Apr 19, 2022 · 12 min read
TABi: Type-Aware Bi-Encoders for Open-Domain Entity Retrieval
Megan Leszczynski, Dan Fu, Mayee Chen, and Chris Ré.
TL;DR: State-of-the-art retrievers for open-domain natural language processing (NLP) tasks can exhibit popularity biases and fail to retrieve rare entities. We introduce a method to improve retrieval of rare entities by incorporating knowledge graph types through contrastive learning. Try out our model on GitHub or read more in our paper!
Overview
Entity retrieval—retrieving information about entities mentioned in a query, or going from strings to things—is a key step in many knowledge-centric natural language tasks. A major long-standing challenge for entity retrieval is retrieving the long tail: some entities are seen many times during training but many entities are rarely seen during training. Contrastive learning has seen a growing role in training state-of-the-art dense entity retrievers over unstructured text, but like other state-of-the-art retrievers, contrastive methods still suffer on the tail. In this blog post, we look at how we can apply our understanding of contrastive learning to improve retrieval of rare entities. Our simple insight is to train the retriever contrastively using both knowledge graph types and unstructured text.
This is part three of a three part series on advances in understanding, improving, and applying contrastive learning.
- In part one, we looked at some background on contrastive learning and summarized some theoretical takes on how contrastive learning works.
- In part two, we built on those theoretical takes to look at how to improve the transfer and robustness of supervised contrastive learning.
- In part three (this blog), we’ll see how we can use supervised contrastive learning to improve retrieval of rare entities for open-domain NLP tasks.
Retrieval for Open-Domain NLP
Advances in natural language processing and information retrieval have made it easy to make use of the ever-growing amount of information available on the World Wide Web or in large company knowledge bases. If we want to find out when Julius Caesar was born, not only can we simply query a search engine with the informal natural language query “When was Julius Caesar born” to find the most relevant web pages, but advanced search engines like Google can even extract the answer for us! Tasks like question answering or fact checking, where the query can be about anything and the machine isn’t told where to look to complete the task, are commonly referred to as open-domain NLP tasks.
A standard approach to completing open-domain tasks is to first retrieve relevant information and then further process it to extract or generate the final answer (e.g. Karpukhin et al., 2020). In this blog post, we will focus on the first stage—retrieval—as overall success on the task depends on first retrieving the relevant information correctly. Specifically, we are interested in retrieving entities (any person, place, or thing) to complete entity-centric open-domain tasks, like answer questions about Julius Caesar.
The Challenge of the Long Tail
While there have been impressive advances in natural language understanding, a long-standing challenge is that natural language tends to be ambiguous. We may refer to an entity by a name (i.e. mention) like “Julius Caesar” but there are actually 14 “Julius Caesar”s in English Wikipedia—and Wikipedia is just a small subset of all real world entities. It’s up to the retriever to figure out which “Julius Caesar” we are referring to so that the correct information can be retrieved.

Figure 1: Examples of entities with the name “Julius Caesar” in Wikipedia.
A straightforward strategy is for the model to simply return the most popular entity for the name. But what if we are actually looking for information on one of the rarer entities, like Julius Caesar the cricketer? Julius Caesar the cricketer is part of the long tail of entities, which contains many entities that occur infrequently in natural language. Addressing the long tail is critical for real world applications like search where many users issue queries about rare entities. However, it’s also where machine learning models struggle since they can’t just memorize what entities occur with which names.
To address the long tail, it may seem natural that providing more context would help the model. For instance, we could try querying with “What team does Julius Caesar play for?” Here, the keywords “team” and “play” indicate that we are looking for an athlete. Unfortunately, in practice, state-of-the-art retrievers (and even search engines!) can struggle to use simple context cues like this. Instead, they may exhibit popularity biases and continue to retrieve information about a more popular entity, i.e. Julius Caesar the Roman general (Chen et al. 2021).
