Jan 23, 2023 · 7 min read
H3: Language Modeling with State Space Models and (Almost) No Attention
Dan Fu, Tri Dao, Khaled Saab, Armin Thomas, Atri Rudra, and Chris Ré.
State space models (SSMs) are strong general-purpose sequence models, but have underperformed attention in language modeling. How can we close this gap? In this blog post, we’ll take a look at some critical capability gaps – using some simple synthetic languages of in-context as a guide. We’ll use our understanding to build H3 (Hungry Hungry Hippos), our new SSM layer for language modeling. With H3, we can replace almost all the attention layers in GPT-style transformers while beating or matching quality. We’ve scaled H3 up to 2.7B-parameters, and are releasing weights and code today. Check it out and let us know what you think!
In our partner blog post with Together, we discuss some systems innovations that were key to scaling our training up to billion-parameter models – and giving us inference up to 2.4x faster than Transformers!
Why State Space Models?
State space models (SSMs) are a classic primitive from signal processing, and recent work from our group has shown that they are strong sequence models, with the ability to model long-range dependencies – they achieved state-of-the-art performance across benchmarks like LRA and on tasks like speech generation. However, they have thus far underperformed attention on language modeling.
For the purposes of our blog post, we won’t go into the details of how state space models are defined. We’ll summarize just a few key points:
- SSMs scale with in sequence length, instead of like attention – that makes them promising for long sequence modeling.
- There’s no fixed context window, since SSMs admit a completely recurrent view.
- The behavior of SSMs are primarily determined by a matrix , which is often learned from the data.
If you’re interested in reading further, there’s some great resources and blog posts out there!
The scaling characteristics and good sequence modeling performance suggest that SSMs should be a good candidate to replace attention in language models, but performance has lagged attention. Can we understand why?
Probing the Gap with Attention
In our paper, we turned to the ability to do in-context learning – or not – as the key differentiator between attention and SSMs. We used two synthetic languages – inspired by recent explorations into the mechanistic basis behind in-context learning. We looked at two languages in our paper, but we’ll focus on one for the blog post: associative recall.
| Input | Output | Sequence Length | Vocab Size |
|---|---|---|---|
| a 2 c 4 b 3 d 1 a | 2 | 40 | 20 |
In associative recall, a generative language model is given a string containing pairs of keys and values. In the above example, the keys are a, b, c, and d, and the values are 1, 2, 3, and 4. At the end of the string is a key, and the model has to generate the value associated with the key. In the above example, the value 2 follows the key a, so the model has to generate 2 after seeing a. We’re showing a short sequence above, but we evaluated this synthetic language with strings of 40 tokens, with 20 vocab.
This task is a proxy for in-context learning – a model has to learn to change its output based on a pattern that it sees earlier on in the input. And if we randomly assign key-value pairs to each string, the model can’t learn the key-value associations in its weights. It has to somehow recall the right answer from the input.
When we tried to train small (2-layer) SSMs and attention to do this task using next-token prediction on our synthetic language, we found that attention could do it no problem, but the SSMs had trouble – even the ones designed for language (GSS).
| S4D | GSS | Attention |
|---|---|---|
| 20.1 | 27.1 | 100 |
So that gave us a clue about where a gap might be!
