
 WONDERBREAD
WONDERBREAD
A benchmark + dataset for evaluating multimodal models on business process management (BPM) tasks.
2,928
human demonstrations598
workflows6
tasksTo help address this gap, we publish WONDERBREAD, a benchmark for evaluating multimodal FMs on BPM tasks with the goal of augmenting human workflows rather than replacing them.
Overview
Wonderbread consists of three primary components:

- A dataset containing 2,928 human demonstrations of 598 workflows, each of which include a textual description of the workflow intent, a full screen recording of the human completing the workflow, an action trace detailing which screen elements were interacted with, and a manually-written step-by-step guide in the form of a "Standard Operating Procedure" (SOP). The demonstrations cover a wide range of tasks from 4 different websites interfaces sourced from the excellent WebArena benchmark.
- A benchmark with 6 novel BPM tasks that measure the ability of a model to generate accurate documentation, assist in knowledge transfer, and improve workflows. The tasks are designed to evaluate models on real-world applications of BPM tools, with a more broad focus than simple end-to-end automation.
- A fully automated evaluation harness for evaluating models on the introduced tasks. The harness is designed to be easy to use and can be run on any multimodal FM that can be prompted via API. The harness is open-source and available on our GitHub repository.
Comparison to Prior Work
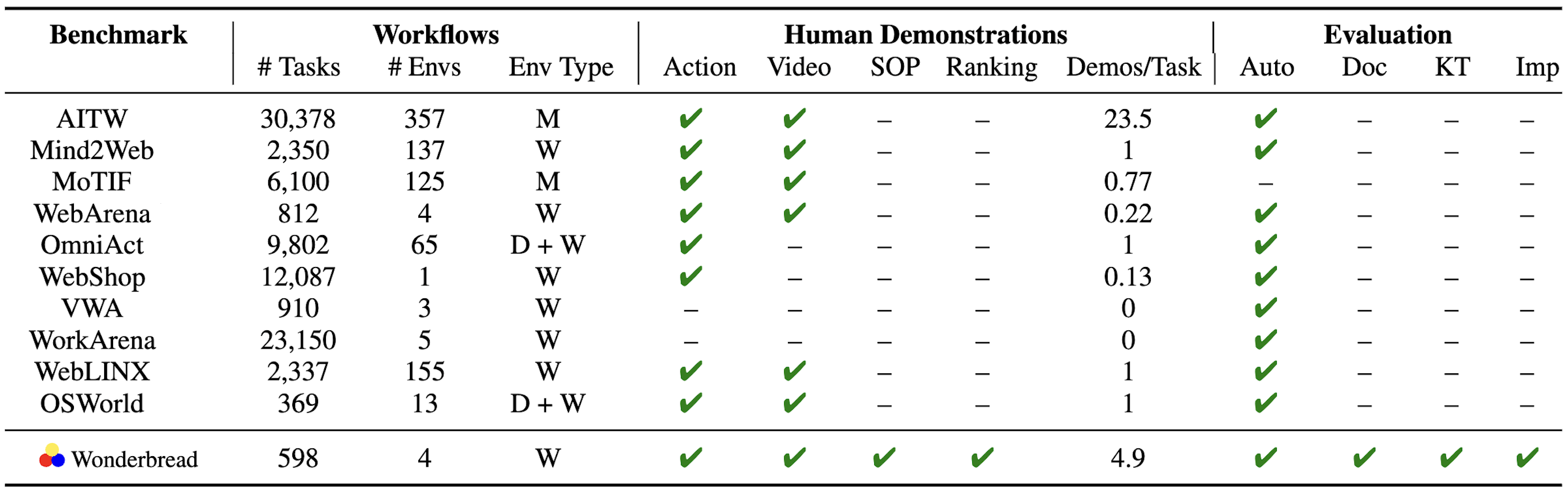
A number of prior multimodal datasets have been published for end-to-end automation of websites (W), mobile apps (M), and desktop (D) applications. WONDERBREAD builds on this prior work by specifically targeting BPM tasks beyond end-to-end automation.
Tasks
WONDERBREAD introduces 6 novel BPM tasks that measure the ability of a model to generate accurate documentation, assist in knowledge transfer, and improve workflows. The tasks are divided into three categories and are visualized below.
