Mar 7, 2023 · 9 min read
Hyena Hierarchy: Towards Larger Convolutional Language Models
Michael Poli*, Stefano Massaroli*, Eric Nguyen*, Dan Fu, Tri Dao, Stephen A. Baccus, Yoshua Bengio, Stefano Ermon, and Chris Ré.

Hyena cubs are born with their eyes open and can walk within minutes! But also, Hyena is a new operator for large language models that uses long convolutions and gating, reaching attention quality with lower time complexity. (Hyena image generated by lexica.art)
We're excited to share our latest work on Hyena, a subquadratic-time layer that has the potential to significantly increase context length in sequence models, using a combination of long convolutions and gating.
We love Attention
Attention is great – it powers many of the most exciting AI models, from ChatGPT to Stable Diffusion. But is it the only way to reach scale or unlock amazing capabilities such as in-context learning? This seems like a fundamental question for AI. Are these abilities rare or all around us? We started this work because we just want to know!
More practically, while attention is amazing, it does have some drawbacks. Attention is fundamentally a quadratic operation, as it compares each pair of points in a sequence. This quadratic runtime has limited the amount of context that our models can take. In the approaches we’ll discuss below, we started to think about models that can handle sequences with millions of tokens–orders of magnitude longer than what Transformers can process today. (e.g, imagine feeding ChatGPT a whole textbook as context and reasoning about it in a zero-shot setting, or having as context every keystroke you’ve ever written, or conditioning a patient’s entire health record. Sounds amazing!) Below, we’ll talk about one path (potentially of many!) that might get us there, and it is based on ideas from signal processing.
Over the past few years, we've been laser focused on long sequential data, such as time series, audio and more recently language [S4, H3]. These domains are notoriously challenging for attention, since your typical Transformers are trained to process sequences of at most 8k elements - although some adventurous researchers and developers are beginning to train models with context lengths of 32k or even 64k, thanks to recent advances in efficiency and memory scaling [Flash Attention].
Pushing Sequence Lengths to the Limit
We're excited to share our latest work on Hyena, a subquadratic-time layer that has the potential to significantly increase context length in sequence models. This work would not have been possible without remarkable advances in long sequence models [S4, RWKV, H3], alternative parameterizations for long convolutions [S4, CKConv, SGConv], and inspiring research on mechanistic understanding of Transformers [Olsson et al., Power et al., Nanda et al.].
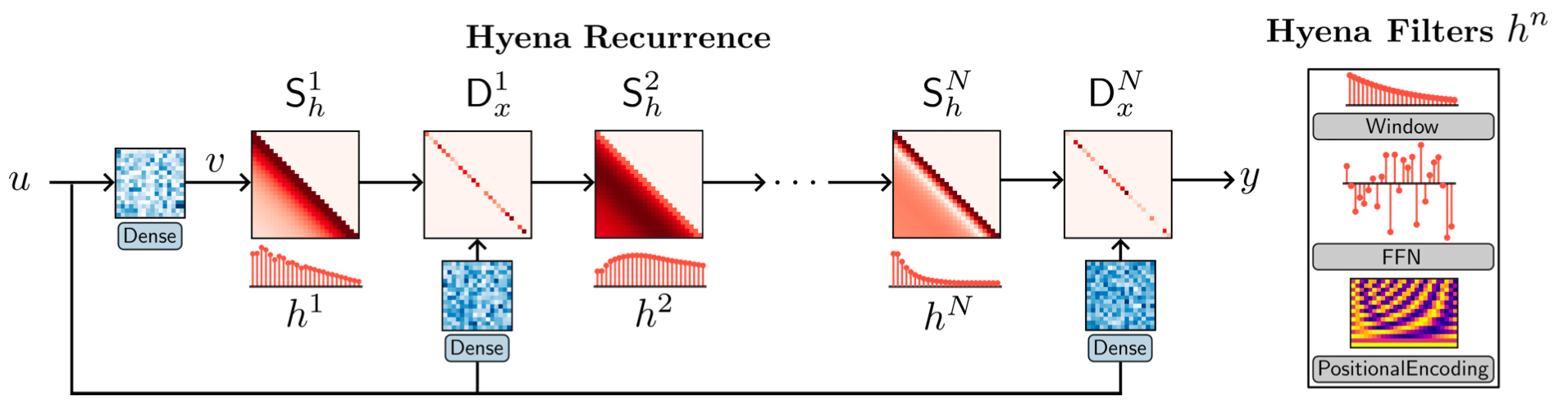
The Hyena operator is defined as a recurrence (controlling layer size) of two efficient subquadratic primitives: an implicit long convolution (i.e. Hyena filters parameterized by a feed-forward network) and multiplicative element-wise gating of the (projected) input.