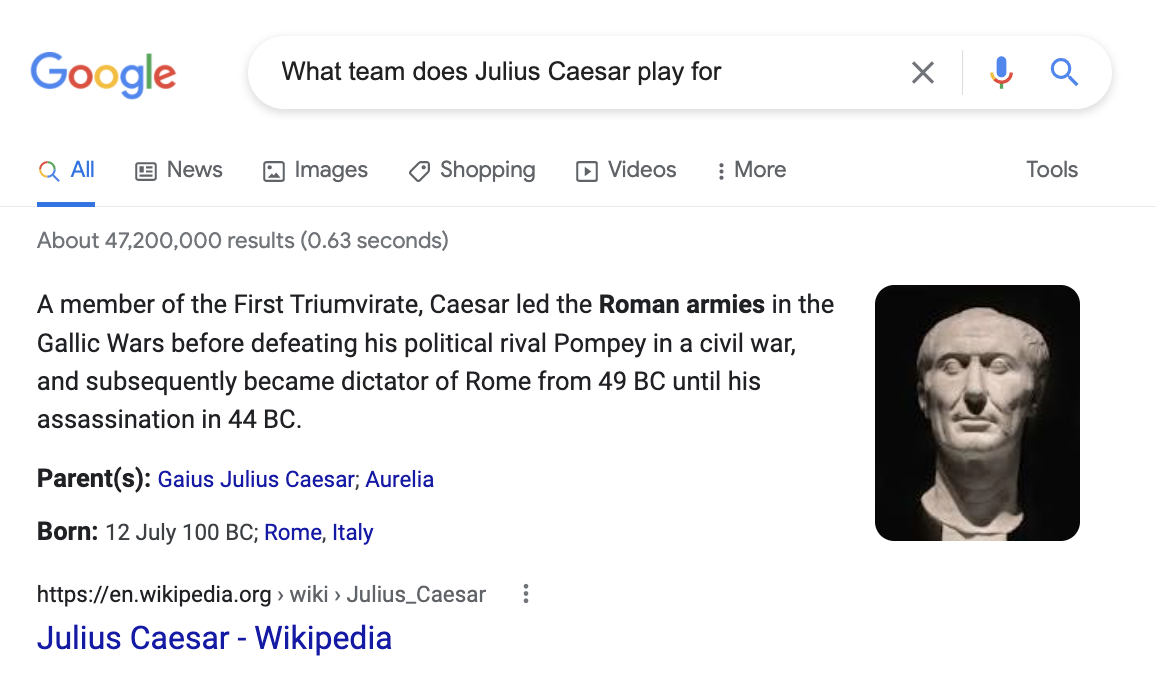
Figure 2: Google returns Julius Caesar (Roman general) when prompted with a query about an athlete. Query example taken from the AmbER sets.
A key issue is that many retrievers are only trained on unstructured text, such as Wikipedia pages or news articles. Given the popularity biases present in training datasets and the highly variable nature of text, it is easier for the model to learn to rely on the entity popularity rather than learn to associate context cues (e.g. “team” and “play”) with particular groups of entities (e.g. athlete).
Using Types to Help the Tail
The good news is that structured data about entities is often available in knowledge graphs (see Figure 3). For instance, knowledge graph types group together entities from the same category (e.g. athletes, musicians).
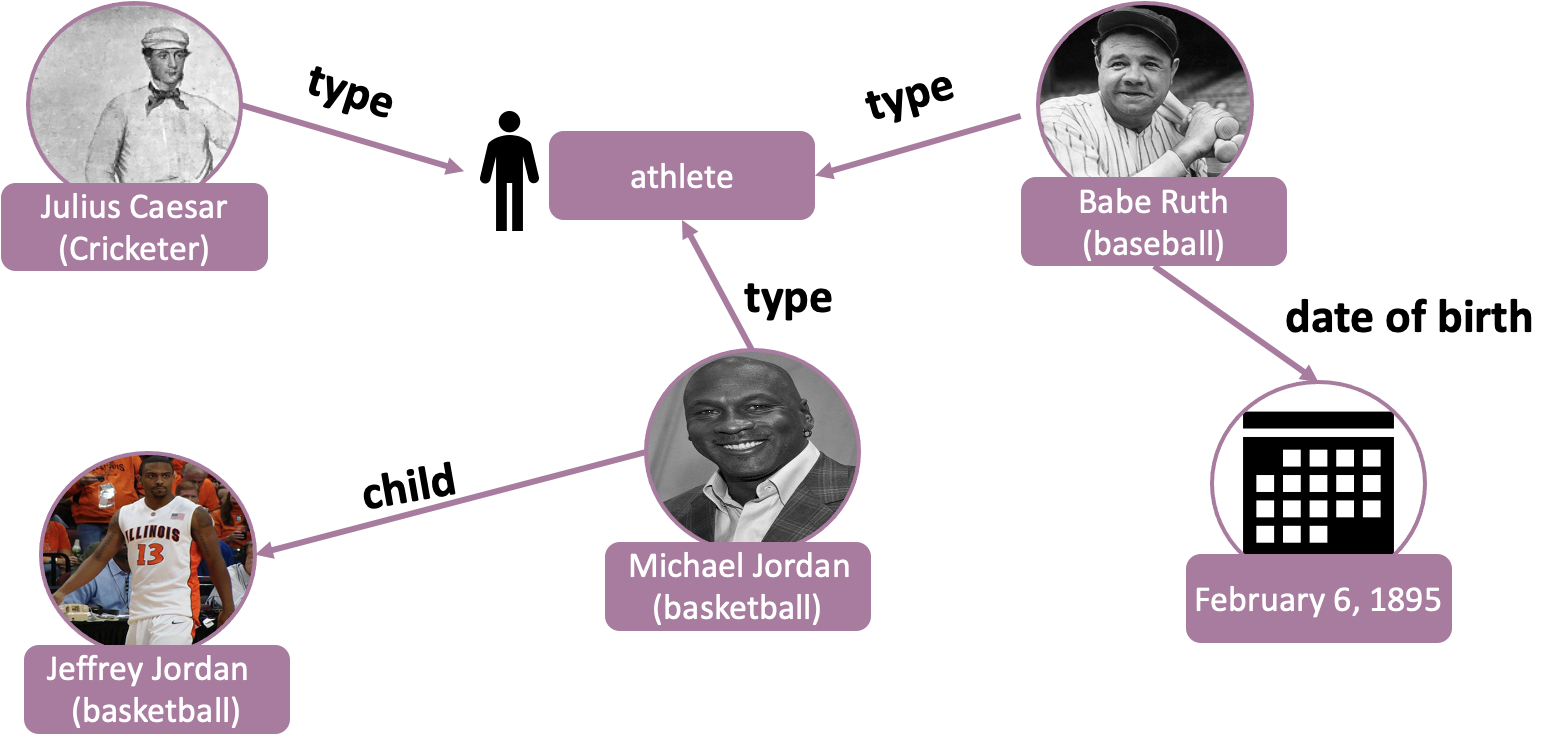
Figure 3: Example of a knowledge graph that stores structured data about entities. The nodes of the graph are entities and the edges are relations between entities. Wikidata is a free, community-edited knowledge graph that we use in our work.
Recent work in the named entity disambiguation literature has shown that incorporating knowledge graph types into the model can improve rare entity disambiguation (e.g. Gupta et al., 2017, Onoe and Durrett, 2020, Orr et al., 2020). Motivated by this work, we ask: can we use both knowledge graph types and unstructured text to train more robust retrievers for open-domain NLP tasks?
Why is it difficult to use types?
Before diving into our approach, there are several challenges we need to consider with using types for open-domain entity retrieval.
