Jan 11, 2024 · 17 min read
Long-Context Retrieval Models with Monarch Mixer

Text embeddings are a critical piece of many pipelines, from search, to RAG, to vector databases and more. Most embedding models are BERT/Transformer-based and typically have short context lengths (e.g., 512). That’s only about two pages of text, but documents can be very long – books, legal cases, TV screenplays, code repositories, etc can be tens of thousands of tokens long (or more). Here, we’re taking a first step towards developing long-context retrieval models.
We build on Monarch Mixer (M2), a recent model family developing attention- and MLP-free BERT models, which are enabling long-context BERT models. Today, we’re releasing a preview of a few models: long-context versions of M2-BERT up to 32K context length, as well as embedding versions fine-tuned for long-context retrieval. In this blog, you’ll hear about the changes to data mixture and loss function we needed to enable these new models.
We’re also releasing the V0 of a long-context retrieval benchmark called LoCo, that we’ve started to use to evaluate the long-context properties of various retrieval models.
Check out code here, and models up on HuggingFace here:
These models are also available on Together AI’s new embedding service – check it out here! Thanks to our collaborators at Together, we were able to beta-test these models at a MongoDB hackathon, and we already have early RAG integrations with LangChain and LlamaIndex.
We’ll have a full paper out next month – but for now, we wanted to release a preview to get early feedback from the community. Here are some particular calls to action for feedback if you’re interested in long-context retrieval:
- If you have long-context retrieval tasks, we would love to hear how the M2-BERT retrieval models perform in the wild!
- If you have public long-context retrieval tasks or datasets that you think would be good additions to LoCo, please let us know. We’ve only included a few retrieval tasks that have long documents, but we want to grow the benchmark to be more representative!
In the rest of this blog post, we’ll give a brief overview of Monarch Mixer, discuss the technical challenges involved in developing a long-context retrieval model (data mixtures, loss functions, model evaluation), and go over some early results from LoCo V0!
Monarch Mixer (M2)
First, we’ll give a very brief overview of Monarch Mixer. Check out Dan’s MLSys Seminar and the paper for more details!
Monarch Mixer (M2) is a recent model that aims to improve the scaling properties of Transformers along two axes – sequence length and model dimension. For context, Transformers scale quadratically in sequence length (due to attention) and model dimension (due to MLP layers). That means that it’s expensive to scale Transformers (like BERT-based embedding models) to long sequences. This also explains why scaling Transformers up results in so many parameters.
M2 aims to change these scaling properties by replacing attention and MLPs with a single sub-quadratic primitive: Monarch matrices. Monarch matrices are a family of block-sparse matrices defined as block-diagonal matrices, interleaved with permutations:
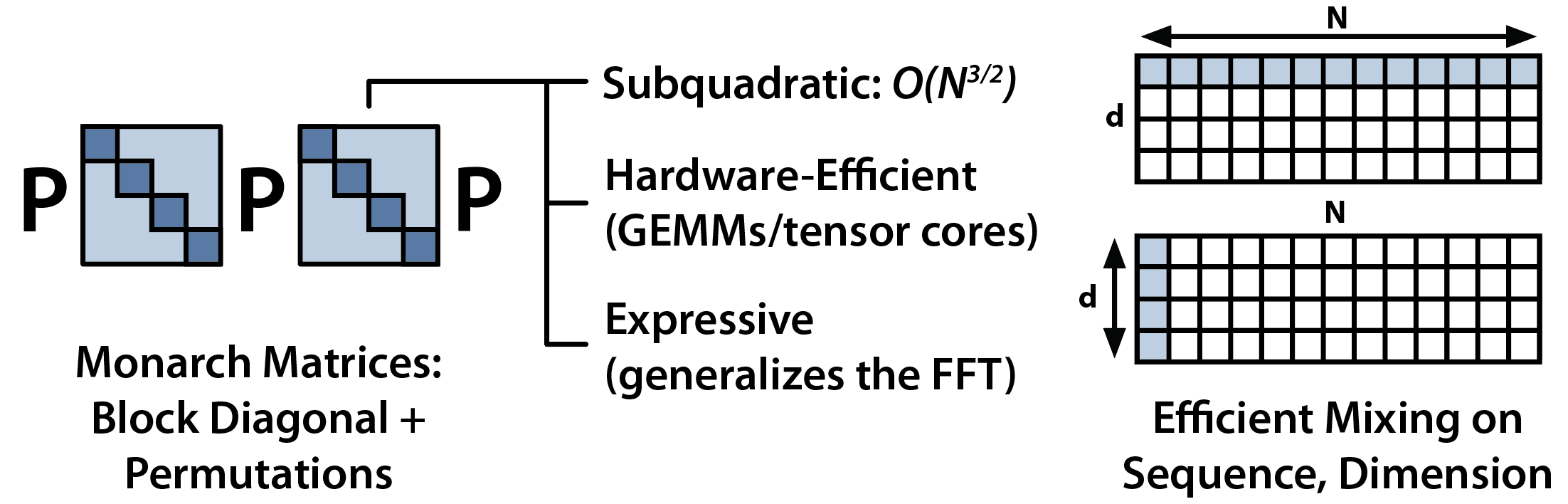
Monarch Mixer uses Monarch matrices to mix data across the sequence and hidden dimension.