Mechanistic Design to the Rescue
Our starting point is the rich literature on attention-free, subquadratic-time architectures. Recent developments in state-space models for language modeling have shown us that with just a little bit of attention - at most a few layers - we can match the quality of fully-attentional models up to the 2.7 billion parameter scale. However, fully removing attention from these new models (and training with the same tokenizer!) reveals a gap:
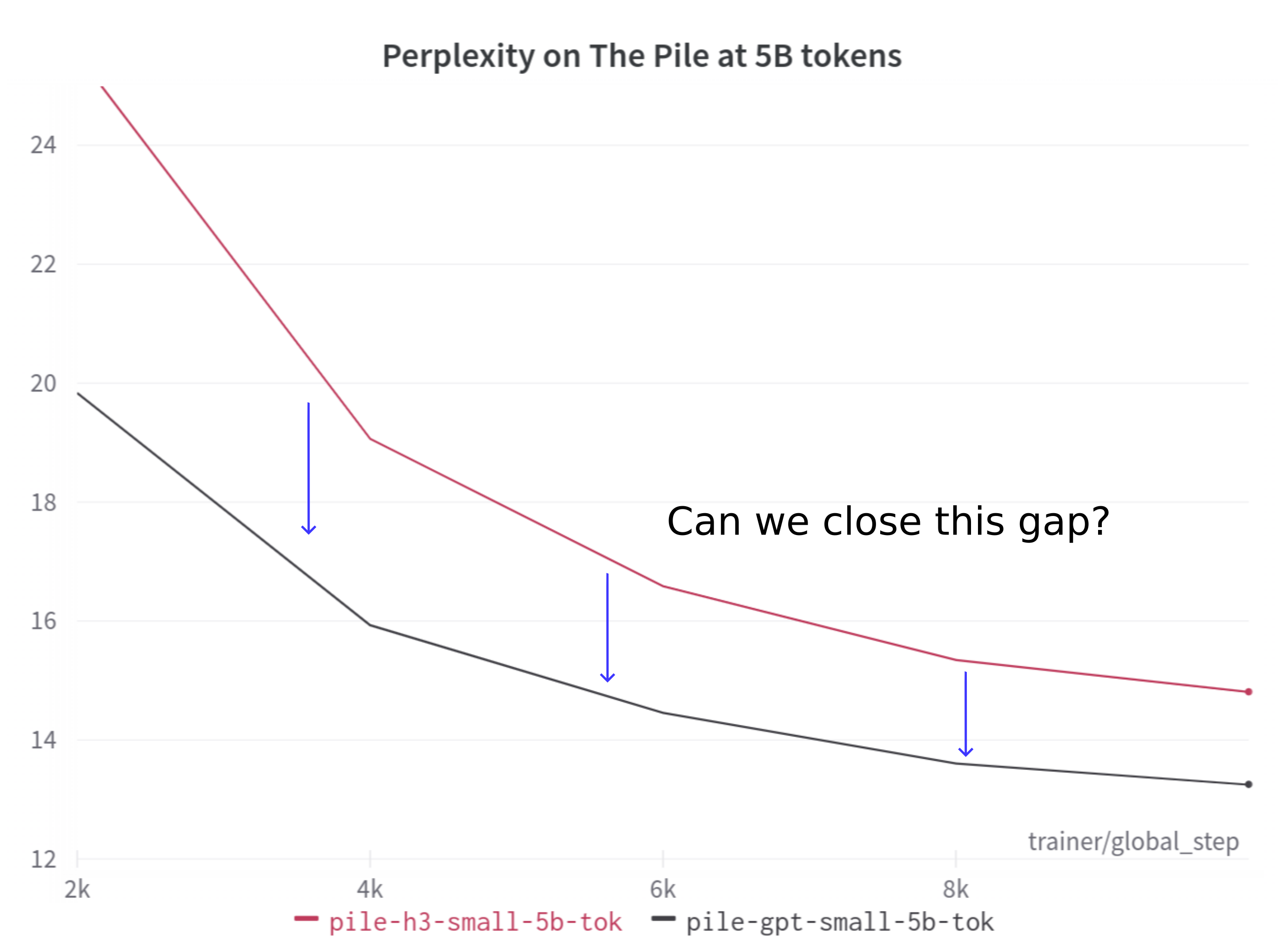
Previous subquadratic alternatives to attention (e.g., [H3]) reveal a gap in perplexity for language modeling. We aim to close this gap.
These last few attention layers have been bothering us. Is there computation required by our large-language models that is fundamentally quadratic (i.e., involving all possible pairwise comparisons)? At this point, one may begin to wonder if any attempt to find an