- Lack of mention boundaries: Existing type-based entity disambiguation methods assume mention boundaries (spans indicating the location of the mention) are provided in the input. However, open-domain tasks only have the raw text as input and adding a mention detection stage can significantly degrade quality (up to 40% in our experiments).
- Tradeoff with popular performance: The ideal method should not compromise performance over popular entities. Thus, the model needs to learn to balance learning popularity biases with learning to pay attention to context cues.
- Missing and incorrect types: The ideal method should be robust to imperfect type information during training. Knowledge graphs are known to be incomplete and the automated techniques used to assign types to queries can be noisy.
To address these challenges, we build on the state-of-the-art dense retrievers trained through contrastive learning and use our understanding of supervised contrastive learning to incorporate types into the training procedure. We’ll briefly review the standard procedure for training dense entity retrievers through contrastive learning and then discuss how we change the procedure to incorporate types.
Background: Contrastive Learning for Entity Retrieval
Contrastive learning has been shown to be highly effective for learning state-of-the-art dense retrievers across application domains, including named entity disambiguation (e.g. BLINK), document and passage retrieval (e.g. DPR), and image retrieval (e.g. CLIP). The common model architecture used for contrastive learning for retrieval is a bi-encoder.
For entity retrieval, the bi-encoder consists of a query encoder to produce vector representations (i.e. embeddings) of the query and an entity encoder to produce embeddings of the entities (see Figure 4). The entity encoder embeds textual descriptions of an entity such as the first paragraph from an entity’s Wikipedia page.
