Apr 19, 2022 · 11 min read
Improving Transfer and Robustness in Supervised Contrastive Learning
Mayee Chen, Dan Fu, Avanika Narayan, Michael Zhang, Zhao Song, Kayvon Fatahalian, and Chris Ré.
TL;DR: In this blog post, we take a look at how to learn a representation with good transfer and robustness properties using supervised contrastive learning. In short, we identify two key points: we need to ensure the right amount of “spread” in the geometry of the representation, and we need to break a particular invariance that naturally arises from analysis of the contrastive loss function. We present two modifications to supervised contrastive learning that result in significant improvements in transfer and robustness.
Overview
A major problem in modern machine learning is how to learn good representations. Ideally, we’d like representations with good transferability and robustness. In this blog post, we look at how to achieve these properties for supervised contrastive learning, which has demonstrated empirical success over traditional supervised methods.
We’ll start by discussing the geometry of supervised contrastive learning and why that geometry is suboptimal for transfer. Then we’ll go over two challenges with creating representations that have good transfer and robustness properties, present our method Thanos for addressing these challenges, and discuss some exciting directions about what’s next.
This is part two of a three part series on advances in understanding, improving, and applying contrastive learning.
- In part one, we looked at some background on contrastive learning and summarized some theoretical takes on how contrastive learning works.
- In part two (this blog), we build on those theoretical takes to look at how to improve the transfer and robustness of supervised contrastive learning.
- In part three, we’ll see how we can use our understanding of contrastive learning to improve the long-tailed performance of entity retrieval in NLP.
The Geometry of Supervised Contrastive Learning
In part one, we saw that supervised contrastive learning trains an encoder by pulling together the representations of points that come from the same class, and pushing apart points that come from different classes:
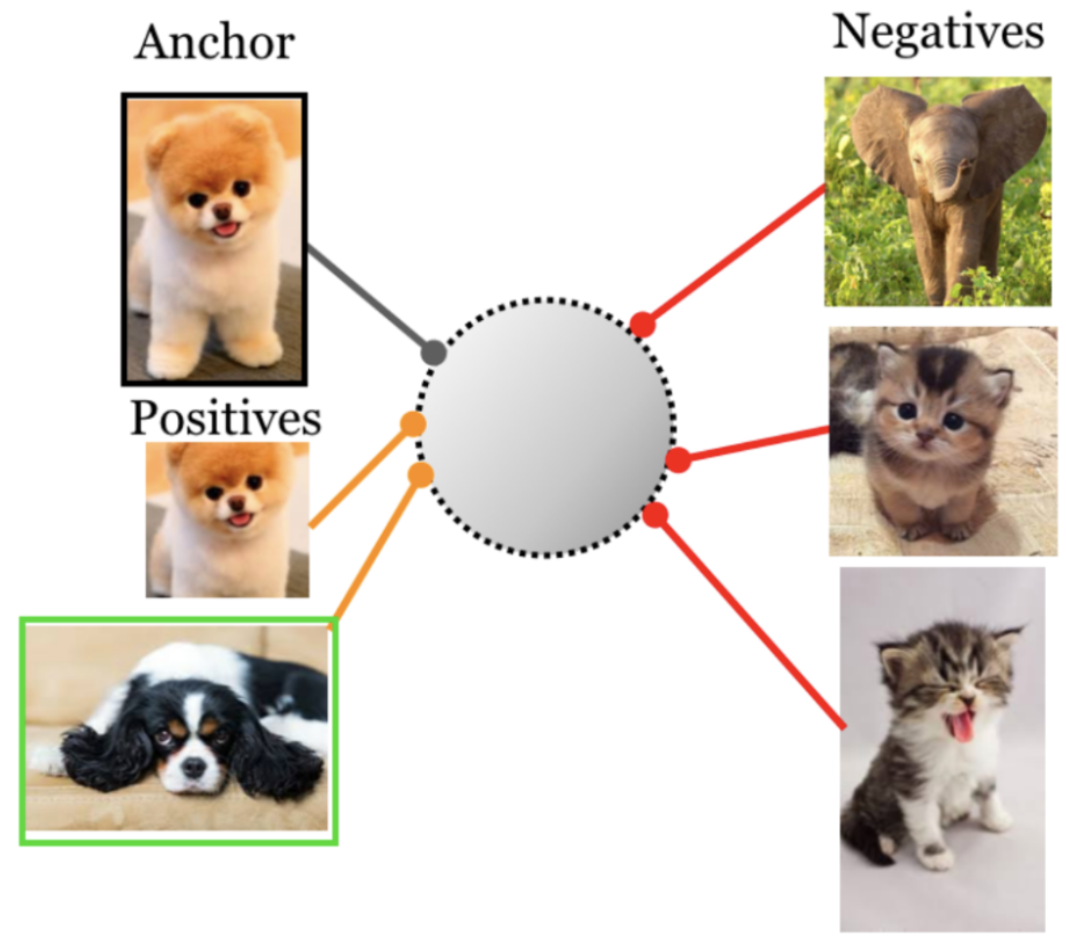
Figure 1. In supervised contrastive learning, the representations of points from the same class (e.g., of two dogs) are pulled together, while representations from different classes are pushed apart (e.g., dog and elephant). Source.