effective alternative to attention is doomed from the start. A variety of attention replacements have been proposed over the last few years, and it remains challenging to evaluate the quality of a new architecture during the exploratory phase.
We found our breakthrough by scaling down the problem. Based on the groundwork done by [H3] on using synthetic tasks for model design, we put together a collection of string manipulation and in-context learning tasks that take at most a few minutes to run on common hardware configurations, and use them to search for quality gaps between architectures.
For example, by measuring how well models are able to perform associative recall in increasingly challenging settings (larger vocabularies and longer sequences), we see some correlation with pretraining loss on The Pile:
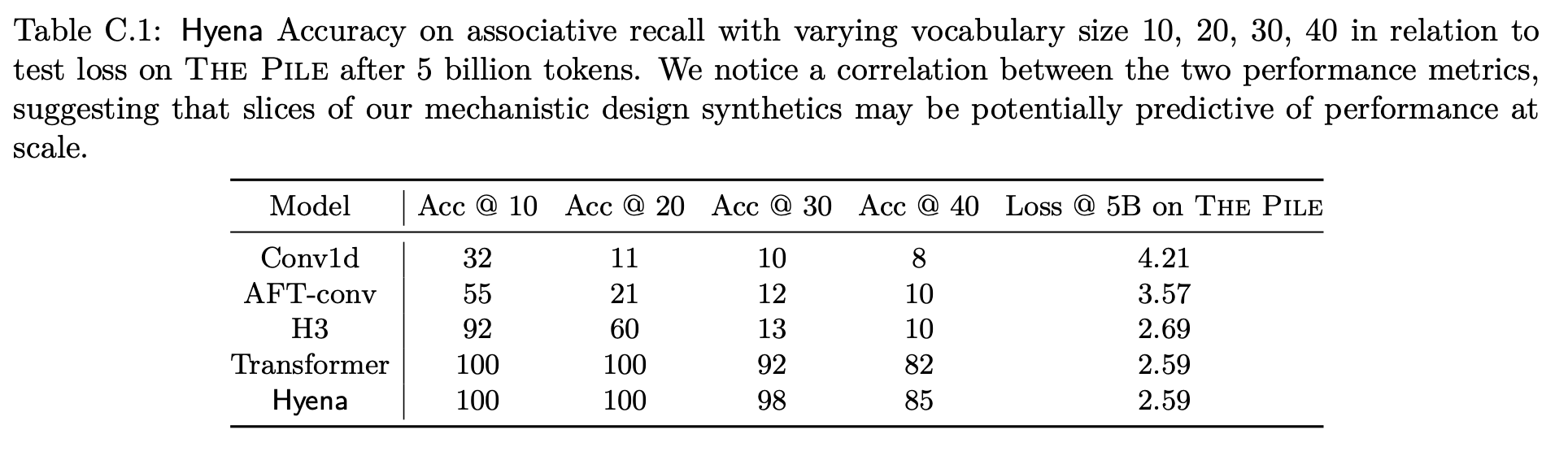
We can learn a lot from associative recall using synthetics.