Monarch matrices are a sub-quadratic primitive (you can compute them in ) that are also hardware-efficient and expressive. The block-diagonal matrices map onto tensor cores, and the permutations generalize the Fast Fourier Transform. As a result, Monarch matrices can efficiently capture all sorts of structured linear transforms:
Monarch matrices can capture many structured linear transforms, including Toeplitz, Fourier, Hadamard, and more.
In M2, we use Monarch matrices to replace both attention and MLPs in Transformers. We replace attention by using Monarch matrices to construct a gated long convolution layer, similar to work like H3, Hyena, GSS, and BiGS. Specifically, Monarch matrices can implement the FFT, which can be used to compute a long convolution efficiently:
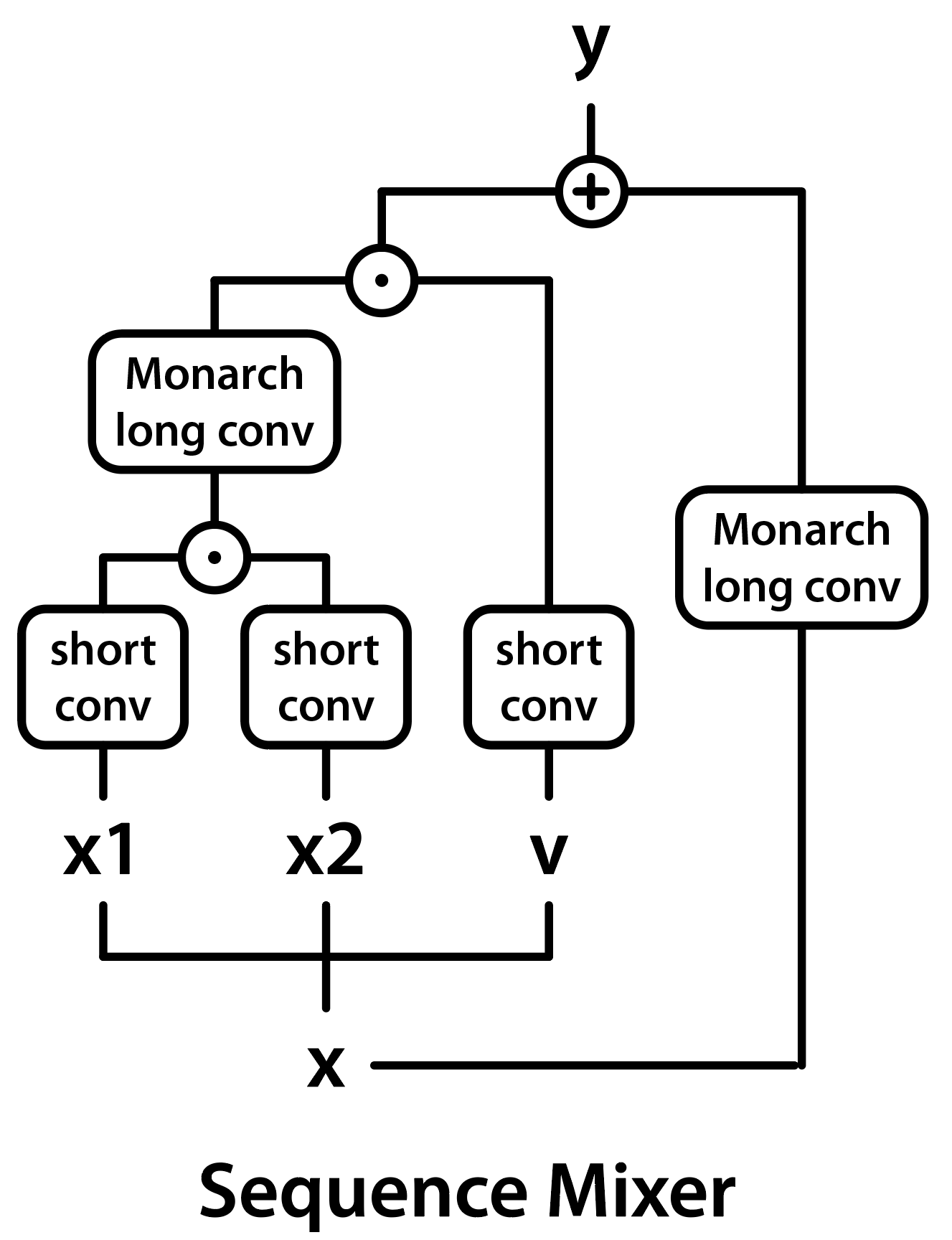
M2 uses Monarch matrices to implement a gated long convolution, by implementing the convolution using FFT operations.
We replace the MLPs by replacing the dense matrices in the MLP with block diagonal matrices:
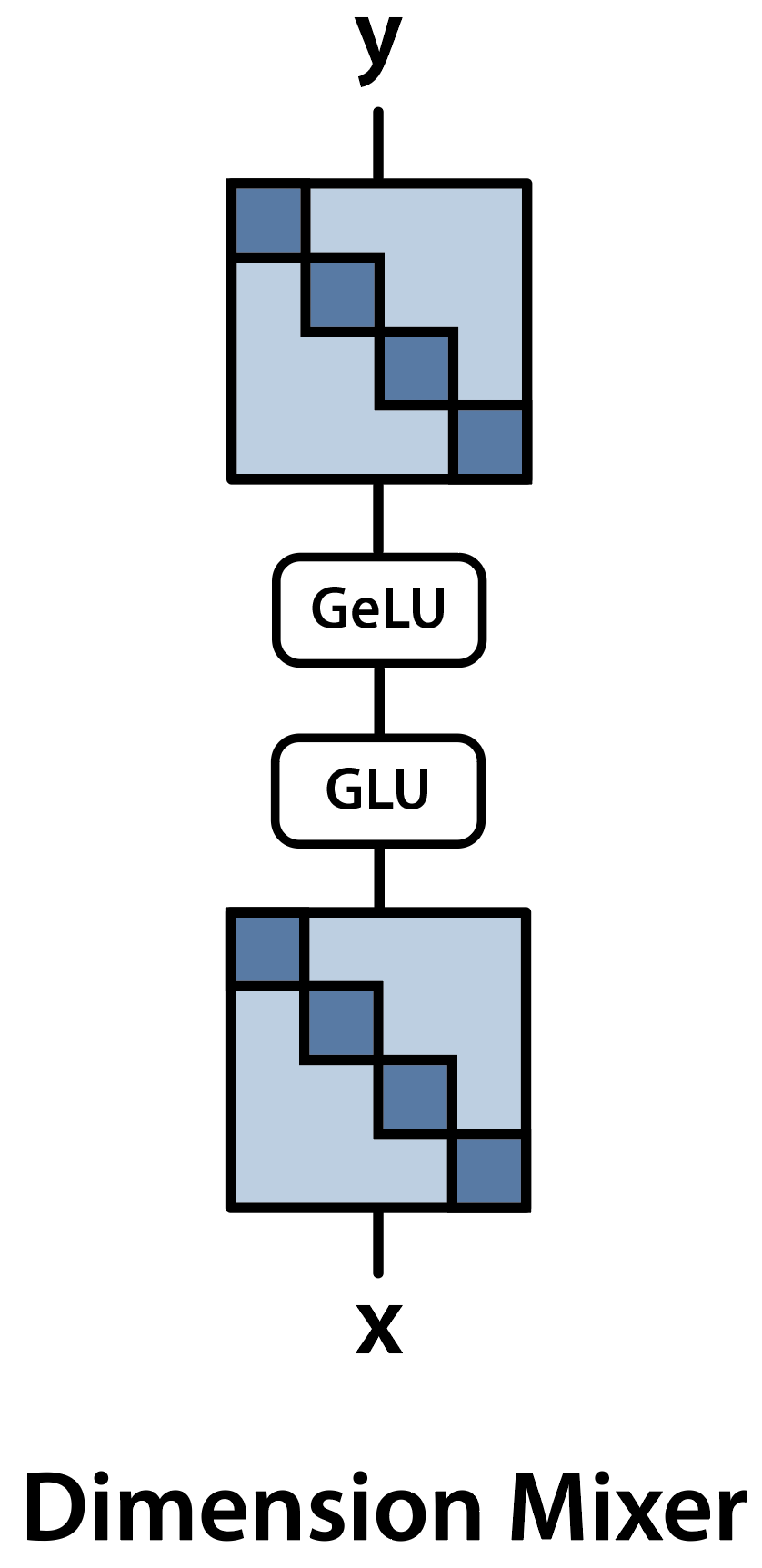
M2 replaces dense matrices in an MLP with block-diagonal matrices.
Incidentally, this makes the model look similar to MoE models, without learned routing.
Once we’ve replaced attention and MLP with these new primitives, we can use this architecture to train BERT models. In the M2 paper, we showed that we can match BERT quality with fewer parameters:
| Model | Average GLUE Score |
|---|---|