The recent SupCon paper showed that training models in this way (as opposed to approaches like cross entropy) results in significant improvements in accuracy:
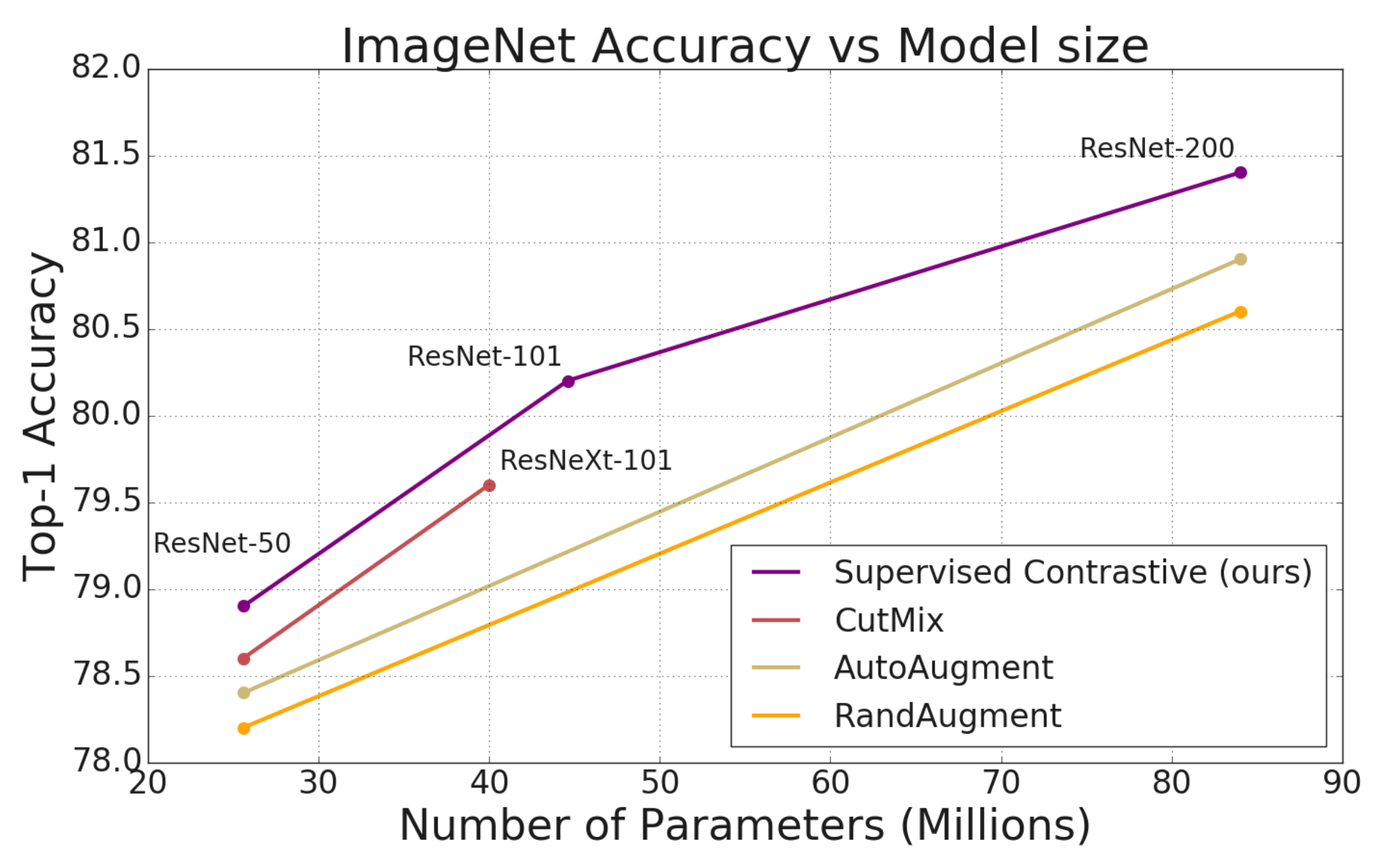
Figure 2. The SupCon paper showed that supervised contrastive learning can significantly outperform traditional methods of training, like cross entropy. Source.