Although a variety of layers are capable of learning to recall and count (including staples such as RNNs!), we were surprised to see these performance differences mirror results found at different scales. The natural question was then: how do we shrink these gaps further?
Attention, Data-Control and Hyenas
One remarkable property of the attention layer is that it is data-controlled (or data-dependent):
The matrix of the operator is formed on the fly, constructed as a particular function of the input. After training a variety of attention-based models, it becomes apparent that without data-control, any kind of in-context learning becomes much more challenging.
Could we strengthen the data-control path in our attention-free layers? That is, is there a way can we ensure different inputs can steer our layer to perform substantially different computation?
Enter Hyena:
x, v = input_projections(u)
for o in range(hyena_orders):
h = hyena_filter(L) # long conv filter parameterized via an MLP
v = x[o] * fftconv(h, v) # elem-wise mult & fftconv
)
With Hyena, we define a different data-controlled linear operator that does not compute explicitly, but instead defines an implicit decomposition into a sequence of matrices (evaluated via the for-loop above). And some exciting news for signal processing fans: we find filter parametrization (and custom input projections!) to be one of the most impactful design choices, and come up with some recommendations. More on this soon!
How about speed? Every step can be evaluated in subquadratic-time, and we only need very few “orders” (at most 3) in our experiments. The crossover point between highly optimized FlashAttention and Hyena is at about 6k sequence length. At 100k sequence length, Hyenas are 100x faster!
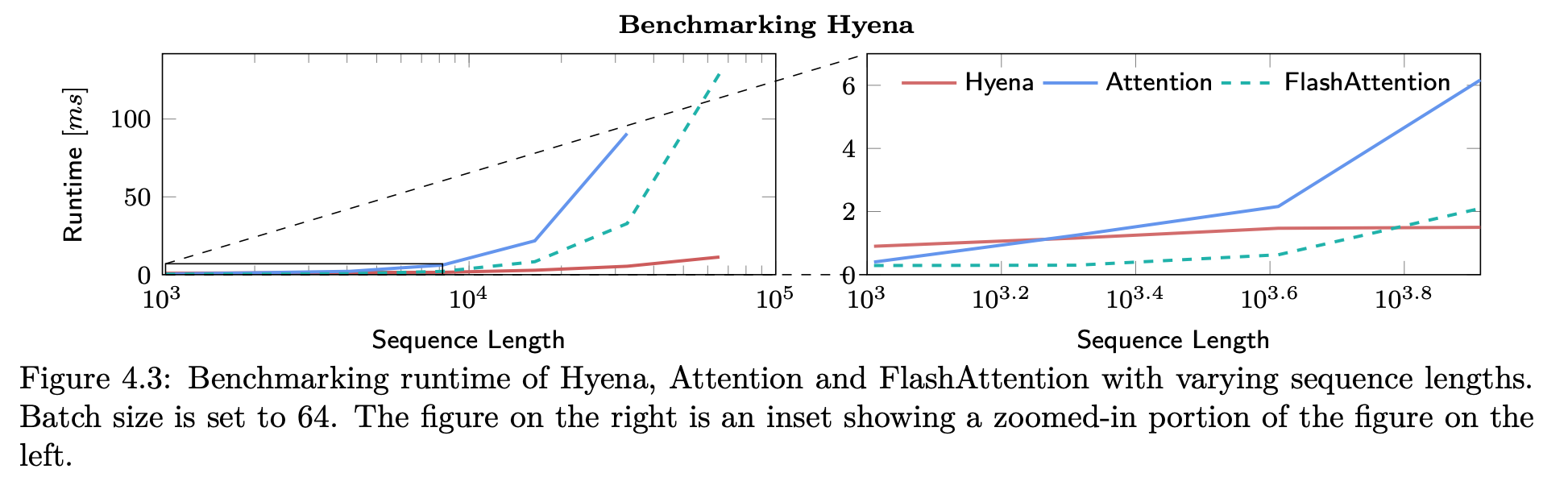
Runtime vs sequence length benchmarks.