| BERT-base (110M) | 79.6 |
| M2-BERT-base (80M) | 79.9 |
| BERT-large (340M) | 82.1 |
| M2-BERT-base (260M) | 82.2 |
And faster wall-clock time, especially for long sequences (throughput in terms of tokens/ms):
| Model | 512 | 4096 | 8192 |
|---|---|---|---|
| HF BERT-base (110M) | 206.1 | 39.0 | OOM |
| FlashAttention BERT-base (110M) | 367.4 | 179.1 | 102.4 |
| M2-BERT-base (80M) | 386.3 | 353.9 | 320.1 |
| Speedup over HF | 1.9 | 9.1 | - |
That OOM in HF BERT-base is particularly important (and FlashAttention BERT-base eventually OOMs as well). That means that any retriever with a Transformers-based BERT backbone will have trouble with long-context – that’s everything from sentence-BERT to ColBERT to BGE and more!
Check out our blog post on M2-BERT for more!
In this work, we’re going to take advantage of the better long-context throughput to train some long-context retrieval models!
Adapting M2-BERT for Long-Context Retrieval
In the original M2 paper, we only trained M2-BERT models on relatively short sequence lengths (128 sequence length), though we benchmarked the architecture’s efficiency on longer sequences. In this work, we found that simply extending the standard BERT training pipeline to longer sequence data was insufficient to train a good long-context retrieval model.
In particular, we faced two concrete challenges:
- Adapting the standard BERT pretraining pipeline to long sequences (data mixture). Our M2-BERT pretraining pipeline used C4, which has relatively short documents. If we want to pretrain a long-context M2-BERT model, we’ll need longer documents. We’ll also find that directly training on long-sequence data is hard – we need a mixture of sequence lengths or warmstarting from a shorter-context checkpoint.
- Adapting the standard retrieval fine-tuning pipelines for long-context models (loss functions). Almost every dense retrieval model (see 1, 2, 3, 4) uses a supervised contrastive loss function, which is very sensitive to batch size. This is a problem for long-sequence data, since batch sizes need to remain small for GPU memory limits. We need to change the loss functions.
As an aside – these challenges point to a broader trend in the research area. There’s been a lot of work on designing new architectures for long sequences, but the architecture isn’t all it takes. There’s an emerging area on how to train models so they can actually use long sequences.
We’ll dive more into each of these challenges now.
Long-Context Pretraining
Our first problem is how to adapt the BERT pretraining pipelines for long-context data. In the original M2 work, we performed masked language modeling pretraining at context length 128 using the standard C4 corpus. C4 contains documents with relatively short sequence lengths (dozens to low hundreds of tokens), so how can we adapt our pipeline for long-context pretraining and get 2K, 8K, and 32K pretrained M2-BERT models?
