Oct 14, 2021 · 9 min read
What can we accomplish without changing the architecture? A thought experiment in incorporating knowledge through data!
Simran Arora, Sen Wu, Enci Liu, and Chris Ré
An exciting question is how to include and maintain different kinds of knowledge in machine learning systems. Many people, including ourselves, are very interested in this problem and have proposed a range of new architectures, which typically start with a base language model (LM) (e.g., BERT) and apply modifications to better incorporate knowledge. While developing one such architecture in our own group, we had an odd thought: to what extent we could match the quality of these knowledge-aware architectures using a base LM architecture, and only changing the data? We propose some simple modifications to the data at train and test time, which we call metadata shaping, that surprisingly seem quite effective.
An exciting question is how to include and maintain different kinds of knowledge in machine learning systems. Many people, including ourselves, are very interested in this problem and have proposed a range of new architectures , which typically start with a base language model (LM) (e.g. BERT) and apply modifications to better incorporate knowledge. While developing one such architecture in our own group, we had an odd thought: to what extent could we match the quality of these knowledge-aware architectures using a base LM architecture, and only changing the data? We propose some simple modifications to the data at train and test time, which we call metadata shaping, that surprisingly seem quite effective! You can also checkout the full paper here.
Knowledge-Aware Architectures
Improving the ability of models to perform well on rare “tail” examples, seen infrequently during training, is an ongoing challenge in machine learning and is generally addressed by incorporating domain knowledge. A key question is how to include the domain knowledge in our ML pipelines --- through hard-coded constraints, the model architecture, model objective function, the data…?
The tail challenge is particularly evident in the setting of entity-rich tasks, since users often care about very different entities and facts when using applications such as search and personal assistants. Recent base language models (LMs) like BERT, became simpler and higher-performing alternatives to early feature-engineered pipelines, which used many manually-defined rules to express domain knowledge. However, performance of these LMs remains quite poor on the tail. For entity-rich tasks, the typical source of domain knowledge is entity tags or metadata sourced from pretrained taggers (CoreNLP, SpaCy, entity-linkers) or knowledge bases (Wikidata, ConceptNet, UMLS). These readily available resources allow us to collect entity knowledge at scale.

Popular entity centric applications.
Given the importance of applications like those shown above, significant work focuses on capturing entity knowledge more
reliably by changing the LM architecture in various ways to produce knowledge aware LMs:
checkout KnowBERT, E-BERT, ERNIE, LUKE, WKLM, KGLM, KEPLER, CokeBERT, Bootleg, K-Adapter, and more!
In particular, these approaches start with a base LM, tag the raw training data with entity metadata, and then change the LM architecture and/or objective function to learn from the entity-tagged text.
These knowledge aware LMs perform quite well compared to base LMs though while using them, we struggled to reason about the different model modifications, understand what the model learned about each entity, and could imagine systems-level challenges from trying to deploy many different specialized models.