In Dissecting Supervised Contrastive Learning, Graf et al. offered a geometric explanation for this performance. The supervised contrastive loss (SupCon loss) works so well because it is minimized when all the points in a single class map to a single class on the hypersphere:
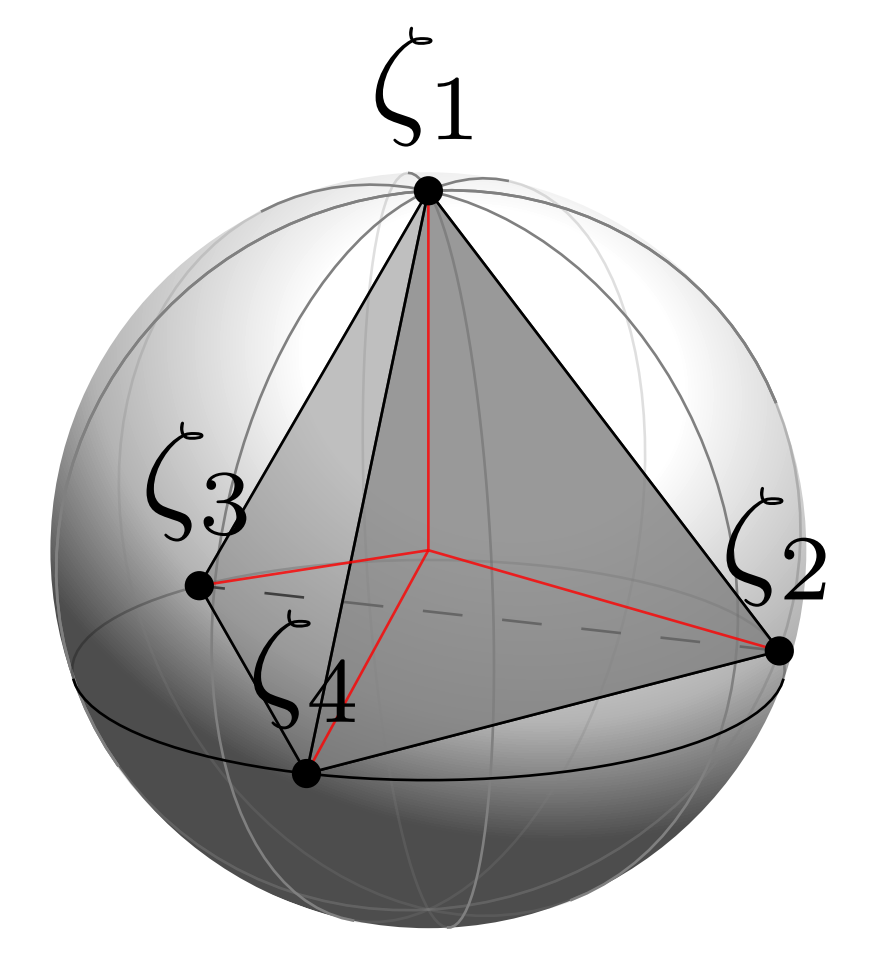
Figure 3. Graf et al. showed that the SupCon loss is minimized when all the points from the same class collapse to a single point, forming a regular simplex inscribed in the hypersphere (shown above for four classes). Source.
A geometry of class collapse makes it very easy to separate the original supervised task, but it turns out that it’s not great for downstream properties like transferability. In A Broad Study on the Transferability of Visual Representations with Contrastive Learning, Islam et al. reported the transfer learning performance of different variants of contrastive learning.
Islam et al. found that combining the SupCon loss with a self-supervised contrastive loss (InfoNCE) resulted in better transfer performance. And they found that one of qualitative differences between the original SupCon loss and this variant that combines a supervised and self-supervised loss was the degree of “geometric spread” in the embeddings:
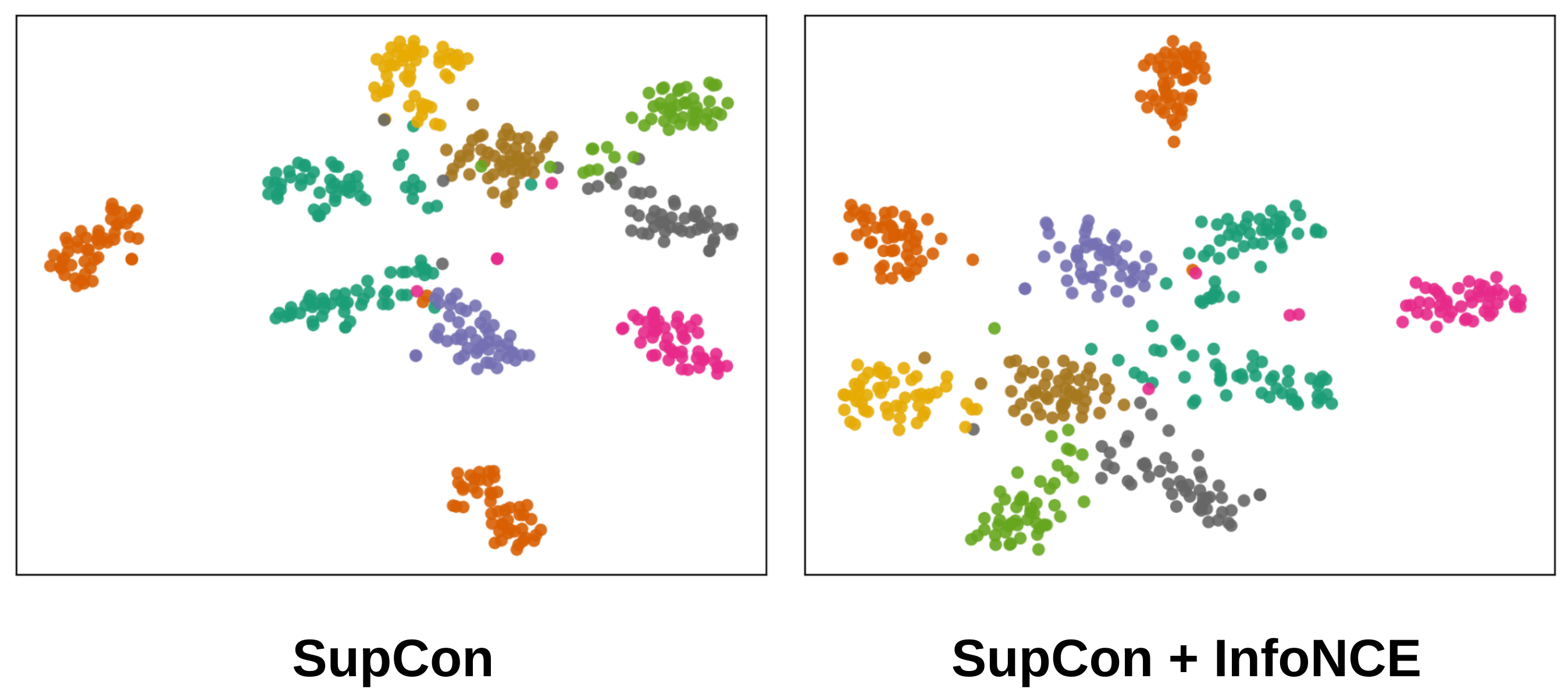
Figure 4. Islam et al found that adding a self-supervised InfoNCE loss to the SupCon loss resulted in better transfer – and a higher degree of geometric “spread” in the embeddings. Source.
This is a really interesting observation, but without much theoretical explanation at the time. In our paper, we wanted to build a theoretical understanding of this effect – why does adding a self-supervised contrastive loss to SupCon result in better transfer? And what does this geometric notion of spread have to do with it?
Two Key Challenges
We found that there are actually two key properties in learning representations that have good transfer: balancing the proper amount of spread in the geometry, and breaking a particular invariance that arises in contrastive loss.
In this section, we’ll discuss these two challenges, and talk about how we address them with a class-conditional InfoNCE loss and with a class-conditional autoencoder.
Challenge 1: Balancing Spread
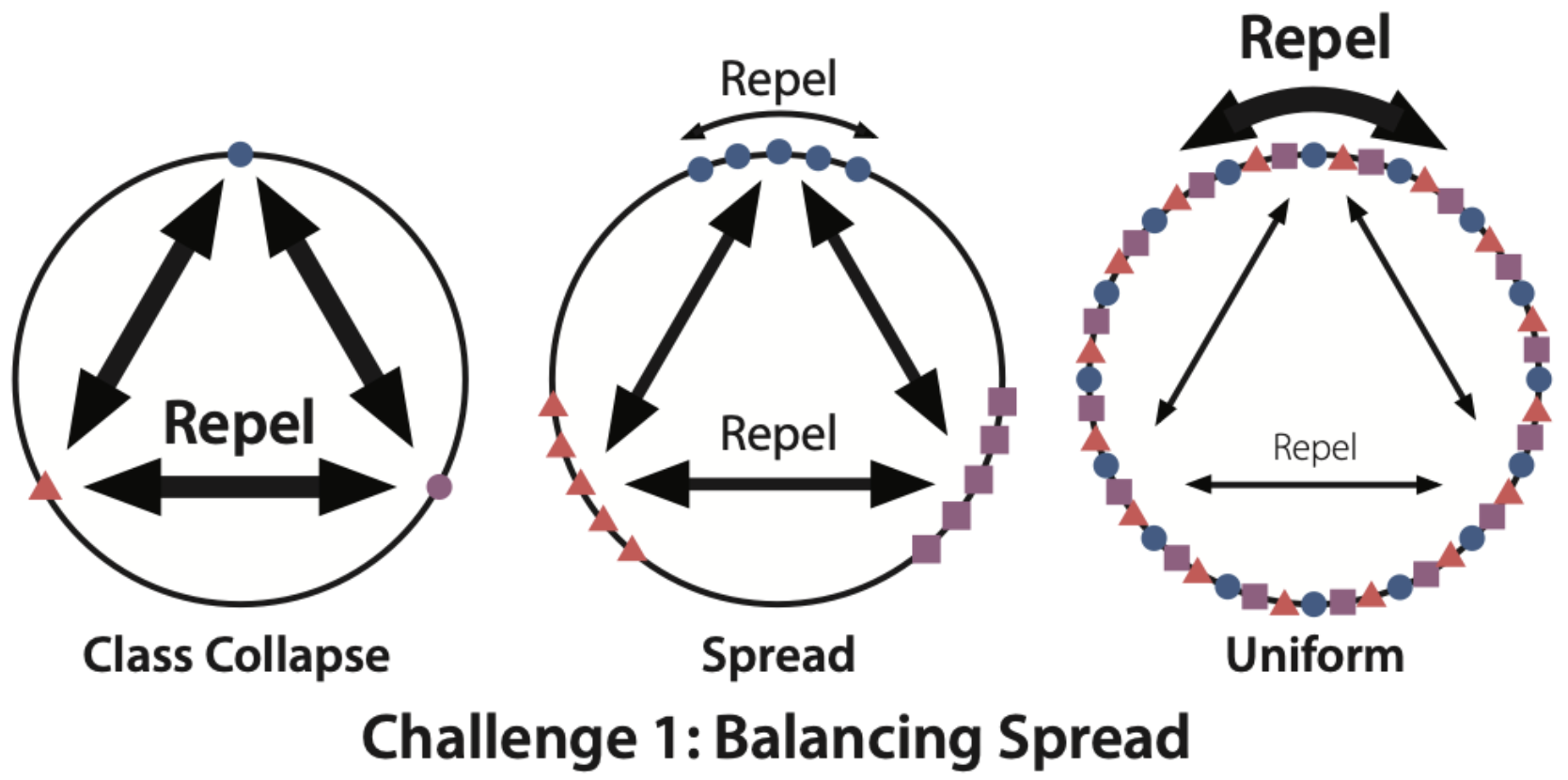
Figure 5. The first challenge is balancing the amount of geometric spread in the representation space.