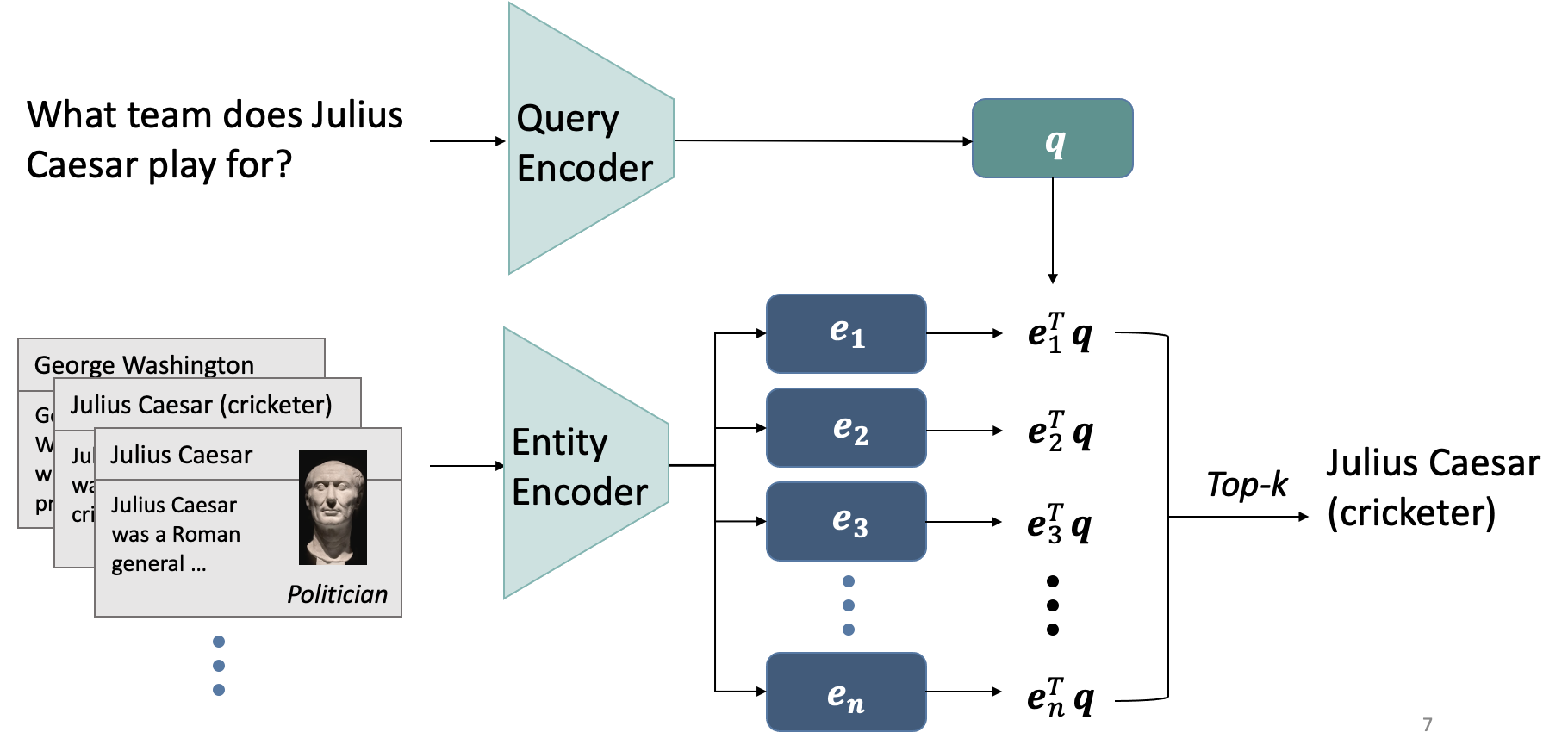
Figure 4: A bi-encoder consisting of a query and entity encoder can be used to retrieve the top-K entity candidates for a query through nearest neighbor search with the query embedding.
During training, the model contrasts pairs of queries and their ground truth entities with pairs of queries and other entities using the popular InfoNCE loss function (van den Oord et al., 2018). This pulls together embeddings of queries and their ground truth entities and pushes apart embeddings of queries and other entities. At test time, the entity embeddings can be pre-computed and stored in an index. The top-K most relevant entities for a query can then be retrieved through nearest neighbor search over the index using the query embedding.
