Jul 25, 2023 · 10 min read
Monarch Mixer: Revisiting BERT, Without Attention or MLPs
Code | Checkpoints 80M, 110M | arXiv coming soon! | Full Author List
Over the past six years, we’ve seen Transformers take the world by storm. Transformers have been the workhorse architecture behind modern foundation models and have seen impressive empirical success across diverse applications – from pretrained language models like BERT, ChatGPT, and Flan-T5, to image models like SAM and stable diffusion. We think Transformers are great (and have had lots of fun optimizing them), but we’ve also been thinking about a deeper question:
Are Transformers the only way to get this amazing performance?
Now, the first reason we’ve been poking around at this is because it’s really interesting! Diving into the inner workings of the architectures could help us understand what makes our current generation of models really tick and learn how to train or use them better. And we’ve been really excited by a lot of the work looking into new architectures, from S4 to BiGS, Mega, Liquid, and more. It’s great to live in a world where there are so many great ideas!
But we’re also interested in this question for some core efficiency reasons. Ideally, an alternative to Transformers would scale more efficiently while still matching in quality. One strong motivation for us has been scaling in sequence length – hence the line of work in our lab looking into replacing attention with a sub-quadratic operator (S4, H3, Hyena, HyenaDNA). And we’re encouraged by the groundswell of work into new architectures for long sequences, from RetNet to RWKV, and positional interpolation – just to name a few!
MLPs – the other core building block of Transformers – also introduce an efficiency bottleneck, which becomes more acute as we continue to optimize attention. MLPs are quadratic in the model width, which means they grow more expensive as you make models wider. This is why models like GPT-3 are so expensive, and why GPT-4 has allegedly started using techniques like mixtures of experts.
What if there were a model that were sub-quadratic along both sequence length and model dimension, and could match Transformers in quality?