Our first goal is to understand exactly what role this geometric spread plays in downstream performance, and how it arises.
- Coming to an exact analytical understanding is challenging, since there are two geometric forces at work when you add a SupCon loss to an InfoNCE loss. The SupCon loss trends towards class collapse (Figure 5 left), whereas the InfoNCE loss trends towards uniformity on the hypersphere (Figure 5 right).
- Neither distribution is optimal for transfer; for a particular type of transfer learning called coarse-to-fine (train on coarse classes, freeze embeddings and evaluate on fine subclasses), either extreme results in poor generalization error. This can explain why spread helps with transfer – but we still don’t understand why it happens.
- The loss terms are nonconvex, so it’s not even clear that sufficient spread exists at all in the optimal distribution. In fact, the optimal distribution could flip from collapsed to completely uniform based on the relative weights of the two terms.
- Analyzing how points attract and repel on the hypersphere reduces to fundamentally hard problems in electrostatics. For instance, the famous Thomson problem has gone unsolved for over a century—it simply is not possible to analytically characterize some of its optimal solutions.
Our Solution
Given these technical challenges, we take a different approach. We construct a simple family of relatively spread out point distributions on which it is easy to compute the loss value. We compare this loss value with the loss of the collapsed or uniform distributions and find that when you add a weighted class-conditional InfoNCE loss to SupCon, the spread out distributions have lower loss than either extreme.
This tells us that, with a proper weight within a certain range, adding a class-conditional InfoNCE loss to SupCon can give you the right amount of spread. And we confirmed this with experiments:
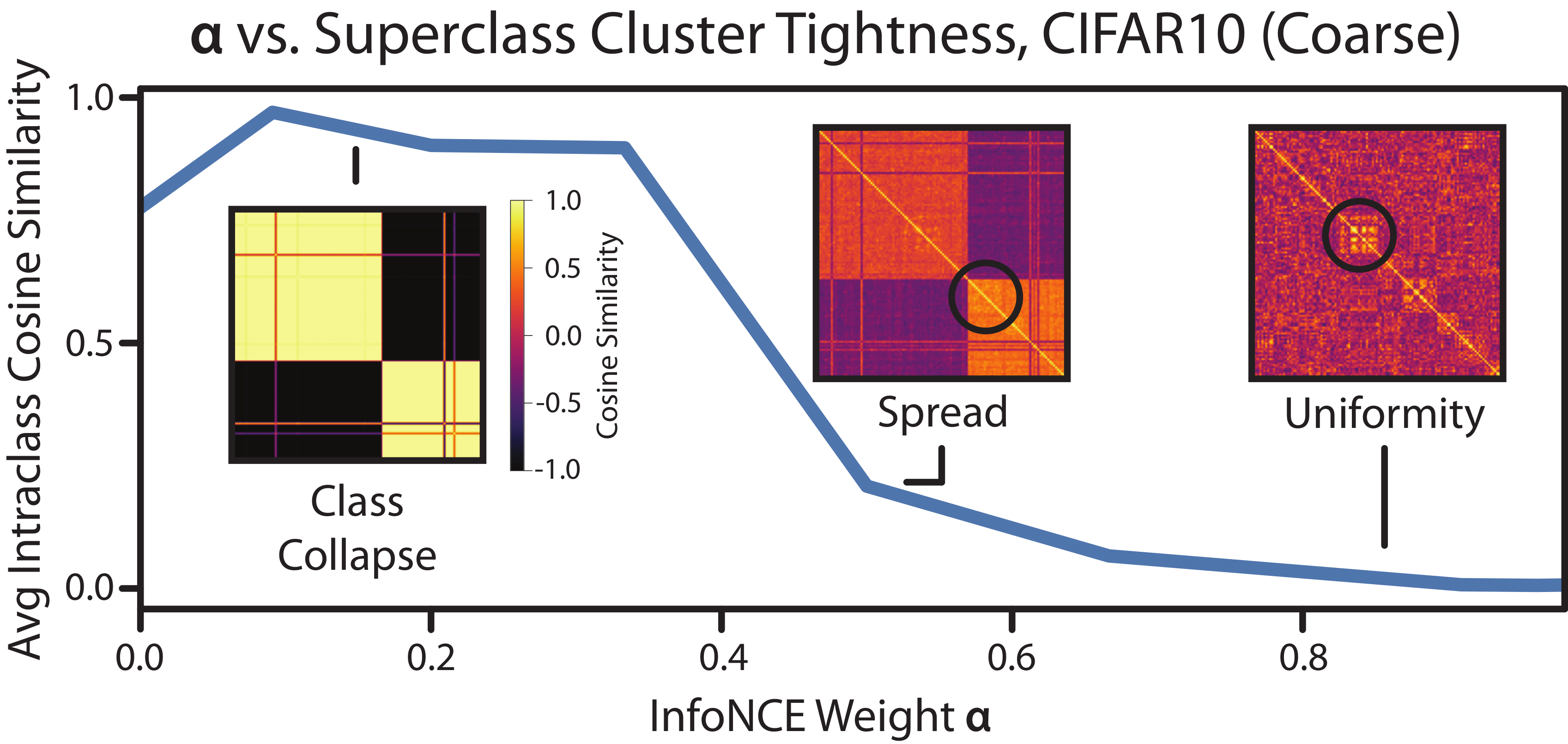
Figure 6. Adding a weighted class-conditional InfoNCE loss to SupCon can create a distribution with spread.