This experience motivated a fun thought experiment: what could we achieve without modifying the architecture, and only changing the data? Suppose that like the knowledge-aware LMs, we start with a base LM and tag the raw training data with entity metadata, but instead of changing the LM, we explicitly retrieve and encode entity properties in the data itself! The resulting metadata shaping method looks as follows:
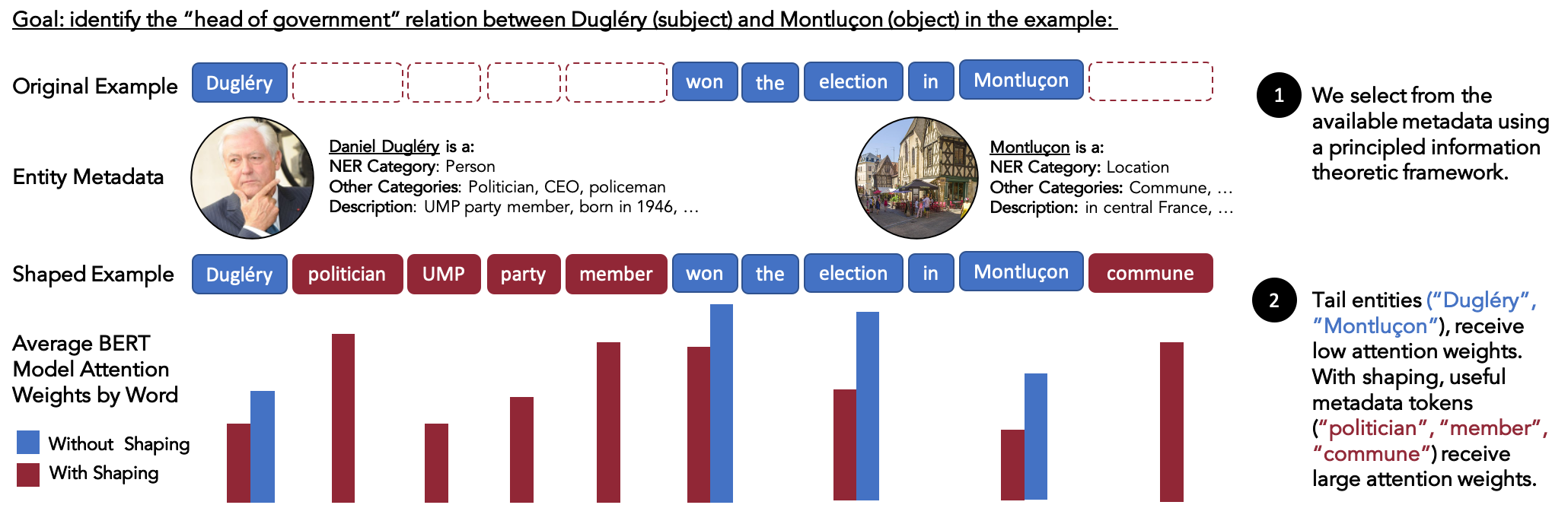
Metadata shaping inserts metadata (e.g., entity categories and descriptions) into examples at train and test time. The FewRel task involves identifying the relation between the subject and object substring. The above subject and object are unseen in FewRel training data and the LM places low attention weights on those tokens. An LM trained with shaped data has high attention weights for useful metadata tokens such as “politician”. Weights are shown for words which are not stop-words, punctuation, or special-tokens.
How does metadata shaping work?
A conceptual framework
It’s not obvious that inserting metadata in an example will help. For example, the fact that Barack Obama “plays basketball” might not be a useful signal for most tasks concerning Barack Obama. We need to understand how different metadata systematically change what the model learns. Since we decided to change the data instead of the model, we could rely on the rich set of techniques for reasoning about the data to address about some of these questions. We’ll stick to providing intuition here, and leave details to the paper:
Given a classification dataset of pairs , , , we evaluate the generalization error, or performance on unseen patterns, of a model using the cross-entropy loss --- the average loss between the estimated and true probabilities of the class given an input , vs. . We apply a fundamental concept, the principle of maximum entropy to express in terms of all the events or patterns, , appearing within example . For example includes various n-grams occurring in . And we note that achieving zero cross-entropy loss between the true probability and the estimated probability , for all , implies zero generalization error overall. But unfortunately for unseen patterns (e.g., unseen entities), the model’s estimated probability of a class given is simply random and the cross-entropy loss is . Our insight is that by introducing metadata for into , which occur non-uniformly across classes, we can push in a helpful direction. The key takeaway here is that the application of using metadata for the tail connects back to well-understood ideas in feature-selection, and such connections can be difficult to identify when modifying the architecture.
Main Results
On standard entity-rich benchmarks, we surprisingly find that metadata shaping, with no modifications whatsoever to the base LM, is competitive with the SotA knowledge aware methods, which do enrich the base LM! Here we look at two types of entity rich tasks:
- Entity typing (OpenEntity): given a sentence and a substring within the sentence, output the type of the substring
- Relation extraction (TACRED, FewRel): given a sentence and two substrings within the sentence, output the relation between the substrings
We simply use an off-the-shelf BERT-base LM with metadata shaping to improve upon the BERT baseline by up to 5.3 F1 points, and to exceed or compare to SoTA baselines, which do modify the LM.
