May 12, 2024 · 4 min read
ThunderKittens: A Simple Embedded DSL for AI kernels
(This post is an extended introduction to a longer post we're releasing concurrently.)

We have a lot of fun building kernels for AI, and we’re proud of our open-source AI contributions. We’re less proud that people regard FlashAttention as alien technology. In a NeurIPS keynote, our group tried our best to make the key ideas simple – but the gap from the beautiful pictures generated by Dan Fu to actual “gpu go brr” cuda is still too damn high. So we set out to write a simple framework to make it really easy to express the key technical ideas. Relatively quickly, we had a small library (DSL?) that we called ThunderKittens that we hope lets us write simple-to-understand clean code that indeed makes gpus go brrr.[1]
{kind=link}
{kind=link}
Our observations for TK are pretty simple:
- You want to keep tensor cores busy. These things are 94% of the compute on an H100, so if you don’t use them you’re capped at 6% utilization. In TK, we make the fundamental object a matrix (tile) of the same size that fits into the tensor core.
- We want something familiar to AI people. So we want an API that is PyTorch-like, because those folks are amazing and we love them!
- We wanted to get the full power of the host (cuda or hip), and we don’t want to hide how accelerators work. We think accelerators are awesome and more AI people should play around at this intersection. Pragmatically, AI processors are changing a lot – they have to! – but this means to take advantage of the latest and greatest you need to break out of software abstractions. So, TK is an embedded DSL somewhere between NVIDIA’s cute (in being embedded in raw cuda) and Triton (in being focused on AI kernels). If you know cuda, you can probably “compile” TK in your head–we try to make the structures transparent.
You may have seen oblique references to TK in some of our earlier papers, e.g., based. We’ve been using it, so... why are we releasing it now? We don’t know honestly. But here are some things we think are interesting:
- On 4090s and A100s, TK matches FA2 performance in just a few lines of code.
- On H100s, TK is faster forward and backward than FA2 by quite a bit -- so there is no tradeoff of clean versus speed (in this case!)
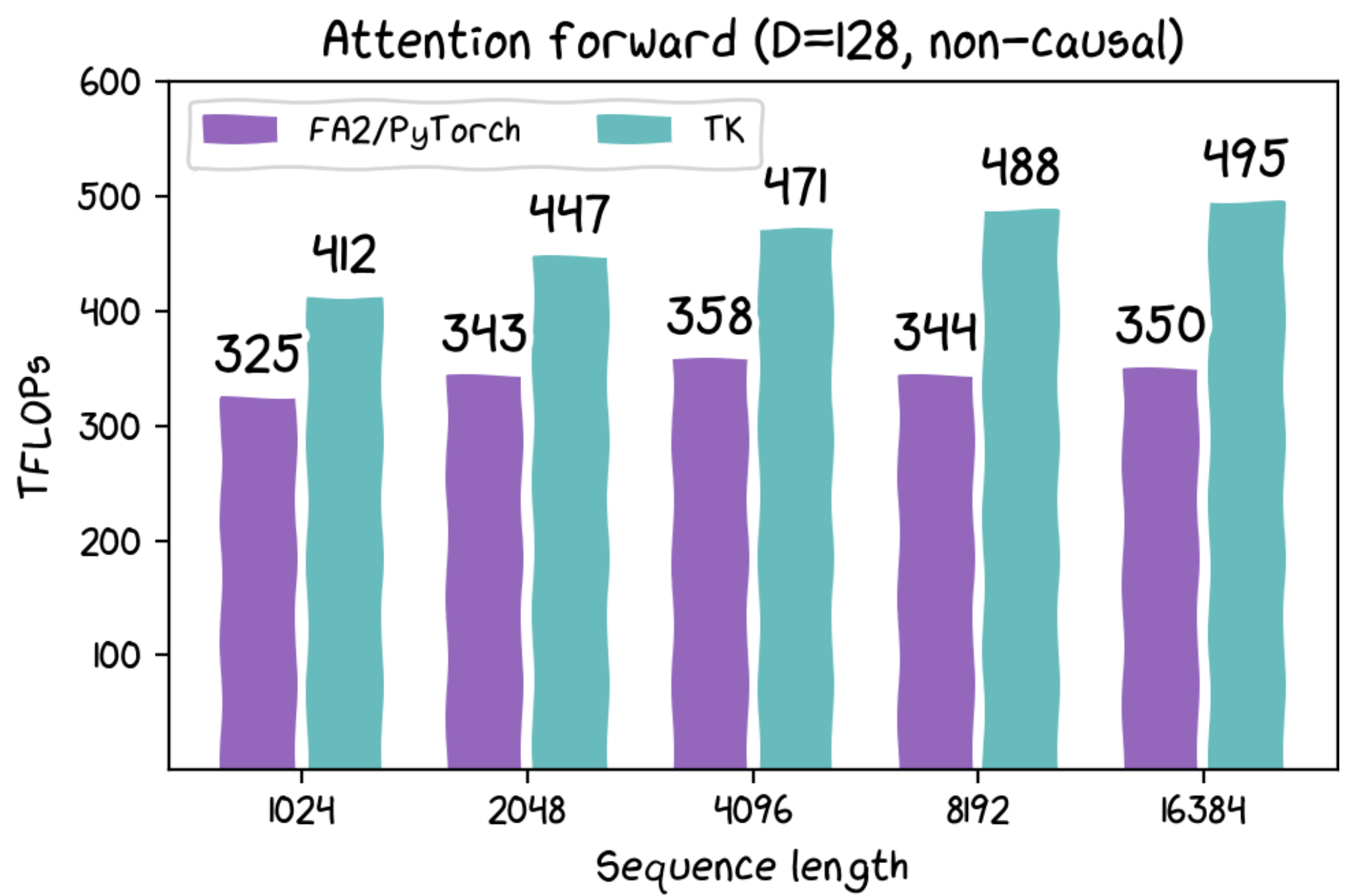
- The lab folks wrote a bunch of other kernels in TK things like Based, hedgehog, and more! Some of them we couldn’t figure out how to get similar performance in Triton.
- AI folks who attended a two-hour cuda session have been able to write code, which is one step toward making this easier to use.
We do want you to understand that this is an art project; if you like it, great! If you don’t, that’s ok too… feedback is great! But do not expect that we’ll do anything about your complaints in the code. For now, TK is for our fun and useful for us, and we hope it makes key ideas clear. To help in that way, we’re posting a version integrated with Andrej’s awesome NanoGPT project, NanoGPT-TK. Andrej is one of the best communicators in AI and we’ve been using NanoGPT in teaching, so we’re delighted to build on top.
For a harder, better, faster, stronger, more detailed blog post, click!
[1] Why ThunderKittens? We wanted something that was adorable and cute, and there are too many macho head games in the current names. Let’s be fun and welcoming!