A limitation of this method is that it can lead to retrievers that exhibit popularity biases (Chen et al. 2021). Query embeddings can be closest to the most popular entity embeddings for the mention in the query, regardless of the context. Can we incorporate knowledge graph types into the contrastive training procedure to reduce these biases?
Our Twist: Incorporating Types Contrastively
Our key insight is that rather than adding the knowledge graph types as textual input to the entity encoder, we add the types as additional supervision in the contrastive loss function. We call our new training procedure TABi (Type-Aware Bi-encoders).
Building on the standard contrastive procedure described above, TABi adds a type-enforced loss term that contrasts pairs of queries based on their knowledge graph types. If the two queries are of the same type (e.g. athlete), their embeddings are pulled together; otherwise, they are pushed apart (see Figure 5). This loss term forces the model to not only pay attention to the context cues in the query but also encourage embeddings of the same type to be closer together in the embedding space.
When given a query like “What instrument does Roosevelt play”, a standard retriever embeds the query close to the entity embedding for the popular president Franklin D. Roosevelt, since the name “Roosevelt” most often refers to the president. When embeddings are clustered by type, the retriever embeds the query closer to other musician entity embeddings and is more likely to to retrieve the correct the entity, Roosevelt the musician. Popular entities become less likely if they do not match the type of query.
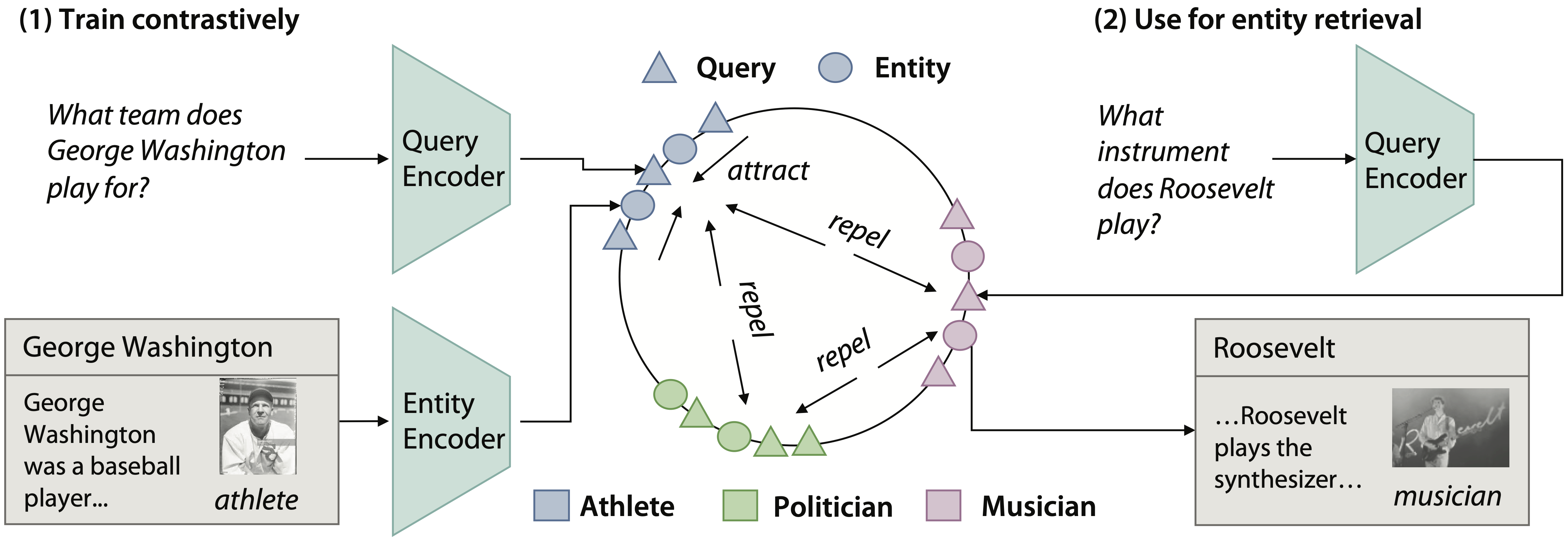
Figure 5: TABi introduces a new loss function to train bi-encoders that pulls together queries of the same type in the embedding space.