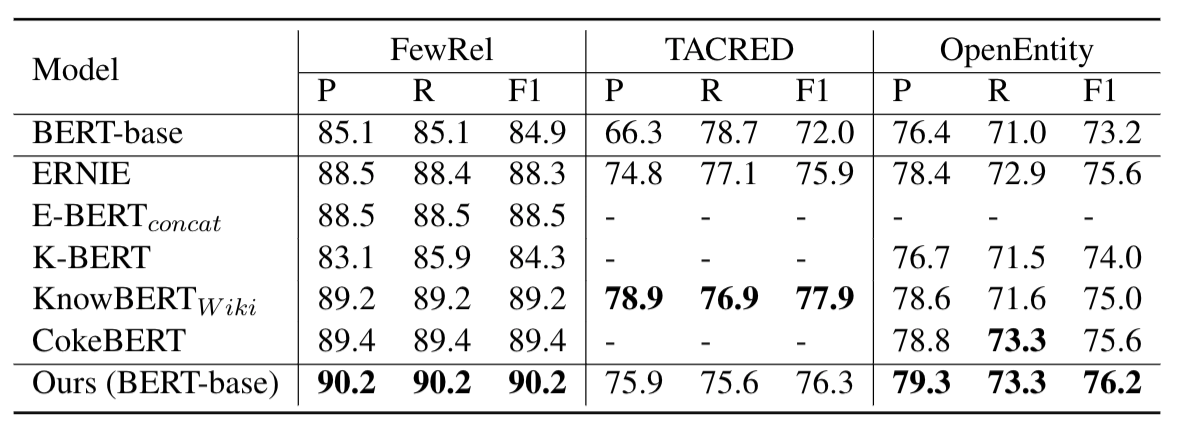
Test scores on relation extraction and entity-typing tasks. “Ours (Base LM)” is metadata shaping. All methods use the same base LM (BERT-base) and external information (Wikipedia) for consistency.
Checkout our paper for detailed experiments examining how metadata impacts performance on tail vs. popular entities, how we can use our conceptual framework to algorithmically select metadata for examples, and more!
Why does metadata shaping excite us, what are some takeaways?
While exploring, we noticed a few ways metadata shaping could address certain challenges we faced while using the knowledge-aware LMs, including:
1. It can be quite data inefficient to learn properties of every entity from-scratch given the sheer number of entities --- over 100M alone in English Wikidata! People reason about unfamiliar entities by using coarse-grained patterns that apply to groups of entities. For example, if you’ve visited many universities before, when visiting a new university, you might not know specific details like building names, but you will be familiar with basic properties of universities, like the existence of classrooms and students.
- Model: Knowledge-aware LMs learn about an entity from its individual occurrences during training rather than signaling that patterns learned for one entity may be useful for reasoning about other similar entities.
- Data: Metadata (e.g., “politician”) shared between a popular and rare entity (e.g., “Barack Obama” vs. “Daniel Dugléry”) are explicitly provided as inputs to the LM. So, the LM can use patterns observed for popular entities, to better reason about rare entities with the same metadata, without generating any new samples.
2. It can be difficult to conceptually reason about what the LM learns for each entity as a result of different model changes.
- Model: We have have a limited set of tools for analytically reasoning about neural networks.
- Data: We have a rich set of techniques for working with data, developed over decades!
3. Deploying many different specialized models raises systems-level challenges.
- Model: From a systems perspective, the additional pretraining required by many of the knowledge-aware LMs is compute-intensive; deploying and maintaining multiple specialized LMs is memory and time-intensive; implementation choices make a large difference in model performance; and each LM needs to be optimized for efficient use (e.g., on-device).
- Data: Since metadata is quite competitive to knowledge-aware LMs, we can simply use the re-use the same optimized and off-the-shelf base models! Alternatively, we can use metadata shaping and knowledge-aware LMs complementarily.
Of course there are also limitations. For instance, the method relies on accurate sources of external information. Pretrained entity embeddings may be able to encode more facts than expressed in metadata tokens, and the sequence length is a limitation for certain models. But we think this is altogether a compelling path to study alongside model developments.
Recap
The data perspective surprisingly works quite well and offers an opportunity to reason about how changes to the data might affect what the model learns. We are broadly interested in approaches which analyze the data and would love to hear your thoughts! See our paper for more details and this compilation of data centric AI resources to learn about other exciting directions in the space.