Challenge 2: Breaking Class-Fixing Permutation Invariance

Figure 7. The second challenge is breaking class-fixing permutation invariance. In the regular SupCon loss, any permutation of points within classes results in the same loss value – but can result in vastly different downstream transfer.
But the story doesn’t end there – having spread out representations on their own isn’t enough for good transfer and robustness. One of the properties of the supervised contrastive loss function is that it displays what we call class-fixing permutation invariance. You can randomly permute the representations of points in the same class and get the same loss. Figure 7 demonstrates why this property is undesirable for transfer learning – you can get two representations that have the same supervised contrastive loss value (and the same amount of spread), but with vastly different transfer performance.
One simple approach to solving this problem would be to assume that the encoder is sufficiently “smooth” in embedding space to be Lipschitz. However, this puts pretty strict limitations on what types of encoders that we can use (e.g., MLPs with bounded norms, or logistic regression trained directly over the pixels). Modern neural networks are very much not Lipschitz, since they are powerful enough to memorize random noise (and see our paper for some concrete measures of Lipschitzness).
Our Solution
In our paper, we study two more realistic mechanisms for breaking class-fixing permutation invariance by introducing an inductive bias1 that encourages subclass clustering:
- We show that the data augmentation that is conventionally used in the contrastive loss can encourage subclass clustering (e.g., pulling together representations of two random crops of an image). We show that adding data augmentation weakens the Lipschitzness assumptions that we need to preserve subclasses – and show that these weaker assumptions are more realistic.
