Apr 20, 2023 · 6 min read
Understanding the Ingredients in ChatGPT is Simpler Than You Think
I get the privilege of speaking to folks from a large number of backgrounds including executives, policy makers, and the AI curious, who want to know what GPT is, why they should care, and what might happen next. This article is intended to give you a simple working model of AI systems like ChatGPT. Understanding how a system like ChatGPT is built (or trained in our jargon) is in some ways a lot simpler than you might expect. Explaining why and when it works well is a really complex problem, but mechanistically it’s beautifully simple. One way to view the big change in AI is not that pipelines have gotten more complex–but that AI pipelines have gotten a lot simpler over time. They have fewer moving parts, and the simplified version described in this post is surprisingly accurate!
What will this quick article cover?
- By the end of this short article, you’ll know what GPT means. The GPT in GPT-3, GPT-4, or ChatGPT is an acronym for “Generatively Pretrained Transformers.” A lot clearer now, right?!? By the end of this article, you’ll know exactly what this jargon means.
- You’ll also understand why your data is the star of the show as we move from the era of GPT-X to GPT-You1. The next models will start as generalists, like GPT-X, and then learn more about you: your business, your science, your interests, i.e., GPT-You.
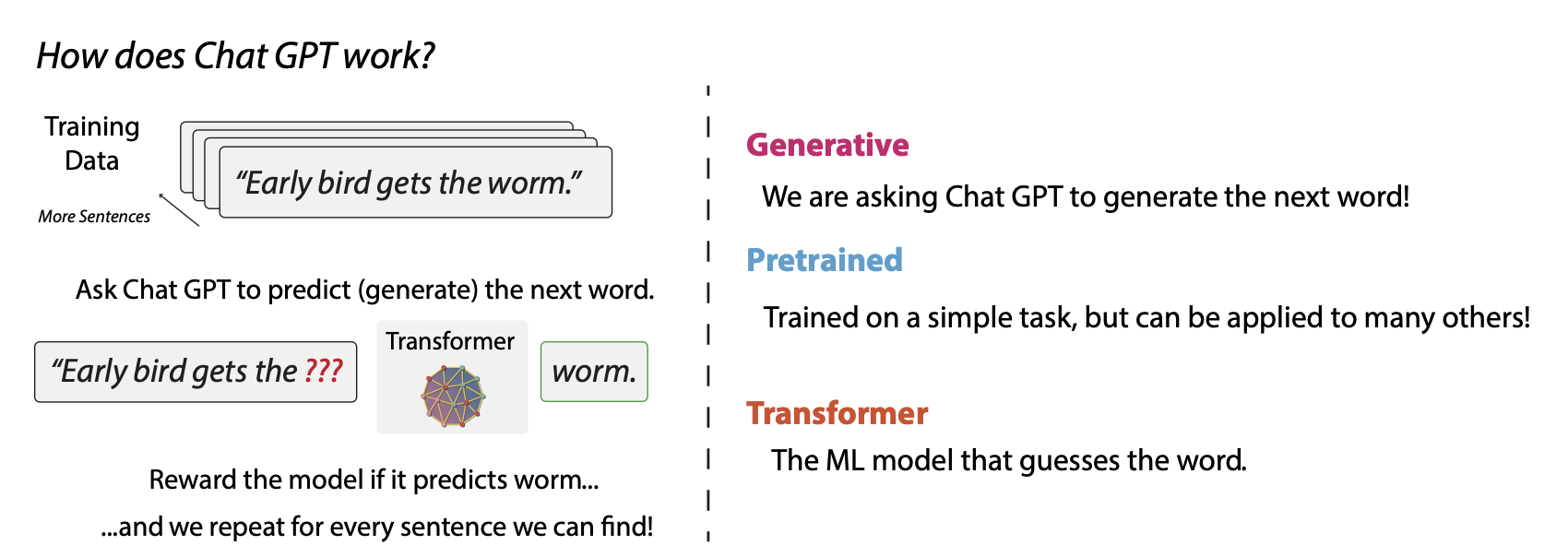
The New Pipeline for AI.
