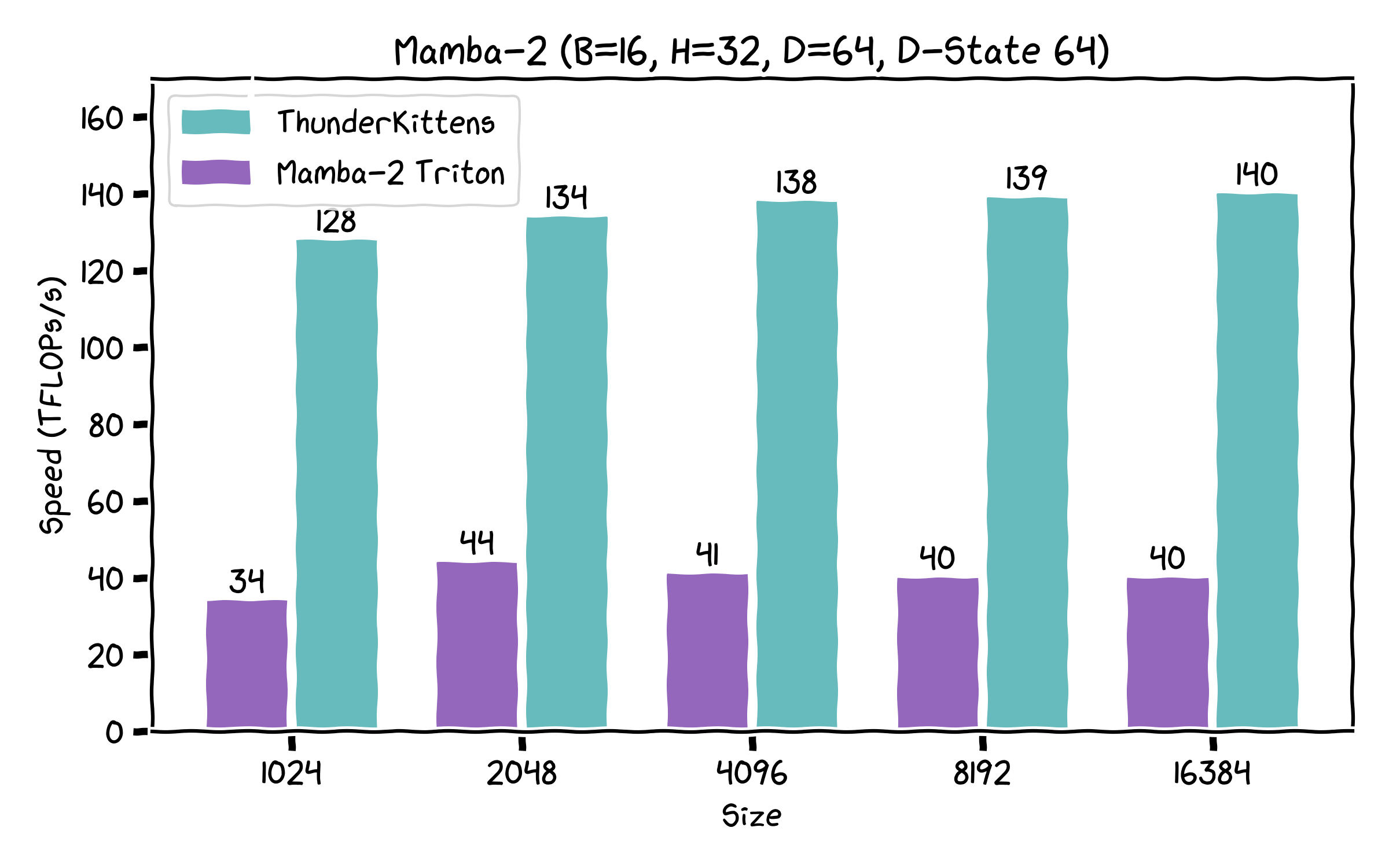
- Fused Mamba-2, several times faster than the current Triton implementation, mostly through more aggressive kernel fusions. (Note it uses a slightly different layout than the normal Triton implementation, but it might be handy.)