Today we’re excited to present a little teaser of some work in this direction – Monarch Mixer BERT (M2-BERT). M2-BERT is sub-quadratic in sequence length and model dimension, has 25% fewer parameters/FLOPs than BERT, and matches in quality (potentially exceeding a little bit when parameter-matched). We’re still very early days, so come talk to us if you find these questions exciting! And if you’re reading this the week of release, we’ll be at ICML – come find us in Hawaii, we’ll be putting up a poster at the ES-FoMo workshop!
This blog post highlights a small portion of the Monarch Mixer line of work. Full arXiv coming soon, and this would not have been possible without the full team!
Monarch Mixer
Our basic idea is to replace the major elements of a Transformer with Monarch matrices — which are a class of structured matrices that generalize the FFT and are sub-quadratic, hardware-efficient, and expressive. A key property of Monarch matrices is that they can be computed using a series of block-diagonal matrices, interleaved with permutations:
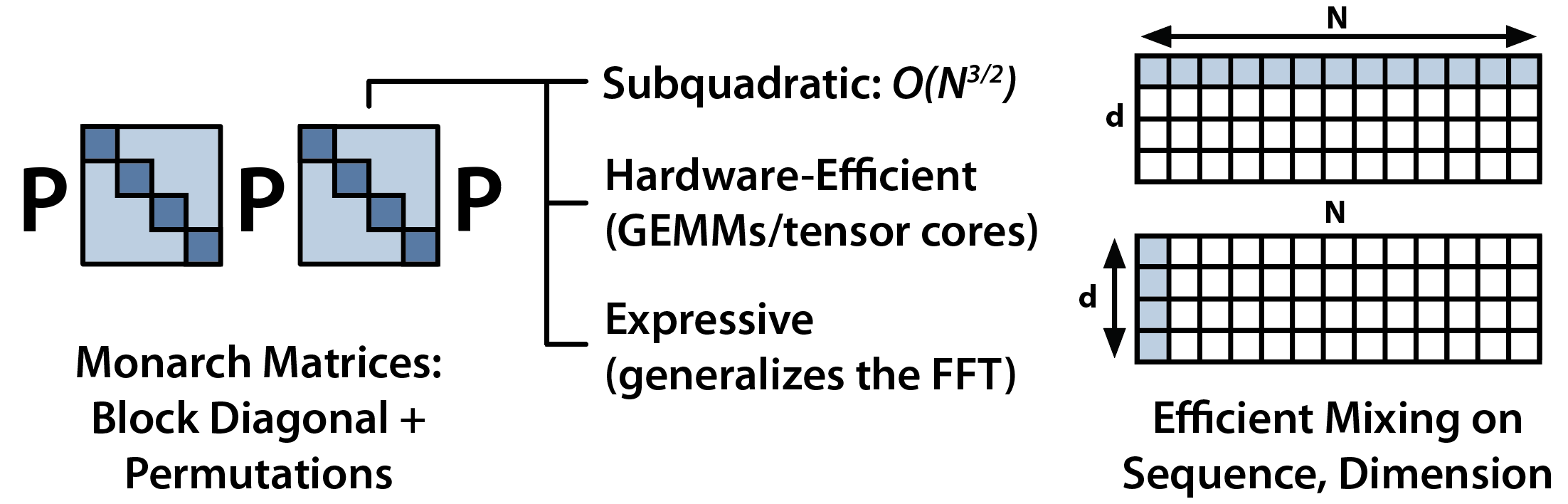
In Monarch Mixer (M2), we use layers built up from Monarch matrices to do both mixing across the sequence (what attention does in Transformers) and mixing across the model dimension (what the MLP does in Transformers). This is similar in spirit to great work like MLP Mixer and ConvMixer, which similarly replaced everything with a single primitive for vision tasks (but went for quadratic primitives).
Why go for a fully sub-quadratic architecture now? We’re continuing off a recent line of work in our lab (and elsewhere) that replaces attention with long convolutions – which is implemented efficiently with the FFT. Critically, Monarch matrices can implement the FFT – which gives us hope that a fully Monarch-based architecture can get there.
Revisiting BERT with Monarch Mixer
As a first proof-of-concept of our ideas, we’re going to roll the clock back to 2018, and look at one of the first big applications of pretrained Transformers – language modeling with BERT! Despite its (relative) age, BERT is still a workhorse model for applications such as text classification, retrieval, search, and more (see this great summary – and this great tweet on why we love BERT).
For our model, we’ll replace the attention block with a layer inspired by previous work in attention-free models (H3 & Hyena), and replace the fully-connected layers in the MLP with some simple block-diagonal matrices. All of these operations can be implemented with Monarchs, and the rest is standard stuff like element-wise multiplication, and simple pointwise operators.
