Jan 14, 2022 · 6 min read
Structured State Spaces for Sequence Modeling (S4)
Albert Gu, Karan Goel, Khaled Saab, and Chris Ré
In this series of blog posts we introduce the Structured State Space sequence model (S4). In this first post we discuss the motivating setting of continuous time series, i.e. sequence data sampled from an underlying continuous process, which is characterized by being smooth and very long. We briefly introduce the S4 model and overview the subsequent blog posts.
In this series of blog posts we introduce the Structured State Space sequence model (S4). In this first post we discuss the motivating setting of continuous time series, i.e. sequence data sampled from an underlying continuous process, which is characterized by being smooth and very long. We briefly introduce the S4 model and overview the subsequent blog posts.
When it comes to modeling sequences, transformers have emerged as the face of ML and are by now the go-to model for NLP applications. Transformers are particularly effective for problems with medium length dependencies (say length ~100-1000), where their attention mechanism allows processing complex interactions within a fixed context window. However, this strength is also a fundamental limitation when it comes to sequences with very long dependencies that cannot fit inside this fixed window. In fact, outside of NLP - think domains such as speech, health, video, and robotics - time series often have quite different characteristics that are not suited to transformers. In particular, data in these domains can be very long (potentially unbounded!) and are implicitly continuous in time. In this post, we overview the challenges and recent advances in addressing extremely long, continuous time series.
The Challenges of Continuous Time Series
What we call “continuous time series” is a large class consisting of very long, smoothly varying data, because they frequently arise by sampling an underlying continuous-time process.
This class of sequence data is ubiquitous, and can arise for example from:
- Audio and speech
- Health data, e.g. biometric signals
- Images (in the spatial dimensions)
- Video
- Measurement systems
- Robotics
Examples of non-continuous data include text (in the form of tokens), or reinforcement learning on discrete MDPs.
"Continuous time series" are characterized by very long sequences sampled from an underlying continuous process
These continuous time series usually share several characteristics that are difficult to address, requiring models to:
-
Handle information across long distances
- For example, when processing speech data which is usually sampled at 16000Hz, even understanding short clips requires dependencies of tens of thousands of timesteps
-
Understand the continuous nature of the data - in other words, should not be sensitive to the resolution of the data
- E.g. your speech classification model should work whether the signal was sampled at 100Hz or 200Hz; your image generation model should be able to generate images at twice the resolution
-
Be very efficient, at both training and inference time
- Deployment may involve an "online" or incremental progress (e.g., continuously monitoring a set of sensors for anomalies)
- On the other hand, efficient training requires parallelization to scale to the extremely long sequences found in audio and high-frequency sensor data
Structured State Spaces (S4)
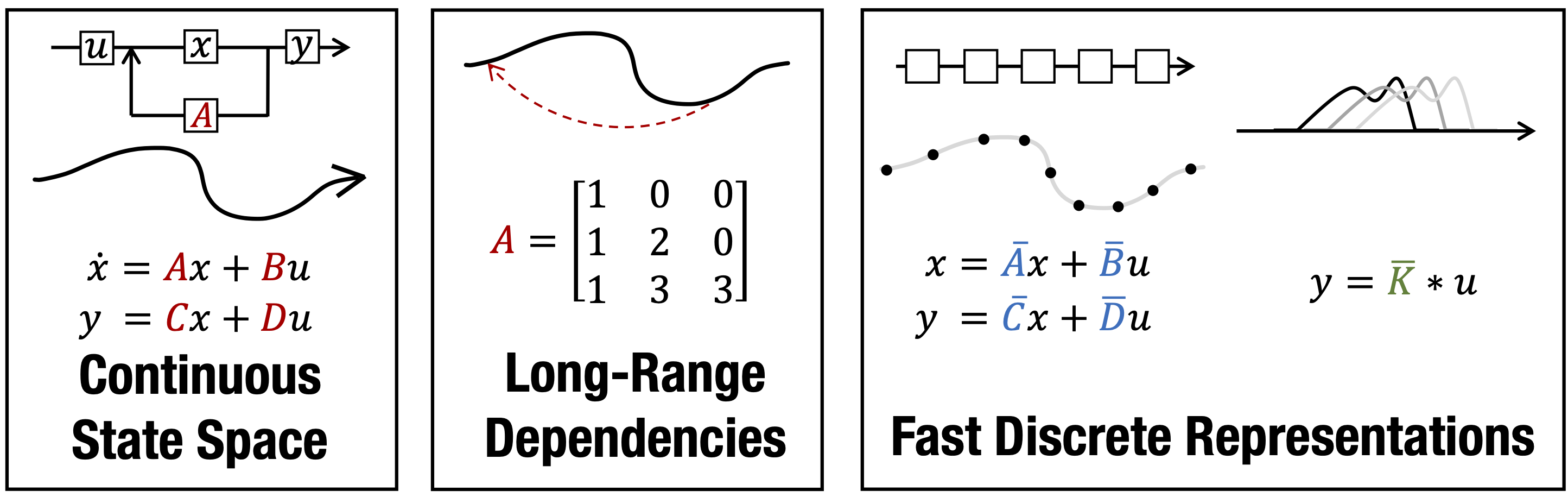
The Structured State Space (S4) is a new sequence model based on the state space model that is continuous-time in nature, excels at modeling long dependencies, and is very computationally efficient.
Our recent work introduces the S4 model that addresses all of these challenges. In a nutshell, S4 is a new sequence model (i.e. a sequence-to-sequence transformation with the same interface as a Transformer layer) that is both very computationally efficient and also excels at modeling long sequences. For example, on the Long Range Arena benchmark which was designed to compare the long-range modeling capabilities as well as computational efficiency of sequence models, S4 set a substantial state-of-the-art in performance while being as fast as all competing models.