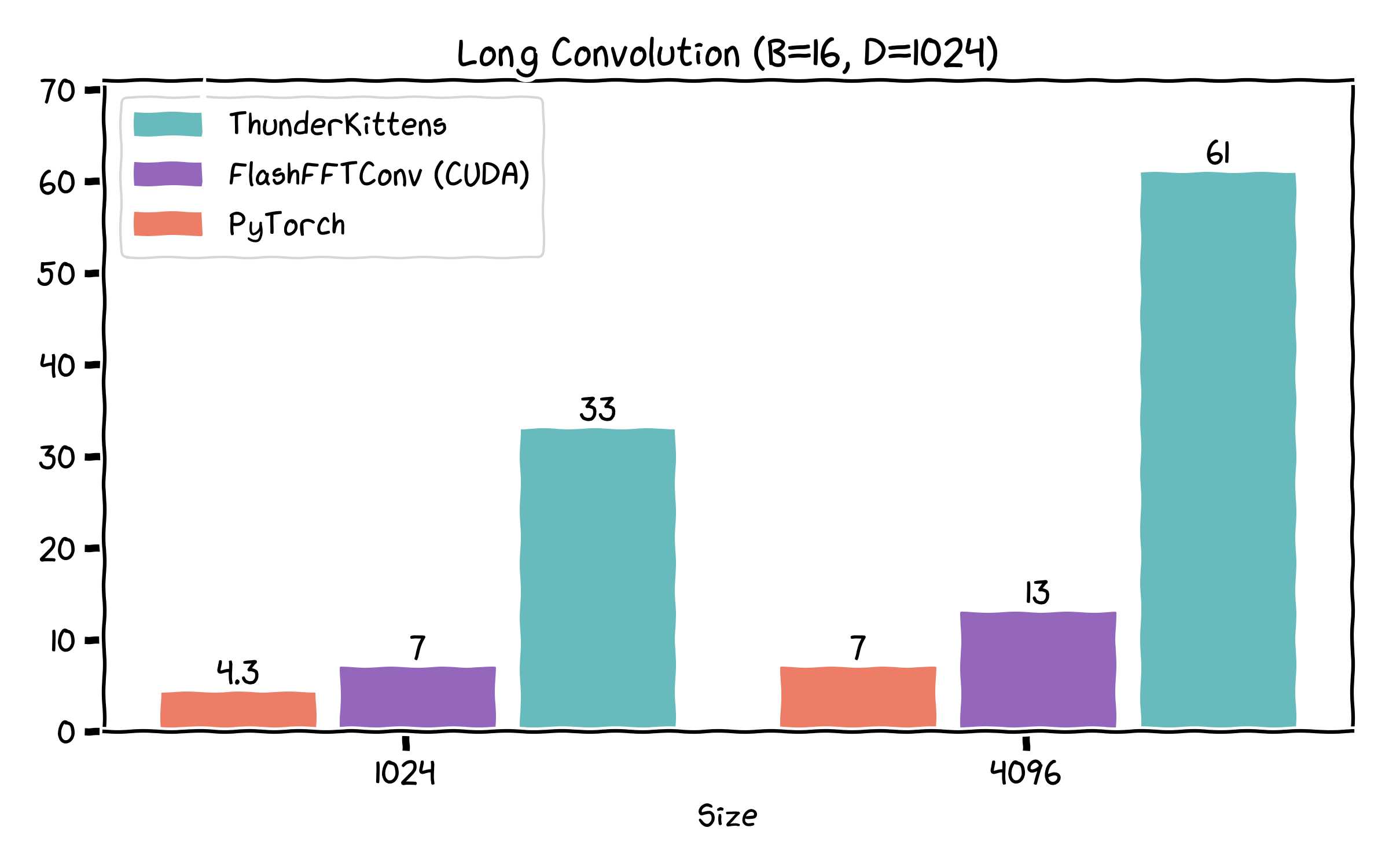
- Long convolutions -- at sequence length 4096, we can get up to ~9x over the FlashFFTConv implementation!

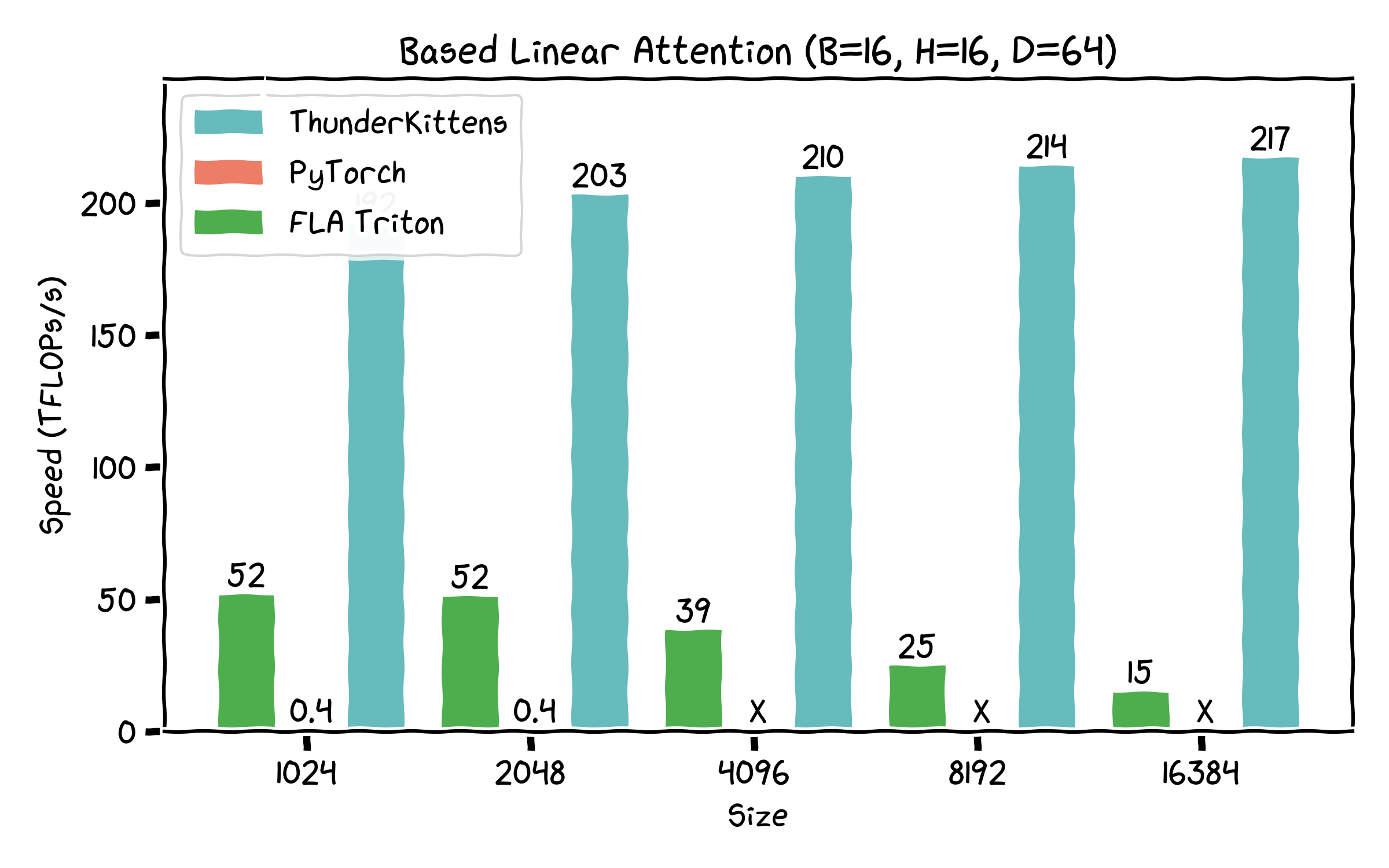
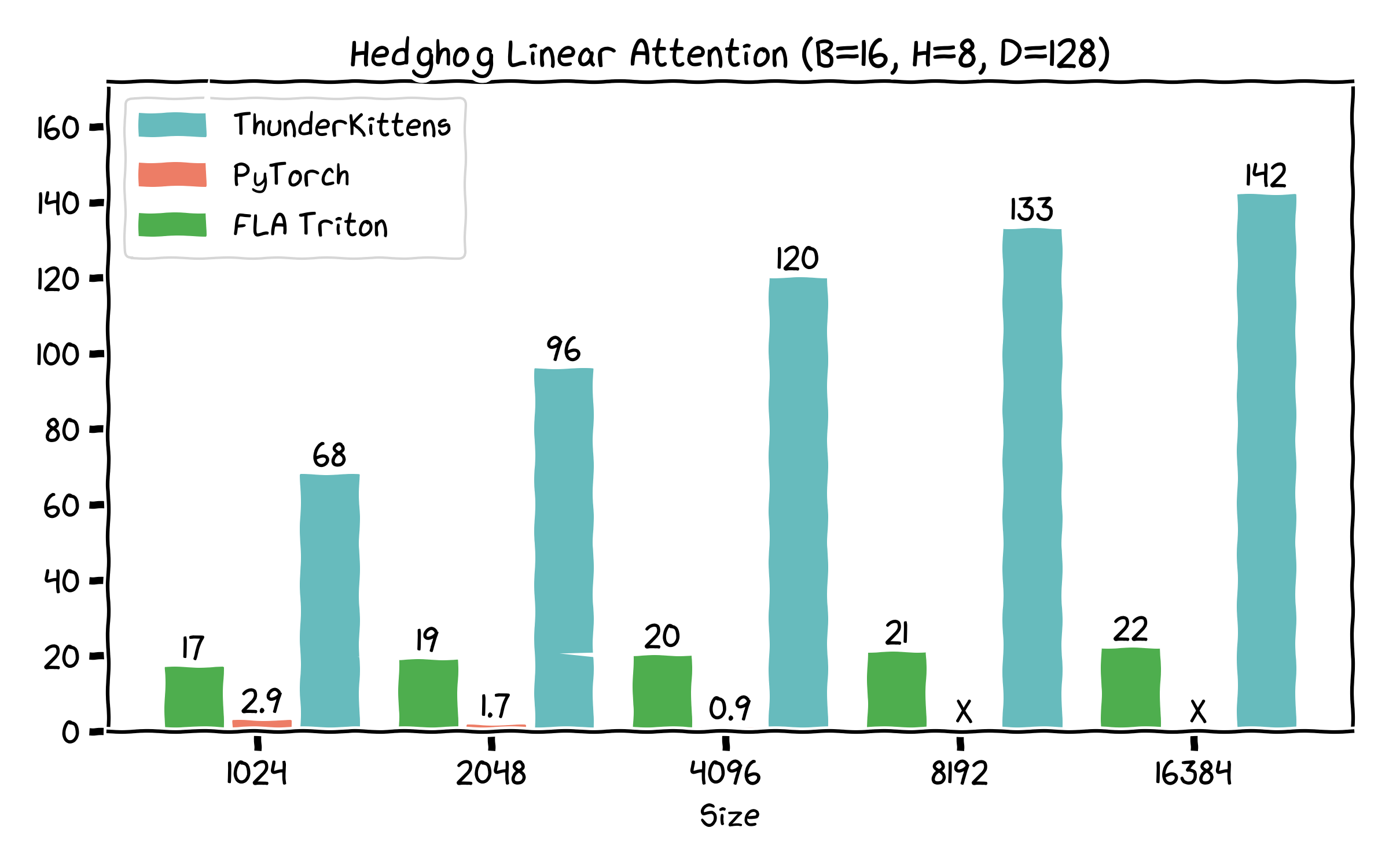
- Linear attentions – Based and LoLCATS Hedgehog linear attention 14x and 6.5x faster than Fast Linear Attention Triton implementations, by being careful about register usage and using H100 features.