With a way to measure progress on our small mechanistic design benchmarks, we refine the design of Hyena, and observe that particular parametrizations of the long convolutions scale more favorably in sequence length and vocabulary size, especially when paired with shorter explicit filters:
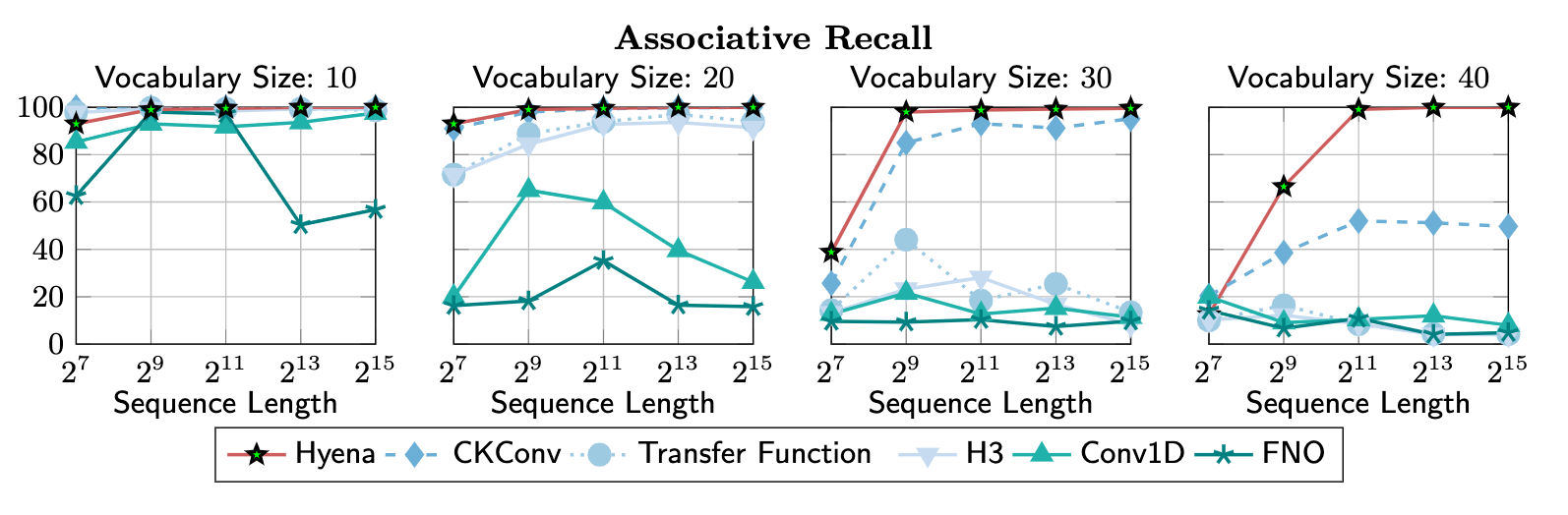
Associate recall benchmark by implicit (and 1 explicit) parameterizations.
This should not be too surprising – we know neural networks to be more expressive than other function classes, and the same observation holds for parametrizations of convolutional filters. For example, neural fields are now widely adopted in many graphics and compression applications due to their ability to accurately fit many signals.