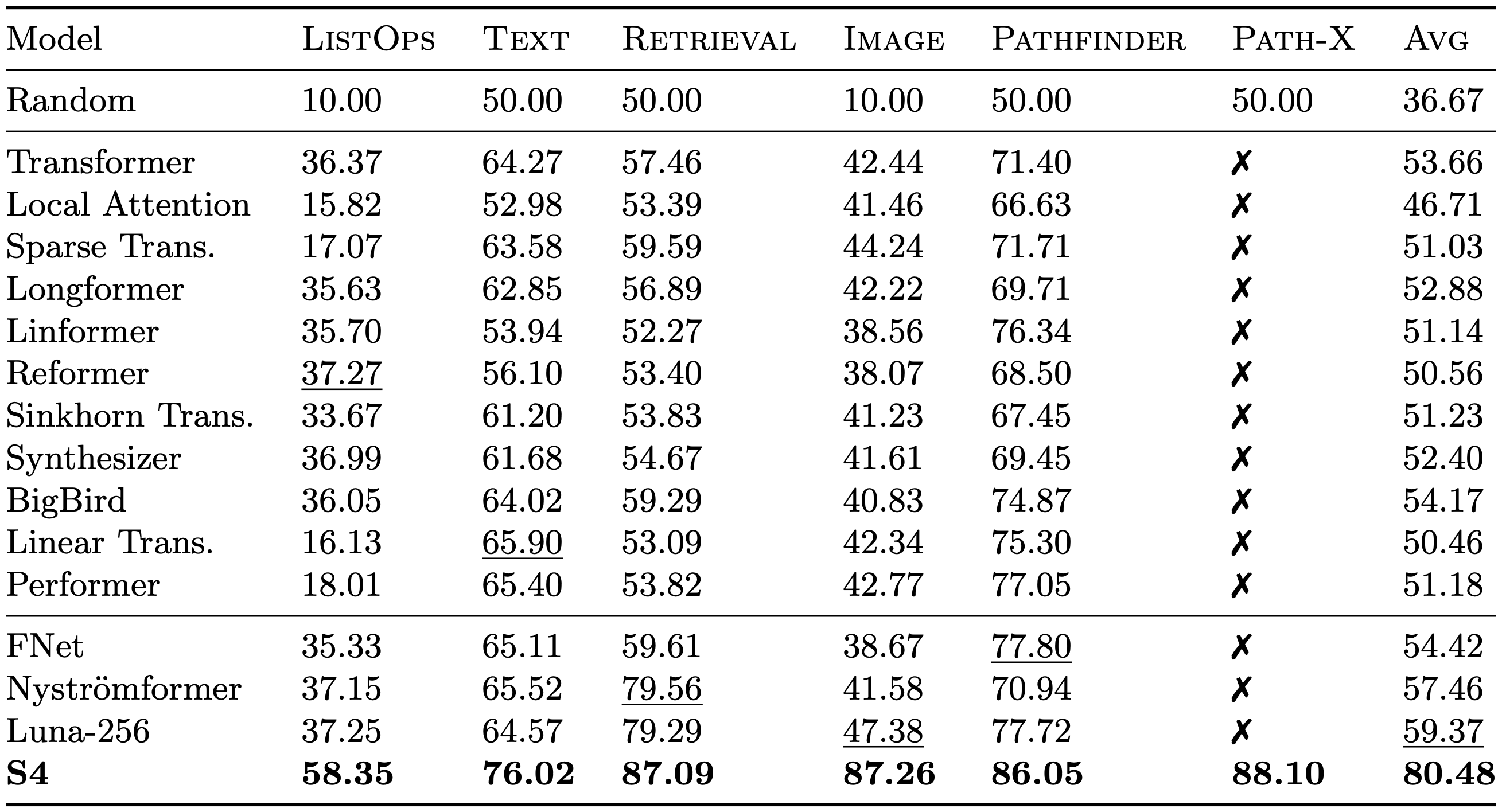
On the Long Range Arena (LRA) benchmark for long-range sequence modeling, S4 sets a clear SotA on every task while being at least as computationally efficient as all competitors. It is the first sequence model to solve the Path-X task involving sequences of length 16384.
S4 is based on the following series of papers on new techniques for modeling long sequences:
- HiPPO (which we've previously blogged about in more detail)
- Linear State Space Layer
- Structured State Spaces
What’s in this blog
This series of blog posts gives an overview of the motivation, background, and properties of S4. We focus in particular on discussing aspects of its intuition and development process that were difficult to convey in paper form. We recommend checking out the full papers listed above for full technical details.
- In Part 2, we briefly survey the literature on S4’s line of work, discussing the strengths and weaknesses of various families of sequence models and previous attempts at combining these families.
- In Part 3, we introduce the state space model (SSM), showing how it has three different representations that give it strengths of continuous-time, recurrent, and convolutional models - such as handling irregular sampled data, having unbounded context, and being computationally efficient at both train and test time
- (Work in progress!) In Part 4, we discuss the substantial challenges that SSMs face in the context of deep learning, and how S4 addresses them by incorporating HiPPO and introducing a new parameterization and algorithm. We discuss its strengths and weaknesses and look toward future progress and applications
Using S4
We have publicly available code to reproduce our most important experiments, which includes a standalone PyTorch module for S4 that can be used as a drop-in replacement for any sequence model (e.g., as a direct replacement for self-attention).
Finally, Sasha Rush and Sidd Karamcheti have published an amazing blog post that dives into the gritty technical details of S4 and reimplements S4 completely from scratch in JAX. Check out their post at The Annotated S4 as well as their JAX library!