- Rope, LayerNorm, Linear layers -- each competitive with (or sometimes faster than) existing implementations, while being pretty concise and readable.

Meow meow meow. Meow meow meow MEOW!
Talking kittens are the best kittens. We’ve pushed a couple of demo integrations to help your kittens talk to you, and even to teach them a thing or two!
- Attention -- TK kernels support Llama3 8B and Qwen 2.5 7B. We’ve integrated some demo scripts, to make running these models as easy as
cd demos/llama_demo && bash demo_8b.sh. We’ve added example training integrations with both nanoGPT and PyTorch Lightning, and conducted several successful training runs. - Following up on our recent LoLCATs work, we’ve included a forwards prefill kernel and a demo integration -- just run
cd demos/lolcats_demo && bash demo_8b.sh. - Based is a linear attention architecture that combines short sliding window attentions with large-state-size linear attentions. To use TK’s prefill kernel (optimized for high-throughput scenarios), there are several example scripts in
demos/based_demo.
Enhanced Kittens
Finally, we’re excited to release our first major batch of improvements to ThunderKittens to take it from, “seems cool,” (0.0) to, “actually useful” (0.01). In no particular order. ThunderKittens really is now easier, better, faster, and most importantly, cuter!
- A proper build system. Just
python setup.py installand use prebuilt ThunderKittens kernels in your code! - No more shared layouts. We’ll automatically arrange and swizzle your shared memory tiles for you; just tell us how big.
- This also comes with a pretty significant performance boost, because we finally figured out how to get rid of the stupid interleave format, reduce bank conflicts, and improve L2 transaction coalescing.
- Global layout descriptors, so that you can just pretend everything is a tensor like it is in Pytorch. No more stride calculations! And significantly reduced padding requirements, too.
- Broader type support, including (serious, not-hacked) global and shared FP16 and FP32 support. FP8... eventually.
- Many more robust tests. Tens of thousands!
- Templates to handle much of the boilerplate setup and coordination of barriers. Just write load, compute, and store functions! Here’s an example non-causal attention kernel within this framework, which is a good deal faster than the ones we released in May, and pretty much matches FA-3.
#include "kittens.cuh"
#include "prototype.cuh"
using namespace kittens;
using namespace kittens::prototype;
using namespace kittens::prototype::lcf;
template<int D, int NUM_WORKERS> struct attn_fwd_layout {
using qo_tile = st_bf<64, D>;
using kv_tile = st_bf<D==64?192:128, D>;
using qo_global = kittens::gl<bf16, -1, -1, -1, D, qo_tile>;
using kv_global = kittens::gl<bf16, -1, -1, -1, D, kv_tile>;
struct globals { qo_global O, Q; kv_global K, V; };
struct input_block { kv_tile k, v; };
struct scratch_block { qo_tile q[NUM_WORKERS]; };
struct common_state { int batch, head, seq; };
struct consumer_state {
rt_fl<16, qo_tile::cols> o_reg;
col_vec<rt_fl<16, kv_tile::rows>> max_vec, norm_vec;
col_vec<rt_fl<16, kv_tile::rows>> max_vec_last_scaled, max_vec_scaled;
rt_fl<16, kv_tile::rows> att_block;
rt_bf<16, kv_tile::rows> att_block_mma;
};
};
template<int D> struct attn_fwd_template {
static constexpr int NUM_CONSUMER_WARPS = 12, NUM_WORKERS = NUM_CONSUMER_WARPS/4, INPUT_PIPE_STAGES = 2;
using layout = attn_fwd_layout<D, NUM_WORKERS>;
__device__ static inline void common_setup(common_setup_args<layout> args) {
args.common.batch = blockIdx.z; args.common.head = blockIdx.y; args.common.seq = blockIdx.x;
args.num_iters = args.task_iter == 0 ? args.globals.K.rows/layout::kv_tile::rows : -1;
}
struct producer {
__device__ static inline void setup(producer_setup_args<layout> args) {
warpgroup::producer_registers();
}
__device__ static inline void load(producer_load_args<layout> args) {
if(warpgroup::warpid() == 0) {
tma::expect(args.inputs_arrived, args.input);
tma::load_async(args.input.k, args.globals.K, {args.common.batch, args.common.head, args.iter, 0}, args.inputs_arrived);
tma::load_async(args.input.v, args.globals.V, {args.common.batch, args.common.head, args.iter, 0}, args.inputs_arrived);
}
else if(laneid() == 0) arrive(args.inputs_arrived);
}
};
struct consumer {
__device__ static inline void setup(consumer_setup_args<layout> args) {
warpgroup::consumer_registers<NUM_WORKERS>();
if((args.common.seq*NUM_WORKERS + warpgroup::groupid())*layout::qo_tile::rows < args.globals.Q.rows) // out of bounds?