A standard technique (which is common in GPT-style training) is to concatenate documents together until you reach your desired sequence length. Under this paradigm, each document the model sees is of a single fixed length. We tried this out with C4 at first, but found this resulted in poor performance – one intuition for why is that BERT-style models need to process documents and generate embeddings for all sorts of sequence lengths.
Instead, we found that it was helpful to use a mixture of natural documents, of varied sequence lengths, with padding and concatenation. We also extended the pretraining corpus to include naturally-longer documents – in addition to C4, we added longer documents from Wikipedia and Books3 to our pretraining corpus. We used a weighted mixture of natural documents and concatenated documents to pretrain our M2 models:
| Data source | Proportion |
|---|---|
| C4 | 10% |
| C4, concatenated | 24% |
| Wikipedia | 10% |
| Wikipedia, concatenated | 23% |
| Books3 | 10% |
| Books3, concatenated | 23% |
We used these proportions to train our 2K and 8K models from scratch. For the 32K model, we found that it was helpful to warm-start using the 8K model, and simply copy over positional embeddings at initialization.
With these techniques, we were able to pretrain three long-context M2-BERT models: M2-BERT-80M-2k, M2-BERT-80M-8k, and M2-BERT-80M-32k.
Fine-Tuning for Long-Context Retrieval
Ok, so now we have some long-context M2-BERT models. But raw BERT models are actually not all that useful for retrieval – you have to fine-tune them to become good embedding models, a la a sentence-transformers pipeline.
This brings us to our second training challenge. Most retrieval models are trained using a supervised contrastive loss (called “MultipleNegativesRankingLoss” in sentence-transformers), using corpora of queries and documents.
In the data, you have pairs of queries and documents. The way the loss typically works is you load up a batch of queries and documents, and use a contrastive loss to bring the embeddings of the true query/document pair together (the “positive” pair), while pushing apart all the embeddings of all the other queries and documents (the “negative” pairs).
You can see this written out mathematically here, for a batch of queries and documents , where are the embeddings of the positive pair:
The key thing to understand about this is that the numerator pushes the embeddings of the positive pair towards each other, while the denominator pushes embeddings every negative pair apart from each other (from ).
This loss is very dependent on the batch size. If your batch is too small, you don’t get enough negative samples, and you get a bad embedding geometry.
This poses a problem for training long-context retrieval models – when you’re fine-tuning on long documents, you are limited in batch size due to GPU memory limits (more tokens -> more memory).
For context, we typically want batches of size 32 or greater with the contrastive loss – but we’re limited to size 1 at sequence length 32K.
The computer vision literature has known about this problem for a while and has developed a number of techniques – memory banks, prototypical losses, and more. When we tried these on retrieval pipelines, most of them had poor performance. Our intuition is that they are poor approximations of the true contrastive loss.
We then turned to a technique called orthogonal loss (or “cosine similarity loss” in sentence-transformers parlance). This loss pushes the cosine similarity of positive pairs of embeddings to 1, and the cosine similarity of negative pairs of embeddings to 0 – or orthogonal vectors.
And it’s simple to write down. For a given query embedding , its positive , and negatives , the loss is:
The terms of this loss are independent from each other (c.w. the denominator of a contrastive loss needs all the negatives). As a result, this entire loss can be computed while only ever holding one query and one document in memory! That means that we are not sensitive to batch size limitations on GPU.
Using this loss, we were able to unlock good long-context retrieval performance! Speaking of… how did we know how to evaluate those pipelines?
Results: Long-Context Retrieval with LoCo
So now we have these long-context retrieval models! This actually brought up another challenge: how do we actually evaluate these models? Most existing retrieval benchmarks like BEIR and MTEB are mostly full of short queries and documents.
So in response, we put together a long-context retrieval benchmark called LoCo.
LoCo is under active development – this is just a first pass. If you have tasks that you think would be good additions to the benchmark to evaluate on, please reach out to us via email!