Our sequence mixer block builds off H3 and Hyena. Our previous blogs give some intuition about what the architecture is doing – in brief, the short convolutions allow the model to do a quick lookup of nearby tokens, while the long convolutions allow global information to pass over the sequence.
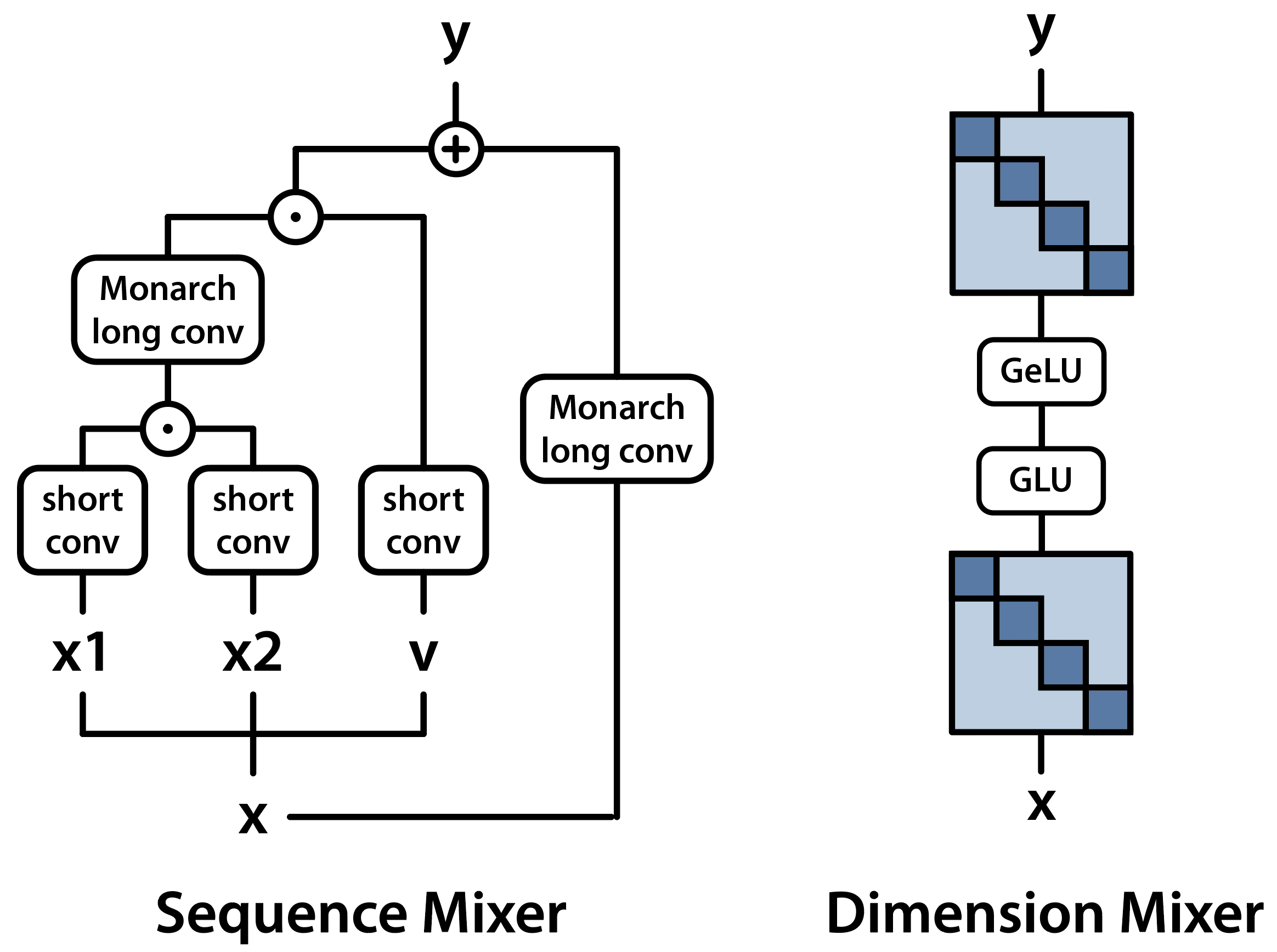
The deltas between our sequence mixer the original H3/Hyena layer are a bit interesting, so we’ll go over them briefly:
- FFT -> Monarch: in H3 and Hyena, the long convs are computed using the FFT, e.g.
iFFT(FFT(x) * FFT(k)). In M2-BERT, we compute these FFTs with Monarchs! - Causal vs. bidirectional: in H3 and Hyena, the long convs are causal (for the autoregressive language modeling loss). This is done by padding the inputs of the FFTs with zeros, since the FFT implements a circular convolution. In M2-BERT, we make the convolutions non-causal by making the convolution kernel twice the length of the input, which makes the weights wrap around.
- Convolution kernel: For the actual kernels
k, we use a CKConv parameterization with an exponential, similar to Hyena! In our bidirectional setup, this makes the convolution kernels focus on nearby tokens in the input. - Extra convolution connection: for BERT, we found that adding an extra convolution (a “residual” so to speak) improved performance on synthetic tasks and pretraining loss.
- Average pooling in fine-tuning: Transformer-based BERT models are traditionally fine-tuned using the embedding of the CLS token. We find that taking the average pool of the embeddings in the input can work a bit better for M2-BERT on downstream tasks that require comparing information spread across multiple sentences such as GLUE NLI tasks (one intuition is that the convolutions spread the information across more tokens).
Lastly, the dimension mixer looks a lot like a normal MLP with GLU, but replaces the fully-connected layers with block-diagonal layers – which drastically reduces the parameters and makes the model more efficient!
So then the natural questions are – given the drastic parameter reduction, how does quality compare to a standard BERT model, and how much faster is it?
Quality on GLUE
So our first evaluation was pretraining some M2-BERT models and comparing their downstream GLUE scores after fine-tuning.