warpgroup::load(args.scratch.q[warpgroup::groupid()], args.globals.Q,
{args.common.batch, args.common.head, args.common.seq*NUM_WORKERS+warpgroup::groupid(), 0});
zero(args.state.o_reg);
zero(args.state.norm_vec);
neg_infty(args.state.max_vec);
warpgroup::sync(warpgroup::groupid());
}
__device__ static inline void compute(consumer_compute_args<layout> args) {
constexpr float TEMPERATURE_SCALE = (D == 128) ? 0.08838834764f*1.44269504089f : 0.125f*1.44269504089f;
// A = Q @ K.T
warpgroup::mm_ABt(args.state.att_block, args.scratch.q[warpgroup::groupid()], args.input.k);
mul(args.state.max_vec_last_scaled, args.state.max_vec, TEMPERATURE_SCALE);
warpgroup::mma_async_wait();
// softmax
row_max(args.state.max_vec, args.state.att_block, args.state.max_vec); // accumulate onto the max_vec
mul(args.state.max_vec_scaled, args.state.max_vec, TEMPERATURE_SCALE);
mul(args.state.att_block, args.state.att_block, TEMPERATURE_SCALE);
sub_row(args.state.att_block, args.state.att_block, args.state.max_vec_scaled);
exp2(args.state.att_block, args.state.att_block);
sub(args.state.max_vec_last_scaled, args.state.max_vec_last_scaled, args.state.max_vec_scaled);
exp2(args.state.max_vec_last_scaled, args.state.max_vec_last_scaled);
mul(args.state.norm_vec, args.state.norm_vec, args.state.max_vec_last_scaled);
row_sum(args.state.norm_vec, args.state.att_block, args.state.norm_vec); // accumulate onto the norm_vec
mul_row(args.state.o_reg, args.state.o_reg, args.state.max_vec_last_scaled); // normalize o_reg before mma
copy(args.state.att_block_mma, args.state.att_block); // convert to bf16 for mma
// O += A @ V
warpgroup::mma_AB(args.state.o_reg, args.state.att_block_mma, args.input.v);
warpgroup::mma_async_wait();
if(laneid() == 0) arrive(args.inputs_finished); // done!
}
__device__ static inline void finish(consumer_finish_args<layout> args) {
if((args.common.seq*NUM_WORKERS+warpgroup::groupid())*64 >= args.globals.Q.rows) return; // out of bounds?
div_row(args.state.o_reg, args.state.o_reg, args.state.norm_vec);
auto &o_smem = reinterpret_cast<typename layout::qo_tile&>(args.scratch.q[warpgroup::groupid()]);
warpgroup::store(o_smem, args.state.o_reg);
warpgroup::sync(warpgroup::groupid());
if(warpgroup::warpid() == 0)
tma::store_async(args.globals.O, o_smem, {args.common.batch, args.common.head, args.common.seq*NUM_WORKERS+warpgroup::groupid(), 0});
}
};
};
// kernel is kittens::prototype::lcf::kernel<attn_fwd_template<HEAD_DIM>>;
For more on these demos -- an an FA2 demo, too -- take a look here.
We’re particularly excited about ThunderKittens because, in addition to enabling fast and diverse kernels, ThunderKittens remains quite transparent to the underlying hardware. We want you to actually know what your code is really doing!
All Your Attention Are Belong to Us
We were excited to see Tri&team release FA3 a few months ago. We had a lot of fun taking apart the kernel and learned a few tricks! Correspondingly, we’re releasing a swath of kernels for attention, including some that exceed FA3’s performance -- especially on the backwards pass!
A surprising result we found is that very little of the speedup found in FA-3 comes from the complex ping-ponging algorithm overlapping matrix multiplies and non-tensor ops. Instead, almost all of it comes from just using the GPU better! It’s really all standard things, like being careful with the register file, minimizing memory movement, etc. Consequently, our current implementation actually skips most of the complexity found in FA-3 -- but it still retains most of the performance on the forwards pass, and is noticeably faster on the backwards.
Our kernels are prebuilt, so that if you don't want to know how the sausage is made, you can still enjoy ThunderKittens. We support major open-source models (e.g. Llama’s, Qwen’s etc), with demo integrations in the repo. And if you want to add your favorite new feature, we’ve made it as easy as we know how. Here’s how ThunderKittens currently stacks up against FA3.