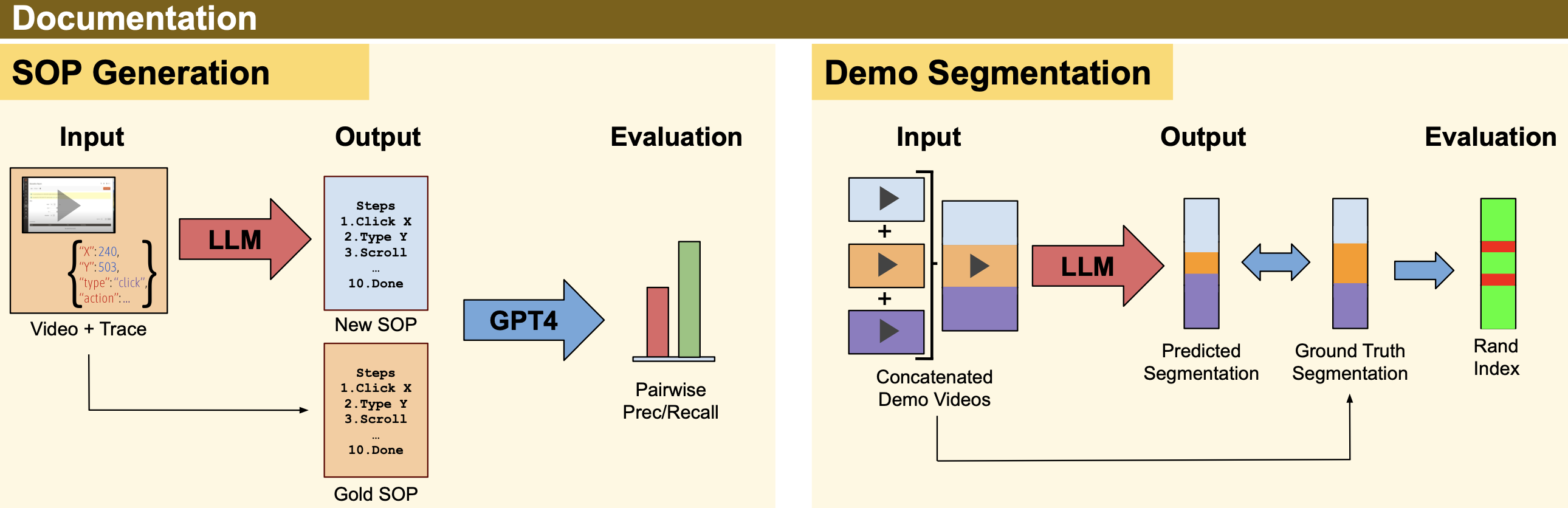
Given a video recording of a workflow demonstration, the model must generate an SOP documenting the steps of that demonstration.
Given multiple demonstrations from separate workflows concatenated into a single sequence, the model must identify when each workflow starts and ends.
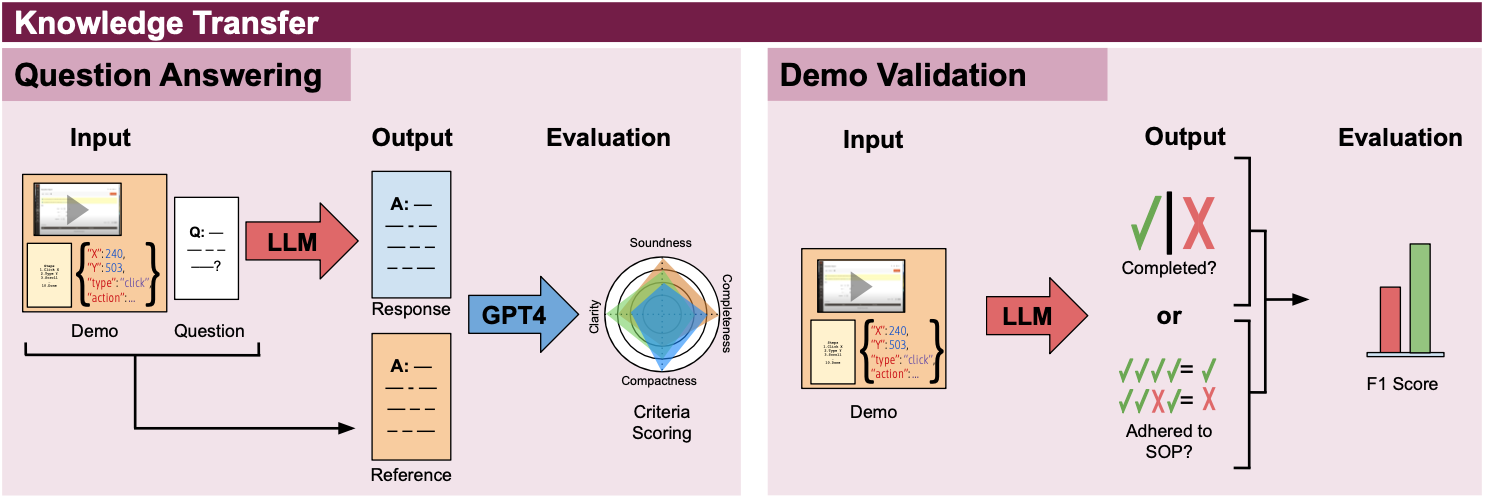
Given a free response question about one or more workflow demonstrations, the model must generate an answer.