Hyena on Language
We set out to evaluate Hyenas on a variety of tasks, including language modeling at scale (on Wikitext103, The Pile, PG-19), and downstream tasks such as SuperGLUE.
On The Pile, we see the performance gaps with Transformers start to close, given a fixed FLOP budget. (Hyenas are crafty creatures: they don't leave perplexity points on the table!)
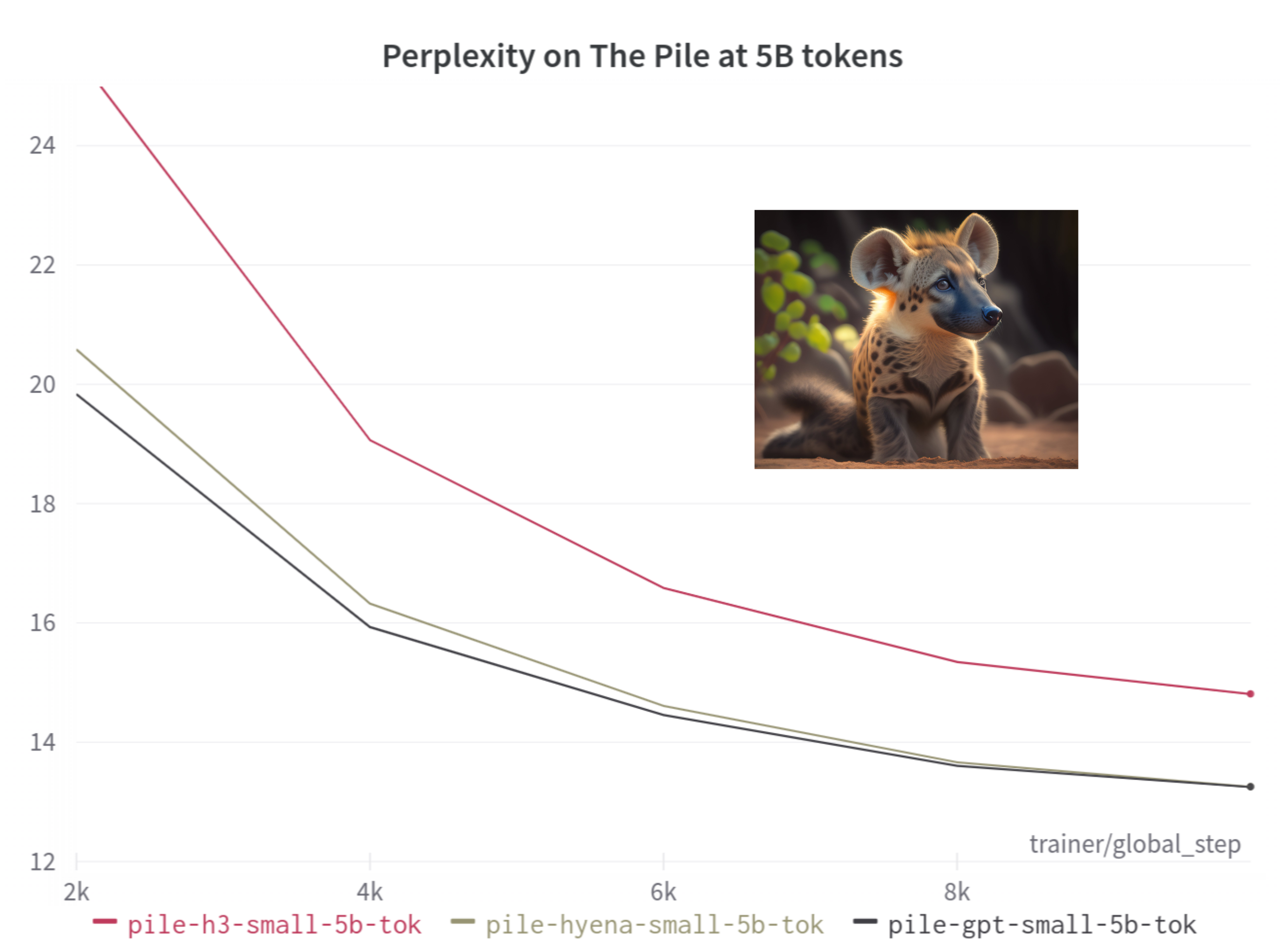
Comparing perplexity on the Pile for H3, Hyena, and GPT. As context length increases, Hyena closes the gap with
With larger models, we reach similar perplexity as a regular GPT architecture with a smaller FLOP budget. On the standard long-range language benchmark PG-19, we train Hyena with 16k context and reach a perplexity 14.6. We also perform downstream evaluations on several zero and few-shot tasks. (Turns out Hyenas are pretty good few-shot learners too!)