For now, LoCo just contains five retrieval tasks taken from public datasets. We selected these based on the length of the documents (we wanted long documents), and manual inspection to check that retrieval would actually require understanding of the whole document. Here are some statistics on the five datasets that are in LoCo V0 (scroll to see the whole table):
| Dataset | Document Type | Number of Documents | Min Length (Characters / Words) | Max Length (Characters / Words) | Avg. Document Length (Characters / Words) | Avg. Query Length (Characters / Words) |
|---|---|---|---|---|---|---|
| Tau Scrolls QMSum | Meeting Transcripts | 1257 | 6458 / 1035 | 147316 / 24651 | 55297 / 9748 | 434 / 71 |
| Tau Scrolls Gov Report | National Policy Reports | 17457 | 2035 / 289 | 1268491 / 197506 | 52716 / 8154 | 3232 / 479 |
| Tau Scrolls Sum mScreen FD | TV Episode Transcripts | 3673 | 7514 / 1154 | 83873 / 13573 | 31346 / 5196 | 570 / 99 |
| Qasper Title to Document | Scientific Research Papers | 888 | 375 / 44 | 169214 / 26005 | 24537 / 3749 | 72 / 9 |
| Qasper Abstract to Document | Scientific Research Papers | 888 | 375 / 44 | 169214 / 26005 | 24537 / 3749 | 982 / 144 |
Here’s a sample from one of the datasets called QMSum, where the documents are meeting transcripts.
We found that these tasks were decently challenging, even for state-of-the-art retrieval models (see the bottom of the blog for full results). The LoCo score is the average of the NDCG@10 score for all five tasks.
| Retrieval Encoders | Seq Len | LoCo Score |
|---|---|---|
| intfloat/e5-mistral-7b-instruct (7.11B) | 4096 | 88.5 |
| BGE-Large-en-v1.5 (335M) Zero-shot | 512 | 77.2 |
| BGE-Base-en-v1.5 (109M) Zero-shot | 512 | 73.4 |
| BGE-Small-en-v1.5 (33.4M) Zero-shot | 512 | 70.6 |
| Voyage Embeddings | 4096 | 25.4 |
| Cohere Embeddings | 512 | 66.6 |
| OpenAI Ada Embeddings | 8192 | 52.7 |
Mistral-7B performs the best - it can technically run sequences longer than 4K, but the README doesn’t recommend it. We also ran with the full 32K context (see the table at the end), but observed worse performance.
For our long-context retrieval models, we fine-tuned M2-BERT-80M-2K, -8K, and -32K on the training sets of these tasks using the orthogonal loss. These are our M2-BERT-80M-2K-retrieval, -8K-retrieval, and -32K-retrieval models.
For a baseline comparison, we took the three BGE models (small, base, large) and fine-tuned them a few ways using the same examples. We also include the best zero-shot model as reference:
| Retrieval Encoders | Seq Len | LoCo Score |
|---|---|---|
| infloat/e5-mistral-7b-instruct (7.11B) | 4096 | 88.5 |
| BGE-Large-en-v1.5 (335M) Fine-tuned | 512 | 85.0 |
| BGE-Base-en-v1.5 (109M) Fine-tuned | 512 | 83.0 |
| BGE-Small-en-v1.5 (33.4M) Fine-tuned | 512 | 81.2 |
| M2-BERT-2048 (80M) | 2048 | 83.6 |
| M2-BERT-8192 (80M) | 8192 | 85.9 |
| M2-BERT-32768 (80M) | 32768 | 92.5 |
M2-BERT retrieval models can outperform much larger models on this benchmark – up to 4x larger fine-tuned models and up to 85x larger zero-shot models – which is pretty exciting and suggests that long-context models are beneficial for retrieval!
We also tried hard to adapt SoTA short-context retrieval models to the long-context setting by changing the retrieval protocol. We chunked the long-context documents in the LoCo benchmarks and indexed the chunks. Given a query, we rank the documents based on the average similarity across the chunks in the document. We found that this protocol was sufficient to compete with long-context M2 models on 2 of 5 benchmark tasks. However, this protocol severely underperforms on the Tau Scrolls - QMSUM and QASPER tasks:
| Retrieval Encoders | Seq Len | LoCo Score |
|---|---|---|
| infloat/e5-mistral-7b-instruct (7.11B) | 4096 | 88.5 |
| BGE-Large-en-v1.5 (335M) | 512 | 85.0 |
| BGE-Large-en-v1.5 (335M) w/ Chunking | 32768 | 72.5 |
| M2-BERT-32768 (80M) | 32768 | 92.5 |
Extending LoCo
Of course, these are only initial preliminary results – we don’t expect many people are searching up TV scripts via synopsis. When constructing this benchmark, we were primarily looking for datasets that a) had long documents, and b) where the query to passage mapping wasn’t immediately obvious from the first few sentences. For example, a dataset of movie titles and movie scripts, where the title is the first sentence of the script, wouldn’t be a very interesting long-context benchmark!