- We show that concatenating the representations of a class-conditional autoencoder also encourages subclass clustering. Intuitively, the representations of such an autoencoder better extract salient input features within a class. For such representations to preserve subclasses, only a “reverse Lipschitz” assumption is required on the decoder component of the autoencoder. The decoder is also typically thrown after training, so this assumption does not directly impact the representations and is weaker as a result.
Our Results
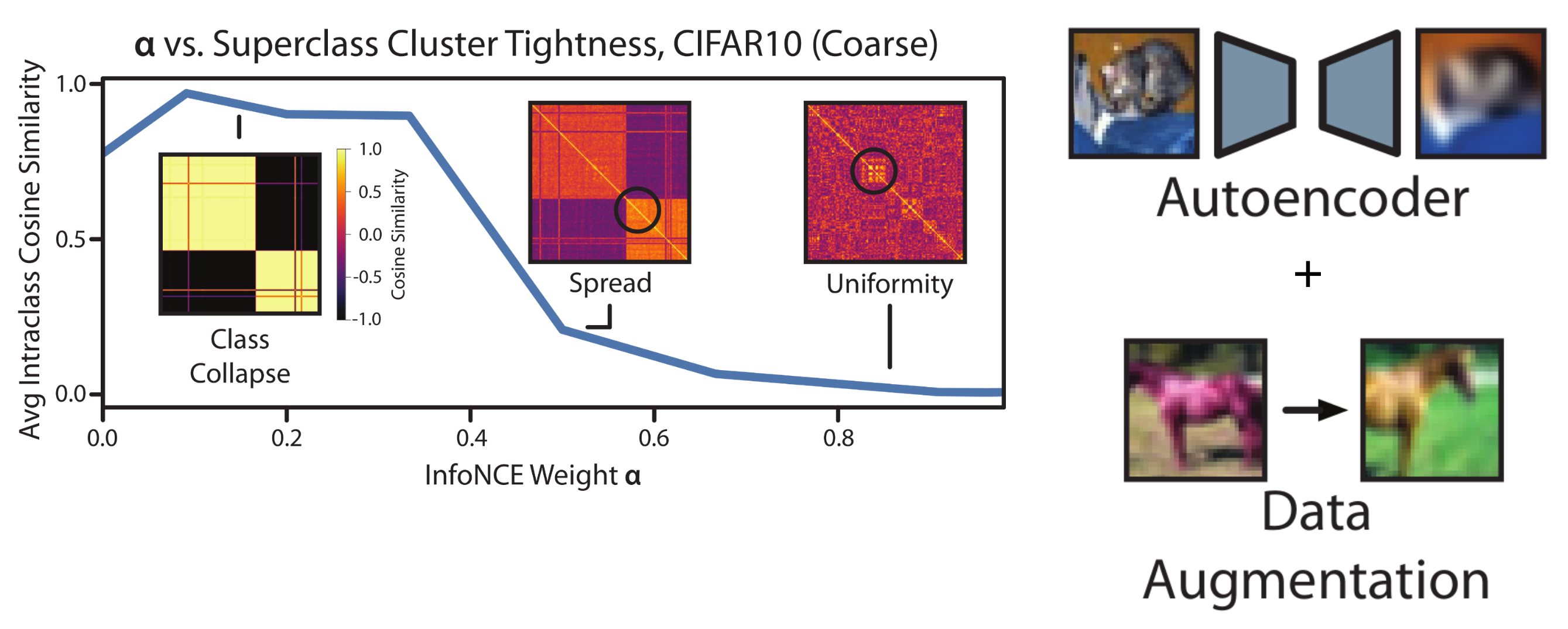
Figure 8. We present Thanos: a new contrastive method that adds a class-conditional InfoNCE loss and a class-conditional autoencoder to SupCon.
Given these insights, we propose Thanos, which consists of adding a class-conditional InfoNCE loss and a class-conditional autoencoder to SupCon. Thanos balances the geometry between class collapse and uniformity, attaining appropriate spread within classes and preserving subgroup clusters.
We evaluate Thanos on two tasks: coarse-to-fine transfer learning, and worst-group robustness. Coarse-to-fine transfer learning evaluates the ability for a representation to pick out fine sub classes after only being trained on coarse classes. Worst-group robustness evaluates how well a method can maintain performance on underperforming (hidden) subgroups. We find that Thanos achieves significant lift on both tasks.
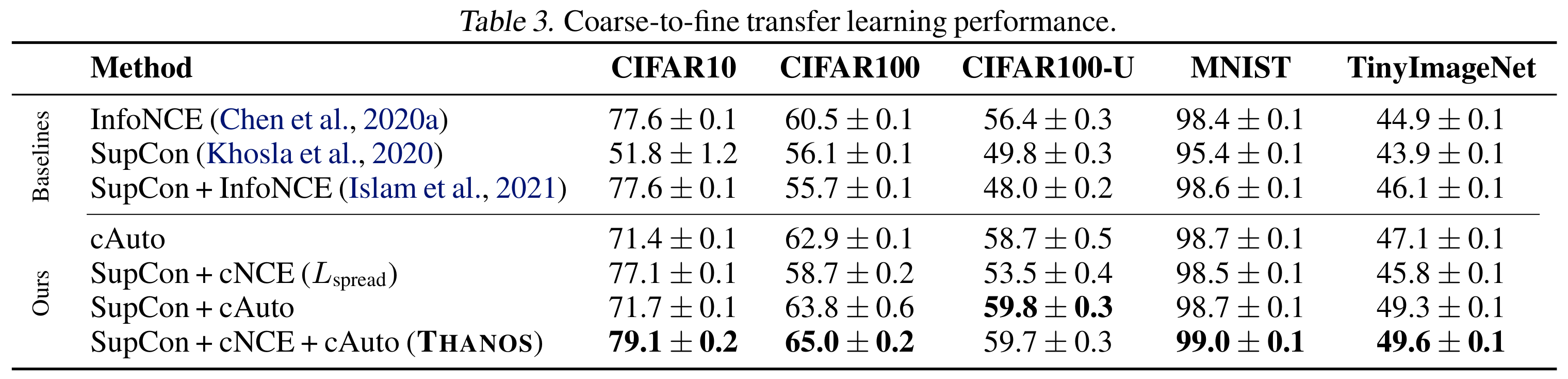
Figure 9. Coarse-to-fine transfer learning performance of Thanos.
On coarse-to-fine transfer, Thanos achieves 11.1 points of lift on average over SupCon across five tasks (with more on the way – stay tuned). It outperforms various ablations as well, such as removing the autoencoder or removing the class-conditional InfoNCE loss individually.