When we take our M2-BERT models with the same model width and depth as a standard BERT model, we get some pretty decent parameter savings – M2-BERT-base with 12 layers and model with 768 has 80M parameters, compared to a standard BERT-base of 110M parameters. We pretrained M2-BERT-base (80M) on 36.5B tokens of C4, at sequence length 128, as well as an M2-BERT parameter-matched to BERT-base.
Surprisingly, we can get pretty decent results, even with fewer parameters – M2-BERT-base (80M) matching the original BERT-base scores from Devlin 2018 BERT, and the parameter-matched M2-BERT-base sees further lift (see the end of the blog post for full numbers):
| Model | Average GLUE Score |
|---|---|
| BERT-base (110M) | 79.6 |
| Crammed BERT-base (110M) | 79.1 |
| M2-BERT-base (80M) | 79.9 |
| M2-BERT-base (110M) | 80.9 |
There’s still a lot we don’t know about these models, so quality could get even better. We mostly took standard Transformer BERT-base hyperparameters, besides some basic hyperparameter sweeps on fine-tuning. The Transformer hyperparameters have been optimized by the community in tons of ways over the past five years, so there’s a lot still to learn about what the best hyperparameters and training formulae are for M2 (e.g., we observed up to half-point swings in average GLUE score during our sweeps). And there’s been great work in the community about exactly how much gating you need for different tasks (e.g., BiGS, section 7.2, so lots more to explore here).
Long Sequence Preview
So what does this new architecture buy us? One possibility is speed, and scaling to longer sequences. Since M2 is sub-quadratic in model dimension, we see a FLOP reduction (which is reflected in the lower parameter count). But the sequence mixer is also sub-quadratic in sequence length, which means the potential to scale to longer sequences.
We’ll be exploring long-sequence M2-BERT models more in-depth in the coming weeks, but for now here’s a simple preview of throughput at different sequence lengths, compared to the HuggingFace BERT-base and a more optimized FlashAttention BERT-base, for various sequence lengths. Here, we’re looking at throughput in terms of tokens/ms, on a single A100.
| Model | 512 | 1024 | 2048 |
|---|---|---|---|
| HF BERT-base (110M) | 206.5 | 130.8 | 71.3 |
| FlashAttention BERT-base (110M) | 380.7 | 359.7 | 265.3 |
| M2-BERT-base (80M) | 386.3 | 380.7 | 378.9 |
Today we’re releasing two initial M2-BERT checkpoints pretrained on short sequences, but M2-BERT has the potential to scale to much longer sequences. We’ve started using these scaling properties to experiment with data recipes for long-sequence M2-BERT’s – stay tuned!
What's Next
- We are releasing code for BERT and checkpoints for 80M and 110M models today, pretrained using a standard recipe at sequence length 128 – stay tuned for longer sequences! Check out our code and checkpoints (80M, 110M).
- In the coming weeks, watch out for further releases, as we train up long-sequence BERT’s and start tracing the history of Transformers forward – on ImageNet, causal language modeling, T5-style models, as well as explorations of the long sequence capabilities
- As part of this release, you’ll find some optimized CUDA code for the forward pass of the M2 layer (which we used for the benchmarks) – we’ll continue to optimize and release updates over the coming weeks. Expect another series of blogs and materials on these soon as we explore the computational tradeoff space!
- And of course, full arXiv coming soon!
Acknowledgments
This work would not have been possible without the full Monarch Mixer team!
Full author list: Daniel Y. Fu, Simran Arora*, Sabri Eyuboglu*, Jessica Grogan*, Isys Johnson*, Armin W. Thomas*, Benjamin F. Spector, Michael Poli, Atri Rudra, Christopher Ré.
This research was conducted with the support of Together AI and would not have been possible without them – thank you! Check out the Together’s blog post about their mission to support the world’s best open source models here.
Glue Numbers
| M2-BERT, 80M | M2-BERT, 110M | |
|---|---|---|
| MNLI | 78.4 / 78.6 (78.5) | (79.6 / 80.5) 80.1 |
| RTE | 68.5 | 69.3 |
| QNLI | 84.6 | 86.0 |
| QQP | 86.7 | 87.0 |
| SST2 | 92.0 | 92.3 |
| STS-B | 86.3 | 86.9 |
| CoLA | 53.0 | 56.0 |
| MRPC | 89.8 | 89.2 |
| Average | 79.9 | 80.9 |