Specifically, TABi uses the supervised contrastive loss (Khosla et al. 2020) for both the type-enforced loss term (which uses the type to form pairs) and the standard loss term (which uses the ground truth entity to form pairs). We find that a simple tunable weight on the two terms can help tradeoff how much the model pays attention to the context versus the mention in the query.
Supporting our intuition, we find that TABi results in stronger clustering by types in the embedding space when we add the types in the contrastive loss function (see Figure 6).

Figure 6: t-SNE plots of entity embeddings for different contrastive training procedures. (Right) TABi achieves the best type clustering when including types in the contrastive loss.
Benchmark Results
We find that TABi improves rare entity retrieval, while maintaining strong overall retrieval—even with noisy types. We use the recently released benchmark, AmbER, to evaluate rare entity retrieval and the KILT benchmark to evaluate overall retrieval. Check out our paper for more details and experiments!
- Rare entity performance: Without types, we find that TABi already significantly improves over off-the-shelf retrievers. As both TABi and BLINK use bi-encoder models, we think TABi greatly benefits from training on the same multi-task data as GENRE. With the type-enforced loss, TABi further improves top-1 retrieval over the tail by nearly 6 points on the AmbER sets.
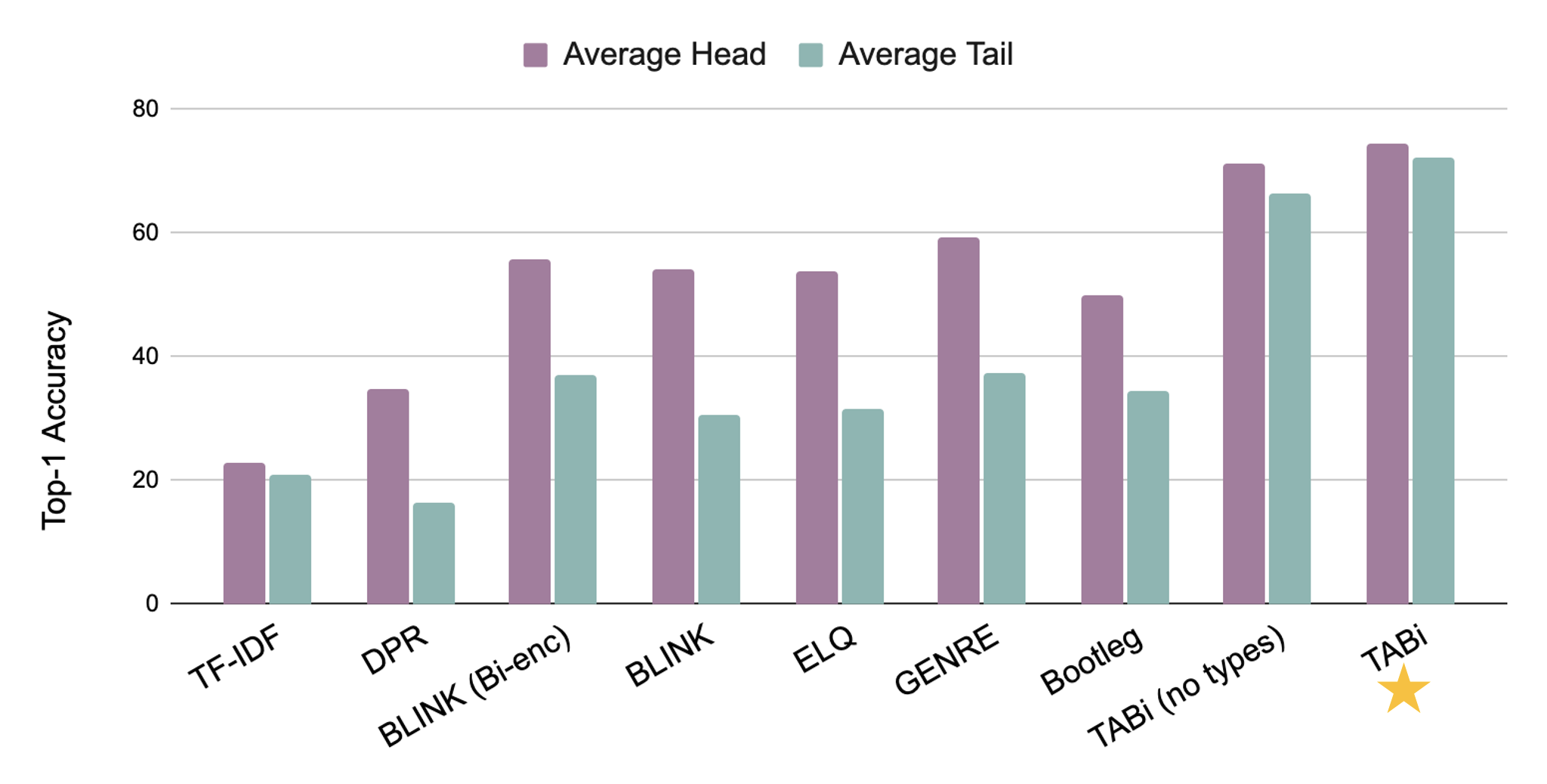
Figure 7: Average top-1 retrieval accuracy on AmbER.
