
About
Bootleg is a self-supervised named entity disambiguation (NED) system that links mentions in text to entities in a knowledge base. Bootleg is built to improve disambiguation of entities which appear infrequently or not at all in training data, called tail entities. The tail is where disambiguation gets interesting as models cannot rely on learned textual cues for entities rarely seen in train. As shown in the figure below, this is why a BERT-based baseline, which memorizes co-occurrences between entities and text to disambiguate, struggles over the tail.
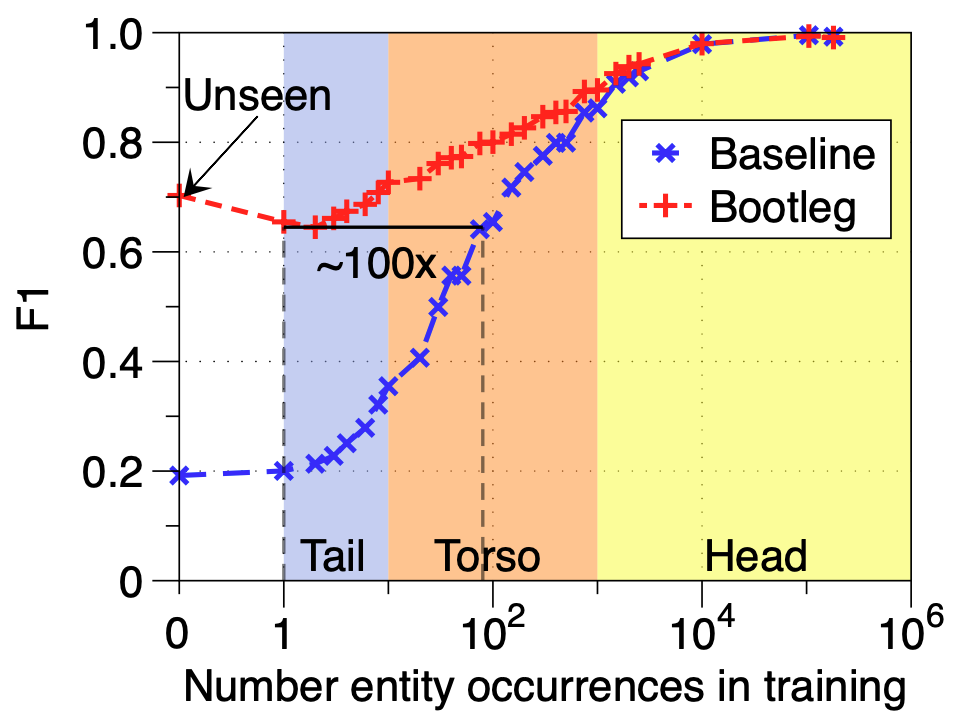
The simple insight behind Bootleg is that resolving the tail requires subtle reasoning over type and relation signals. In Bootleg, we take an "embedding-centric" approach and represent types, relations, and entities as learned embeddings in a Transformer-based architecture. Critically, all entities of the same type (or relation) get the same type (relation) embedding, meaning all entities, including the tail entities, can leverage the signals learned for all entities of that type (relation). This is what allows for Bootleg to better disambiguate tail entities than models that rely only on textual patterns.
Bootleg is still in active development, but is already in use at industry and research labs.
Getting Started
For help getting started with using Bootleg, check out our open-source code, tutorials, and paper.Results
Bootleg achieves state of the art on NED benchmarks and improves over a standard BERT NED baseline by over 40 F1 points on the tail of Wikipedia, which we define as entities occurring 10 or fewer times in our Wikipedia training data. As a fun experiment, we extracted Bootleg's learned representations and integrated them into a SotA model for TACRED1. This Bootleg-enhanced TACRED model set a new SotA by 1 F1 point. See our paper for details.NED Benchmarks
We compare the newest version Bootleg as of October 2020 against the current reported SotA numbers on two standard sentence-level benchmarks (KORE50 and RSS500) and the standard document-level benchmark (AIDA CoNLL-YAGO).
| Benchmark | System | Precision | Recall | F1 |
|---|---|---|---|---|
| KORE502 | Hu et al., 20195 | 80.0 | 79.8 | 79.9 | Bootleg | 86.0 | 85.4 | 85.7 |
| RSS5003 | Phan et al., 20196 | 82.3 | 82.3 | 82.3 | Bootleg | 82.5 | 82.5 | 82.5 |
| AIDA CoNLL YAGO4 | Fevry et al., 2020 | - | 96.7 | - | Bootleg | 96.9 | 96.7 | 96.8 |
Tail Performance
We also evaluate the performance of Bootleg on the tail compared to a standard BERT NED baseline. We create evaluation sets from Wikipedia by filtering by the frequency of the true entities in the training dataset and report micro F1 scores. The slight increase in performance over unseen entities compared to tail entities is due to the lower degree of ambiguity among the unseen entities compared to the tail entities.
| Evaluation Set | BERT NED Baseline | Bootleg |
|---|---|---|
| All Entities | 85.9 | 91.3 | Torso Entities | 79.3 | 87.3 | Tail Entities | 27.8 | 69.0 |
| Unseen Entities | 18.5 | 68.5 |
References
1Christoph Alt, Aleksandra Gabryszak, Leonhard Hennig . "TACRED Revisited: A Thorough Evaluation of the TACRED Relation Extraction Task." In ACL, 2020.
2Johannes Hoffart, Stephan Seufert, Dat Ba Nguyen, Martin Theobald, and Gerhard Weikum. "Kore: keyphrase overlap relatedness for entity disambiguation." In CIKM, 2012.
3 Daniel Gerber, Sebastian Hellmann, Lorenz Bühmann, Tommaso Soru, Ricardo Usbeck, and Axel-Cyrille Ngonga Ngomo."Real-time rdf extraction from un- structured data streams." In ISWC, 2013.
4Johannes Hoffart, Mohamed Amir Yosef,Ilaria Bordino,Hagen Fürstenau, Manfred Pinkal, Marc Spaniol, Bilyana Taneva, Stefan Thater, and Gerhard Weikum. "Robust disambiguation of named entities in text." In EMNLP, 2011.
5Shengze Hu, Zhen Tan, Weixin Zeng, Bin Ge, and Weidong Xiao. "Entity linking via symmetrical attention-based neural network and entity structural features." Symmetry, 2019.
6 Minh C. Phan, Aixin Sun, Yi Tay, Jialong Han, and Chenliang Li. "Pair-linking for collective entity disambiguation: Two could be better than all". In TKDE, 2019.
7 Thibault Févry, Nicholas FitzGerald, Livio Baldini Soares, and Tom Kwiatkowski. "Empirical evaluation of pretraining strategies for supervised entity linking." In AKBC, 2020.