- You put in a sentence “The early bird gets the worm.”
- The AI’s goal is to “predict” that sentence from left to right. So, for example, it shows itself “The early bird gets the __” and it tries to fill in the blank. If the AI guesses “worm”, it gets a reward.2
You do this for many sentences, and you have a state-of-the-art AI.
Seriously.
A few things to notice about this pipeline as summarized in the image.
- Generative. Since the model is trained to fill in the blanks, you can ask it, like your phone’s autocomplete on steroids–to just keep completing or generating words into entire sentences or paragraphs! This is why we nerds like to call it “generative”, and this is the G in GPT.
- Pretrained. Notice, we didn’t tell the AI to be good at any real task. In the old days of machine learning, we had to scope the task for a system very precisely: recognize positive and negative sentiment in tweets from Finnish teenagers, or extract long-term interest rate exposure from a company's 10k filing. Collecting and refining this data was hugely painful, and we had to train a model from scratch for each task. The idea of pretraining was training before we saw any tasks. Currently, these models are the first-mile, and the last mile is coming.
- Transformers. This is a funny one: most AI on the planet uses a model made by folks formerly at Google, called the Transformer. This model was a huge landmark. Effectively, a transformer model’s job is to compress all the data it’s seen to make an informed prediction of the word. How it does so is amazing, it’s more than just storing everything it’s seen, these models seem to learn “abstractions” that help them somewhat reason in novel situations. This is what is so exciting (we call this generalization). Wild!3
Now what are the consequences of our cartoon understanding? One obvious thing is that the only input is the data. It turns out that the rest has become a commodity, and many groups can now train these models. Most of science suffers from a replication crisis, but here we have an anti-replication crisis–these models just work–thanks to the contributions of many folks in academia and industry. To a first approximation, the main activity over the last few years was to run this pipeline on every sentence on the web (or your emails, reports, etc.!) and repeating this with models that got larger and larger. We might be hitting the end of the era of purely scaling model size, but for several years bigger was just better! To be clear, a few years ago this was a gigantic mystery but many folks contributed their little bricks, and OpenAI showed us an exciting way these models could be used. Now, we train smaller models on trillions of words.
So what about your data? Well, data is the only input–but the public web is used to train this data, and it doesn’t contain information about your and your business. Modifying the data is really the only way you program these models–you choose what data to feed them. This is part of what’s called Data-Centric AI (coined by the same Alex). Now, does the data diet you feed these systems matter? Yes! There is a subtle issue involving how you balance the proportions of different data, the quality of the data, the deduplication wait…. which is a really fancy way of saying: we really don’t fully understand the data, and it hasn’t commoditized. This isn’t really surprising, since data is just a recording of every human activity. These models make it easier to use every bit of your digital exhaust to train a model, but you still have to pick which digital exhaust to train them on.
But common sense (and empirical results!) says that training on data that is more similar to your use cases yields a model better suited to you. The current breed of models are great generalists but less than perfect specialists–and certainly not the most efficient way to be specialists. They need to be specialized to your particular operating environment. This is why we say the next area is not GPT-X but GPT-You–AIs that know about your data and your business. For more on that, check out this expanded article.
Footnotes
- Shamelessly stolen from my former student and CEO of Snorkel, Alex Ratner.↩
- It does this for each word in every sentence you feed it. Sadly, instead of getting a reward, the terminology is that it “suffers” a penalty, if it guesses the wrong word. Grim, and it suffers a lot for its art.↩
- The transformer is the first model the community got to work, but it seems like a ton of different variants might have gotten us there! More nerd details in “Is AI rare or everywhere?”, and there are reasons to hope we can build less expensive, higher quality models. As they say, the world runs on hope!↩