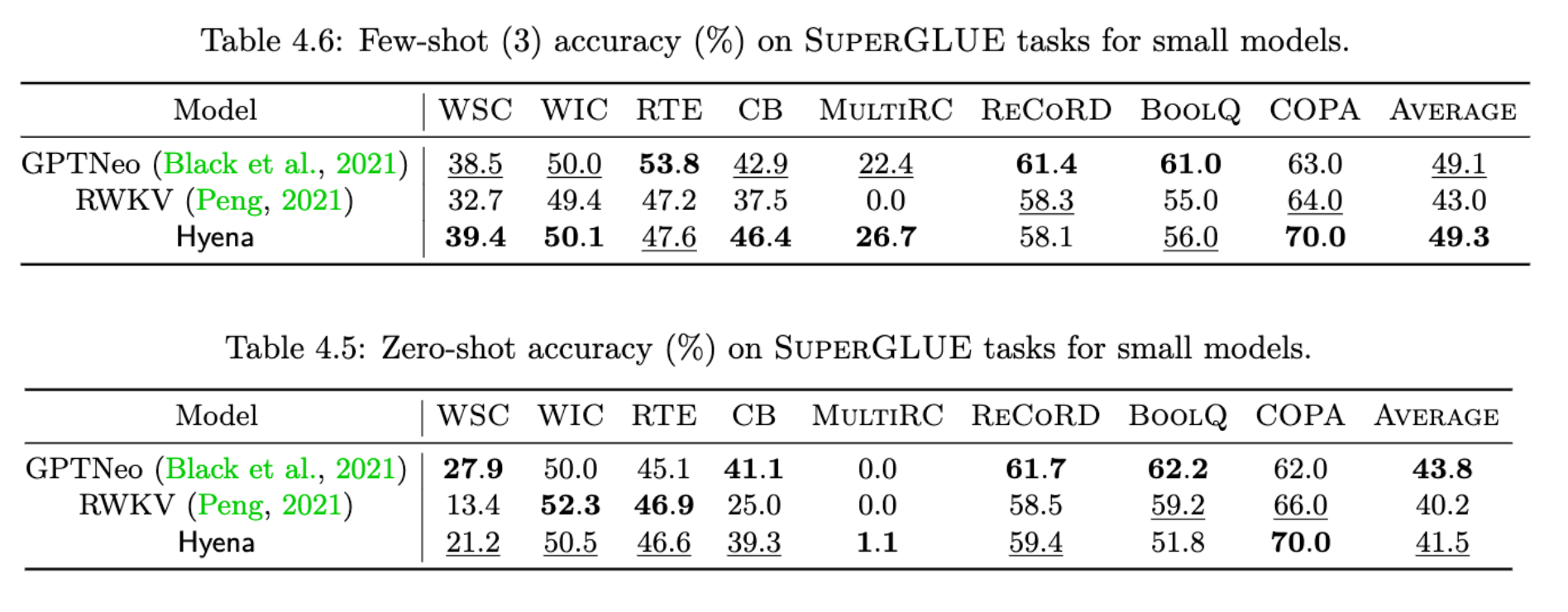
Hyena few and zero-shot performance on SuperGLUE.