- Overall performance: TABi nearly matches or exceeds the state-of-the-art multi-task model (GENRE) for retrieval on the eight open-domain tasks in KILT and sets a new state of the art in three tasks (average performance in Figure 8).
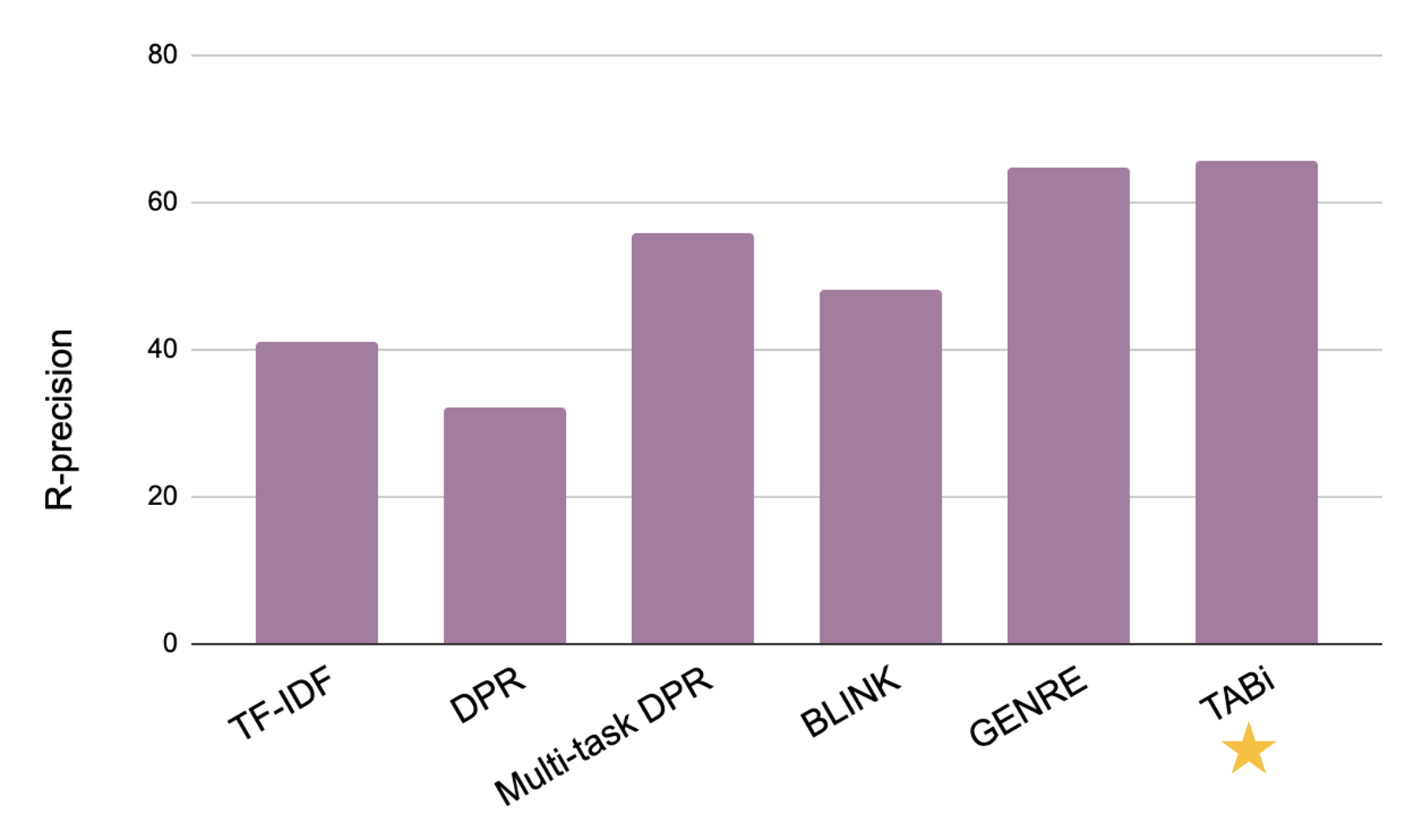
Figure 8: Macro-average R-precision on the eight open-domain tasks in KILT (test).