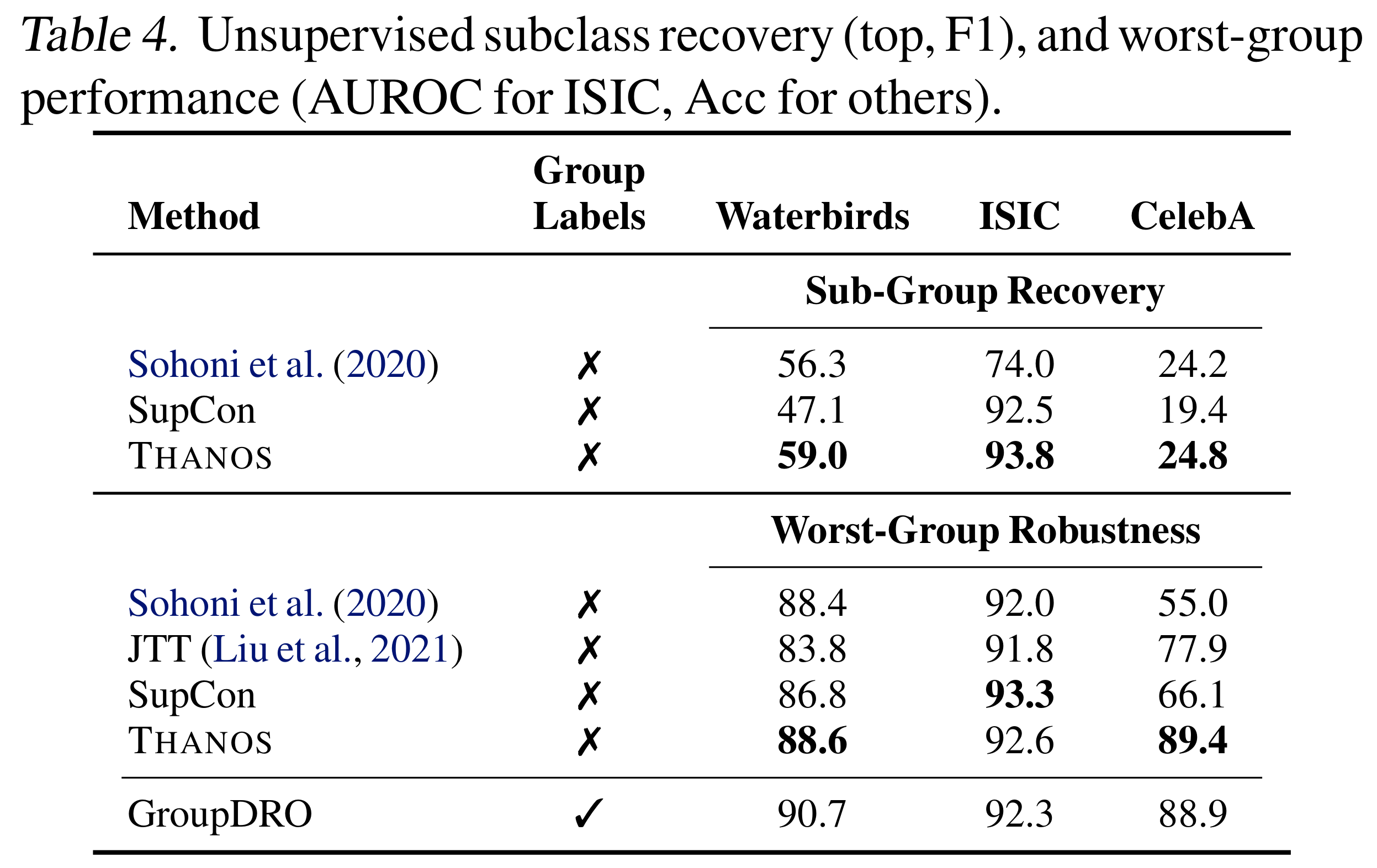
Figure 10. Worst-group robustness performance of Thanos.
On worst-group robustness, Thanos achieves 4.7 points of lift on average over prior work and up to 11.5 points of lift over state-of-the-art on CelebA.
What's Next
We’re super excited about where our geometric perspective on representations in supervised contrastive learning will take us. A few exciting upcoming directions:
- Efficient training with smaller batches. One of the current challenges in contrastive learning is that it requires large batch sizes for training. We think this is a result of the inherent quadratic nature of the contrastive loss (e.g., all the comparisons). The challenges arising from intensive pairwise computations are not just an issue in machine learning, so we’re curious if prior work from other fields (like electrostatics) can help inform solutions and reduce the computational load.
- Multimodal data. Bi-encoders can accept as input multimodal data (e.g. image and text pairs) and learn representations of them in a common embedding space. The alignment of input pairs of image and text is often expressed contrastively, and so we’re curious how our insights on inducing more spread and encoding additional supervision could yield improved representation quality.
- Additional knowledge. Our work is part of a broader push to incorporate additional knowledge, such as superclasses, into supervised contrastive loss. And we are already exploring this! In our next blog post, we talk about TABi: how to use type information contrastively to produce representations for better rare entity retrieval.
Check out parts 1 and 3 of this blog series to see more background on contrastive learning, and how we build on these previous insights to improve entity retrieval!
- Part 1: Advances in Understanding, Improving, and Applying Contrastive Learning
- Part 3: TABi: Type-Aware Bi-Encoders for Open-Domain Entity Retrieval
- Recent work from Saunshi et al. came to similar exciting findings: they found that in the self-supervised setting, permutation invariance can lead to vacuous solutions with poor downstream performance. As a result, inductive bias (i.e. the function class) needs to play a role in the analysis.↩