Hyena on Vision
Similarly to attention, Hyena can be used in Vision Transformers. Hyena matches Transformer performance on ImageNet, suggesting that mechanistic design benchmarks may be informative of performance beyond language – perhaps in many domains where attention “simply works”?
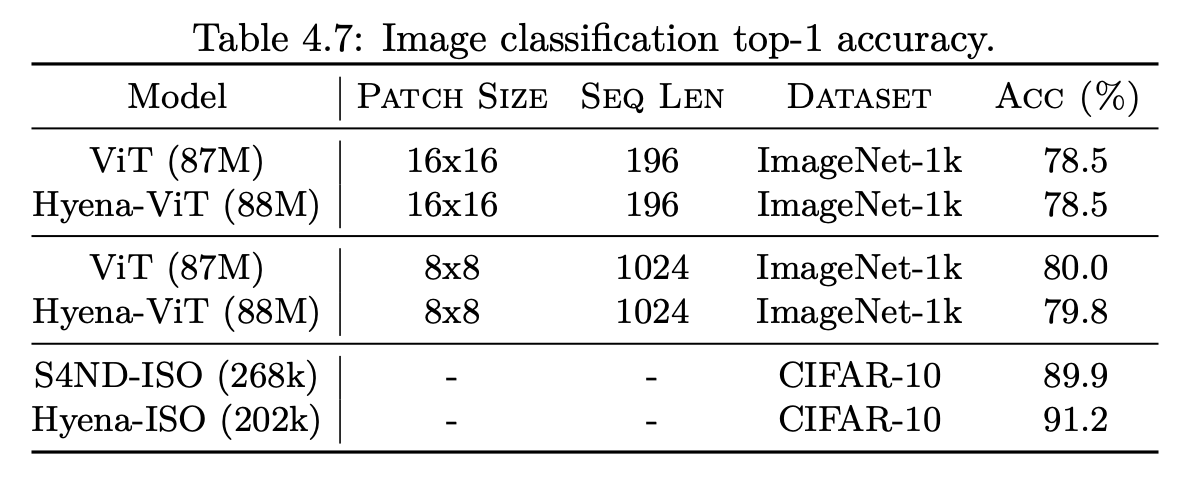
Hyena in Vision Transformers can match attention.
What’s Next
With Hyena, we’re just scratching the surface of what can be achieved with models grounded in signal processing and systems principles, along with iterative design using curated synthetic tasks. We’re excited to push training to even longer sequence lengths (1 million!), test on new domains, and accelerate inference by switching to a recurrent view – in the spirit of the state passing method employed by H3, or the RWKV recurrence. With longer context models, we hope to enable the next phase of breakthroughs in deep learning!
Contact Us
We'd love to hear from you about exciting applications and challenges that could benefit from long sequence models!
Michael Poli: poli@stanford.edu; Stefano Massaroli: stefano.massaroli@mila.quebec; Eric Nguyen: etnguyen@stanford.edu
Acknowledgments
Thanks to all the readers who provided feedback on this post and release: Karan Goel, Albert Gu, Avanika Narayan, Khaled Saab, Michael Zhang, Elliot Epstein, Sabri Eyuboglu and Winnie Xu.
Fun facts about Hyenas (the animal)
- A group of hyenas is called a "cackle" or "clan" [source].
- "The society of the spotted hyena is matriarchal, meaning that females are larger, stronger and more aggressive than males" [source].
- Hyenas have incredibly strong jaws and teeth (1100 PSI), which can crush bones and digest them (that's pretty scary) [source].
- "Spotted hyenas are known as 'laughing hyenas' because they have a distinctive call that sounds like human laughter. They make this sound when they are excited, but nervous, or when they are submitting to another hyena" [source].