We think there’s tons of exciting research to be done to figure out where long-context models matter most. That’s why we want your feedback on what tasks to add to this benchmark – this is only a first step towards really great long-context retrieval models!
What’s Next
This is an initial release of a few interesting artifacts via blog post – we’ll be releasing a full paper with all the details some time next month. In the meantime, you can check out our code, download our models (2k, 8k, 32k), and try it on your own tasks via the Together embeddings API.
If you do, we really want to hear from you! We’d love to hear about:
- What long-context retrieval applications you’ve tried M2-BERT retrieval on, and how well they’ve performed
- What long-context tasks we should add to LoCo for the next version
If you’re interested in this stuff, please reach out – we’re excited to hear from you!
- Jon Saad-Falcon: jonsaadfalcon@stanford.edu
- Dan Fu: danfu@cs.stanford.edu
- Simran Arora: simarora@stanford.edu
Acknowledgments
We would like to thank the Stanford Center for Research on Foundation Models (CRFM), and the Stanford AI Laboratory for supporting our research! Thank you to Alycia Lee for helping set up AutoModel for our models on HuggingFace.
We would also like to thank our collaborators at Together AI for their support in developing these models, and their help in hosting these models in their new embedding API. Thanks to Together, we were able to test out early versions of these models at a Hackathon with MongoDB, and we’re looking forward to all the new use cases for long-context retrieval models including RAG integrations with LangChain and LlamaIndex.
Check out their blog posts on new usage of these models!
Full Results
| Retrieval Encoders | Seq Len | Tau Scrolls Summ. Screen | Tau Scrolls Gov. Report | Tau Scrolls QMSUM | QASPER - Title to Article | QASPER - Abstract to Article | Average |
|---|---|---|---|---|---|---|---|
| M2-BERT-2048 (80M) | 2048 | 81.8 | 94.7 | 58.5 | 87.3 | 95.5 | 83.6 |
| M2-BERT-8192 (80M) | 8192 | 94.7 | 96.5 | 64.1 | 86.8 | 97.5 | 85.9 |
| M2-BERT-32768 (80M) | 32768 | 98.6 | 98.5 | 69.5 | 97.4 | 98.7 | 92.5 |
| BGE-Small-en-v1.5 (33.4M) Fine-tuned | 512 | 58.13 | 90.3 | 65.5 | 94.3 | 97.9 | 81.2 |
| BGE-Base-en-v1.5 (109M) Fine-tuned | 512 | 64.7 | 90.2 | 66.9 | 95.2 | 98.1 | 83.0 |
| BGE-Large-en-v1.5 (335M) Fine-tuned | 512 | 70.8 | 93.5 | 66.0 | 96.3 | 98.4 | 85.0 |
| BGE-Large-en-v1.5 (335M) Fine-tuned w/ Chunking | 32768 | 88.6 | 97.7 | 17.8 | 72.9 | 85.5 | 72.5 |
| OpenAI text-embedding-ada-002 | 8192 | 37.3 | 44.3 | 7.3 | 85.1 | 89.7 | 52.7 |
| Cohere embed-english-v3.0 | 512 | 46.4 | 72.4 | 38.1 | 85.2 | 91.1 | 66.7 |
| Voyage voyage-01 | 4096 | 1.95 | 39.4 | 15.2 | 38.4 | 32.2 | 25.41 |
| infloat/e5-mistral-7b-instruct (7.11B) 4K | 4096 | 95.9 | 98.3 | 46.8 | 98.4 | 99.8 | 87.8 |
| infloat/e5-mistral-7b-instruct (7.11B) 32K | 32768 | 70.7 | 51.8 | 7.4 | 96.6 | 97.9 | 64.9 |