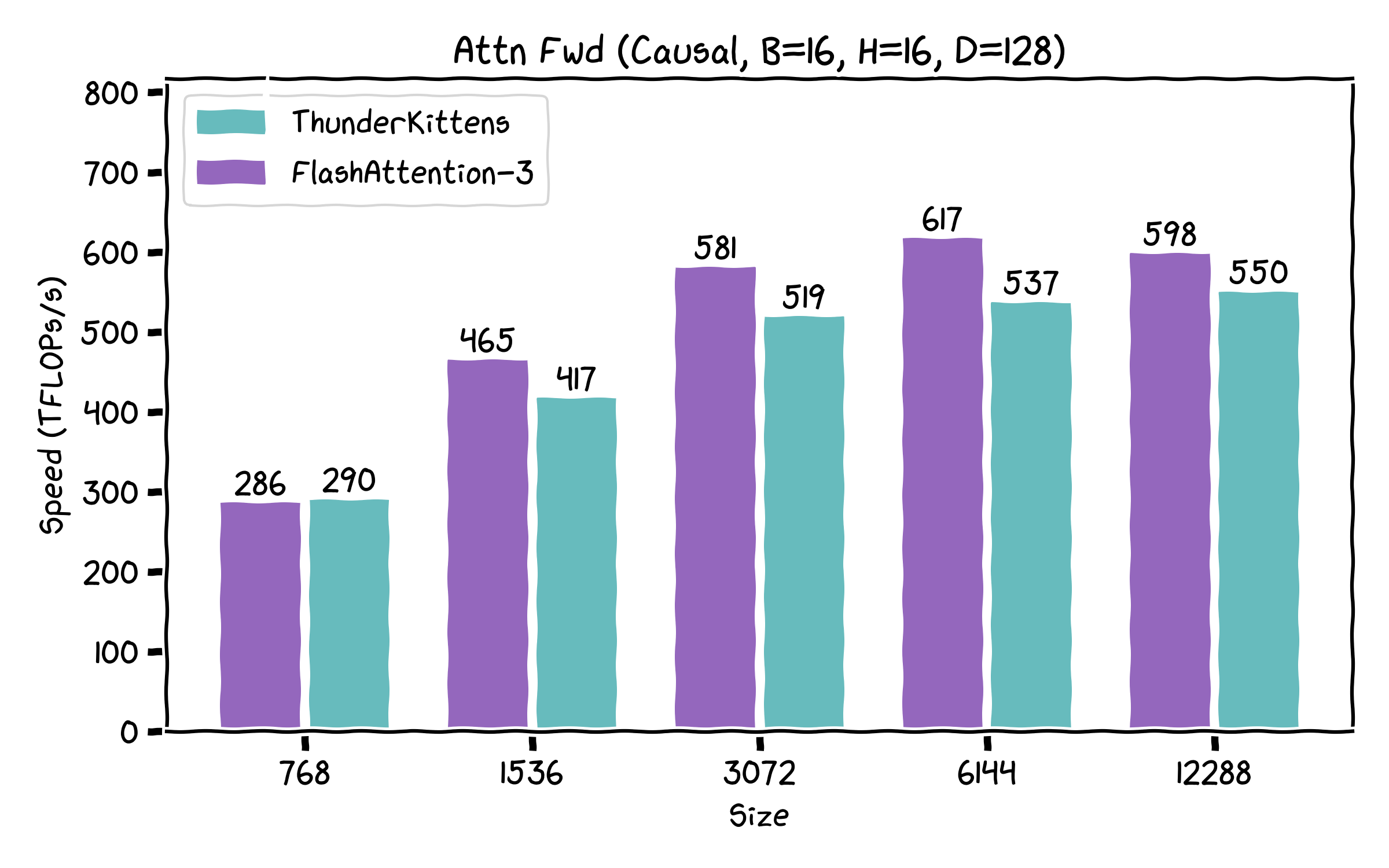
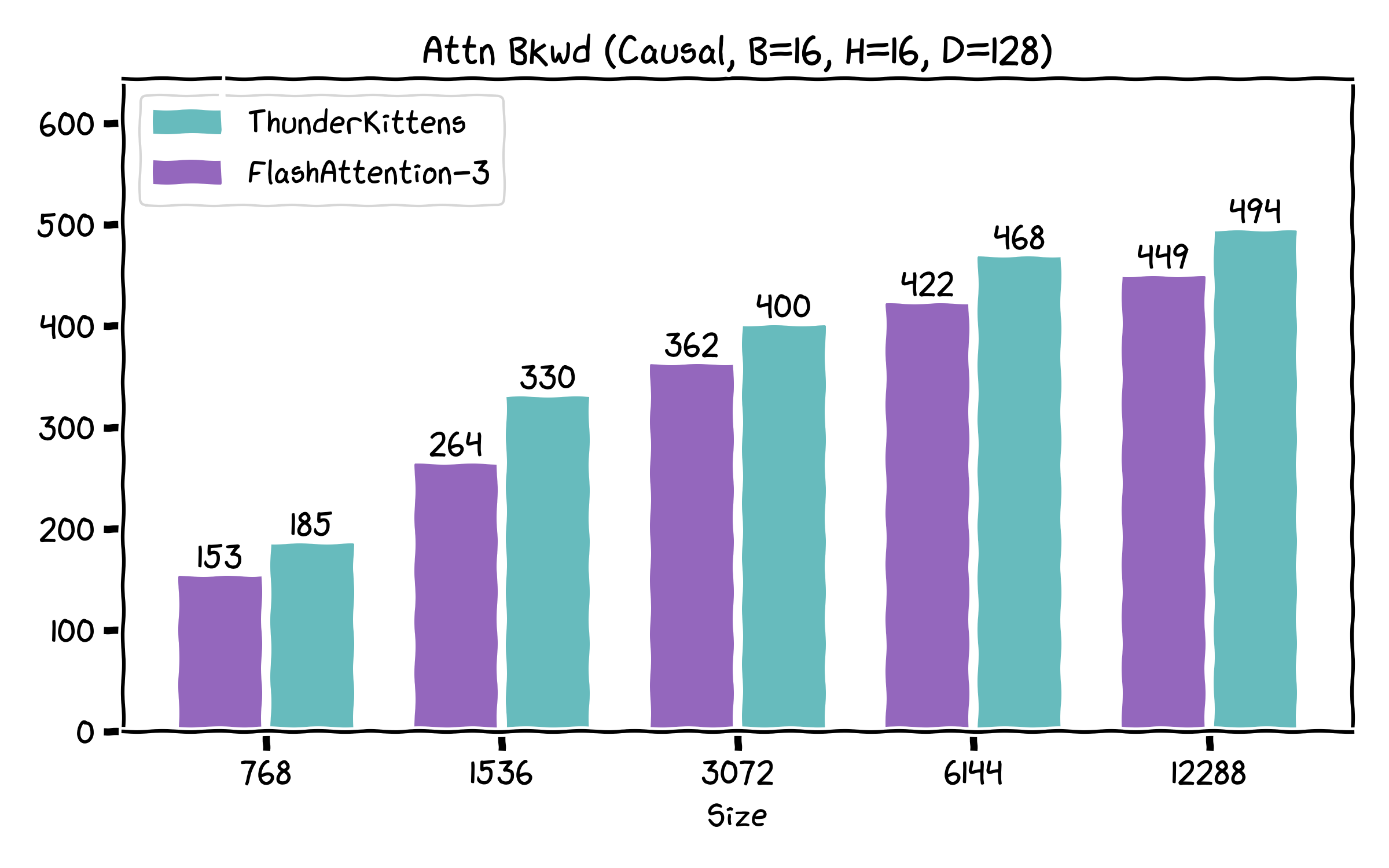
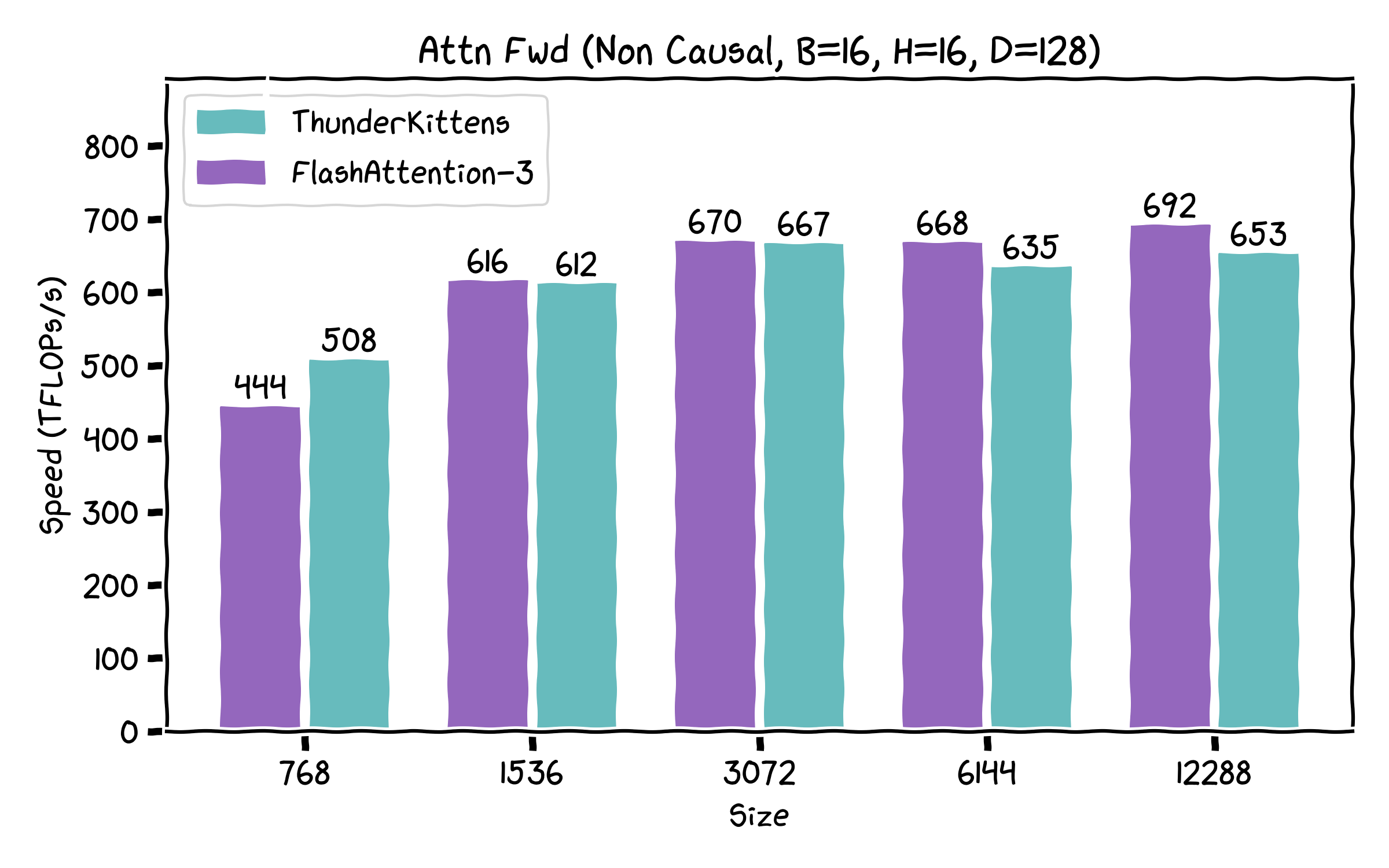
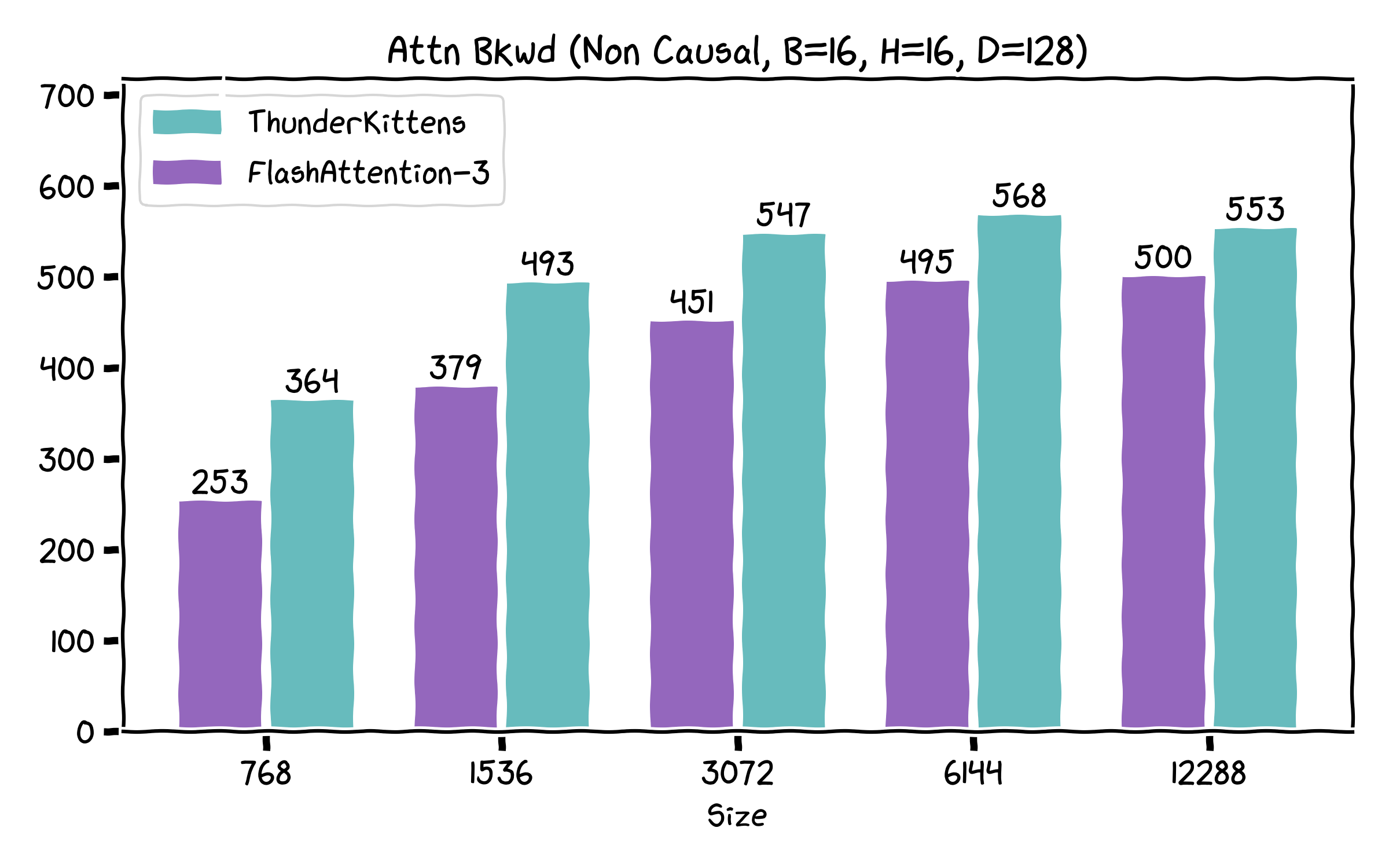

Us!
This coming Thursdsay (Oct 31) in celebration of Halloween, we’ll (Ben, Simran, and Aaryan) be doing a second livestream of ThunderKittens (previous one). Come hang out!
If you can’t make it, fear not: we’ll also be putting out a series of in-depth posts on more of our learnings about kernel optimization over the next few weeks, too. We'll also be on the GPU Mode discord, come hang out and write TK kernels with us!