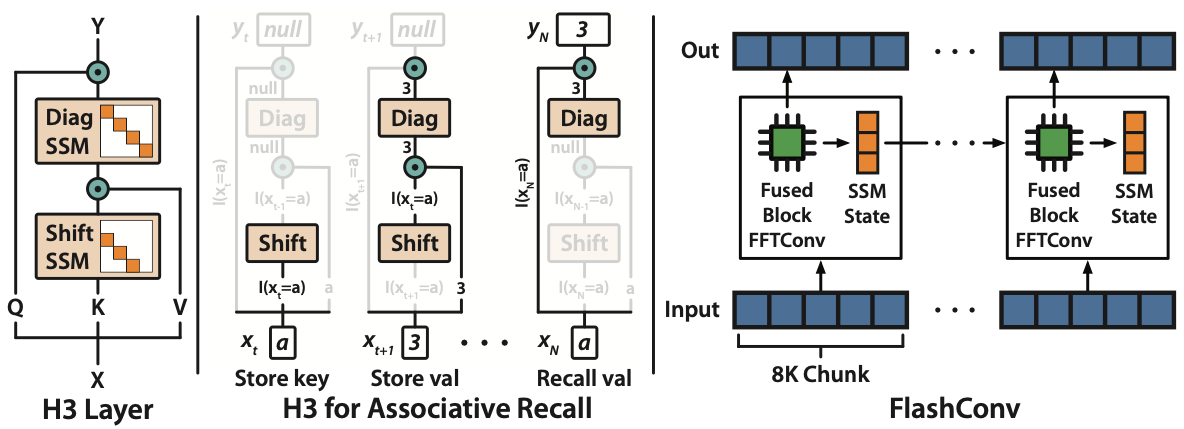
H3 Layer
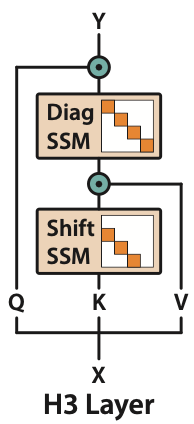
The H3 layer takes three projections of the input, and passes it through a stack of two SSMs. It is designed explicitly to solve associative recall.
So how did we close the gap? We designed a new layer, H3 (“Hungry Hungry Hippos”), designed explicitly to solve associative recall.
There are two capabilities that we need to be able to do associative recall: memorize tokens over the entire sequence, and compare the current token to previous tokens.
We can do memorization by creating an SSM with being a diagonal matrix – similar to approaches like S4D or DSS.
To compare the current token to previous tokens, we create an SSM with being a shift matrix – which in essence creates a state that stores the previous token. Then multiplicative interactions are all you need to do comparisons! This is a similar intuition to approaches like gated state spaces, but the shift SSM (which is not learnable by S4) is critical to do this comparison across the sequence.
Lo and behold, our simple modifications let us solve associative recall!
| S4D | GSS | H3 | Attention |
|---|---|---|---|
| 20.1 | 27.1 | 99.1 | 100 |
Back to Language Modeling: Up to 2.7B Parameters
When we took H3 and used it as a drop-in replacement for attention in language models, we came super close to matching Transformers, within 0.4 PPL at 125M parameters on OpenWebText. This was a lot closer than other SSMs:
| S4D | GSS | H3 | H3 Hybrid (2 attn) | Transformer |
|---|---|---|---|---|
| 24.9 | 24.0 | 21.0 | 19.6 | 20.6 |
And simply adding two attention layers back in (one near the beginning, one in the middle – though we didn’t tune it much), we could outperform Transformers by 1.0 ppl on OpenWebText. Wild!
We took this hybrid variant – replacing almost all the attention layers with H3 layers – and trained a series of language models on the Pile, up to 2.7B parameters. We’re happy to report that we matched or outperformed similar-sized Transformers at every step along the way:
| Model | Pile PPL |
|---|---|
| GPT-2 small (125M) | 19.0* |
| GPT-Neo-125M | 9.4 |
| H3 + 2 attn, 125M | 8.8 |
| GPT-2 Medium (355M) | 13.9* |
| H3 + 2 attn, 355M | 7.1 |
| GPT-2 XL (1.5B) | 12.4* |
| GPT-Neo-1.3B | 6.2 |
| H3 + 2 attn (1.3B) | 6.0 |
| GPT-Neo-2.7B | 5.7 |
| H3 + 2 attn (2.7B) | 5.4 |
In our paper, we also validated that these improvements in perplexity were reflected in downstream zero- and few-shot evaluation.
(*The GPT-2 numbers are not directly comparable, since they were not trained directly on the PILE).
What's Next & Try it Yourself
We’re very excited to see if we can get the magic of large language models without attention – and seeing how our current approaches continue to scale. If you want to take this and train even bigger models – let us know!
Speaking of scale, we also introduced some new systems innovations for speeding up SSMs to get to 2.7B. Check out our post on the Together blog to read about FlashConv!
We’re super excited by these results, so now we’re releasing our code and models to the public! Our models are available on the HuggingFace model hub, and instructions for downloading and running the models are available on our GitHub.
If you give it a try, we’d love to hear your feedback!
Dan Fu: danfu@cs.stanford.edu; Tri Dao: trid@stanford.edu