- Robustness: TABi can benefit from the type-enforced loss with just 5% of training examples having types and with 75% of the types being incorrect.
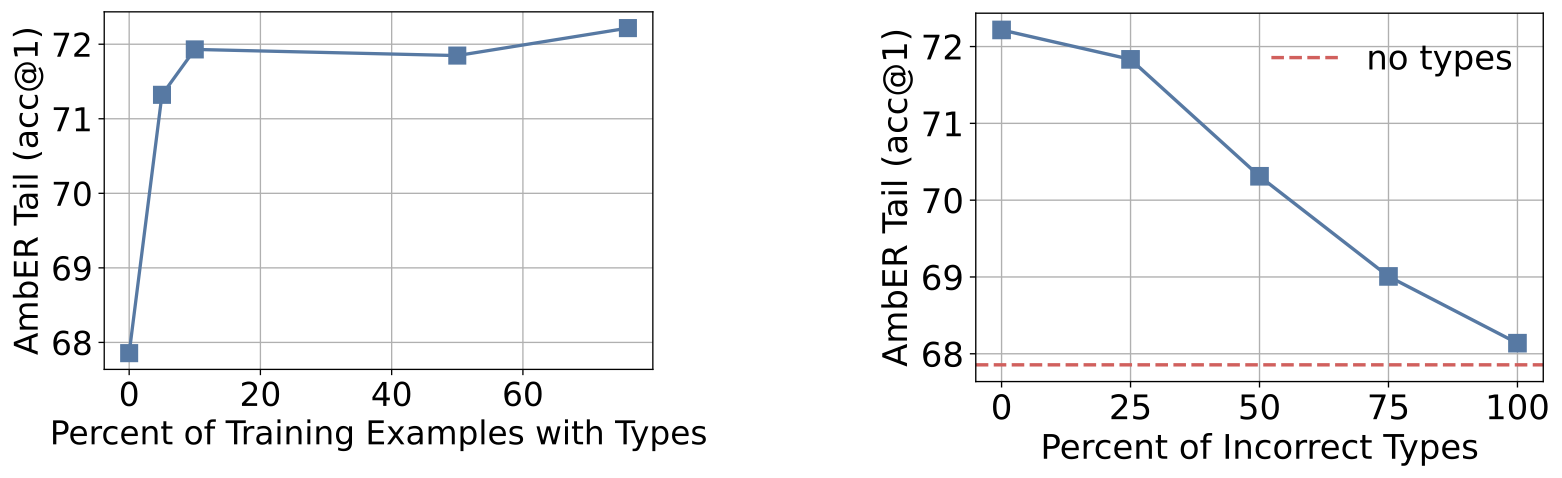
Figure 9: TABi’s top-1 retrieval accuracy for varying amount of type coverage (left) and type correctness (right).
Looking Forward
Our method is a step in incorporating knowledge in the form of structured data into dense retrieval models. We are excited about the following directions:
- Other forms of structured data: Knowledge graph types are only one form of structured data that can be available for entities. For instance, there are also relations (e.g. spouse, birthplace) between entities in a knowledge graph that could provide useful signal for disambiguation. It would be interesting to explore ways to incorporate structured data beyond types into the dense retrieval space.
- Other forms of knowledge: While dense retrievers have had success across applications and modalities (images, text, audio), structured data may not always be readily available. Leveraging more relaxed definitions of knowledge—for instance, slicing functions written by domain experts over the training data—could enable similar techniques as TABi to be applied to more domains.
Check out parts 1 and 2 of this blog series to see more background on contrastive learning, and how we can generally improve the transfer and robustness of supervised contrastive learning!