Given a demonstration and SOP, the model must determine whether (a) the workflow was successfully completed; and (b) whether the demonstration exactly followed the SOP.
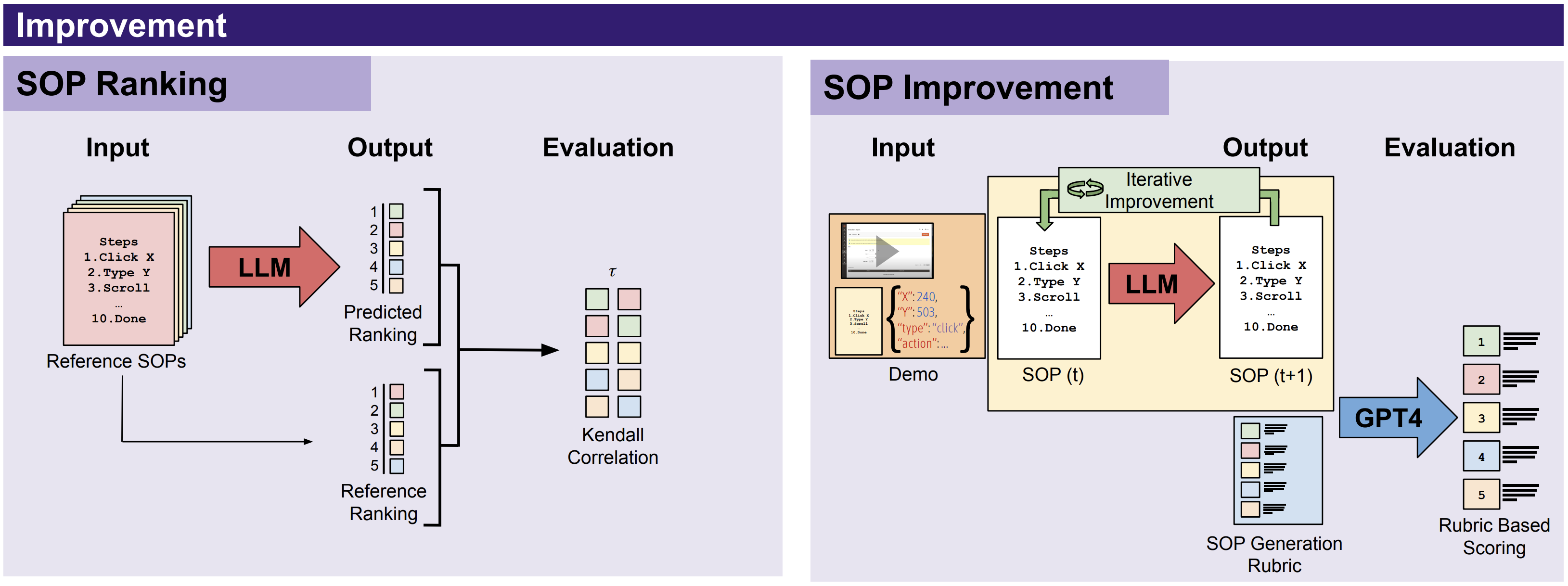
Given a set of SOPs written by human annotators, the model must rank the SOPs in order of quality.
Given a demonstration and low-quality SOP, the model must generate an improved SOP that better captures what is shown in the demonstration.
Results
In our initial publication, we evaluated the out-of-the-box capabilities of several commerically accessible multimodal FMs including GPT-4, Gemini, and Claude.
SOP Generation
Task: Write an SOP that documents the steps of a workflow based on a video recording of a demonstration.
Evaluation: The generated SOP is compared to a human-written reference SOP through a pairwise evaluation process that calculates the overal precision (proportion of steps in the predicted SOP present in the reference SOP) and recall (proportion of steps in the reference SOP present in the generated SOP).
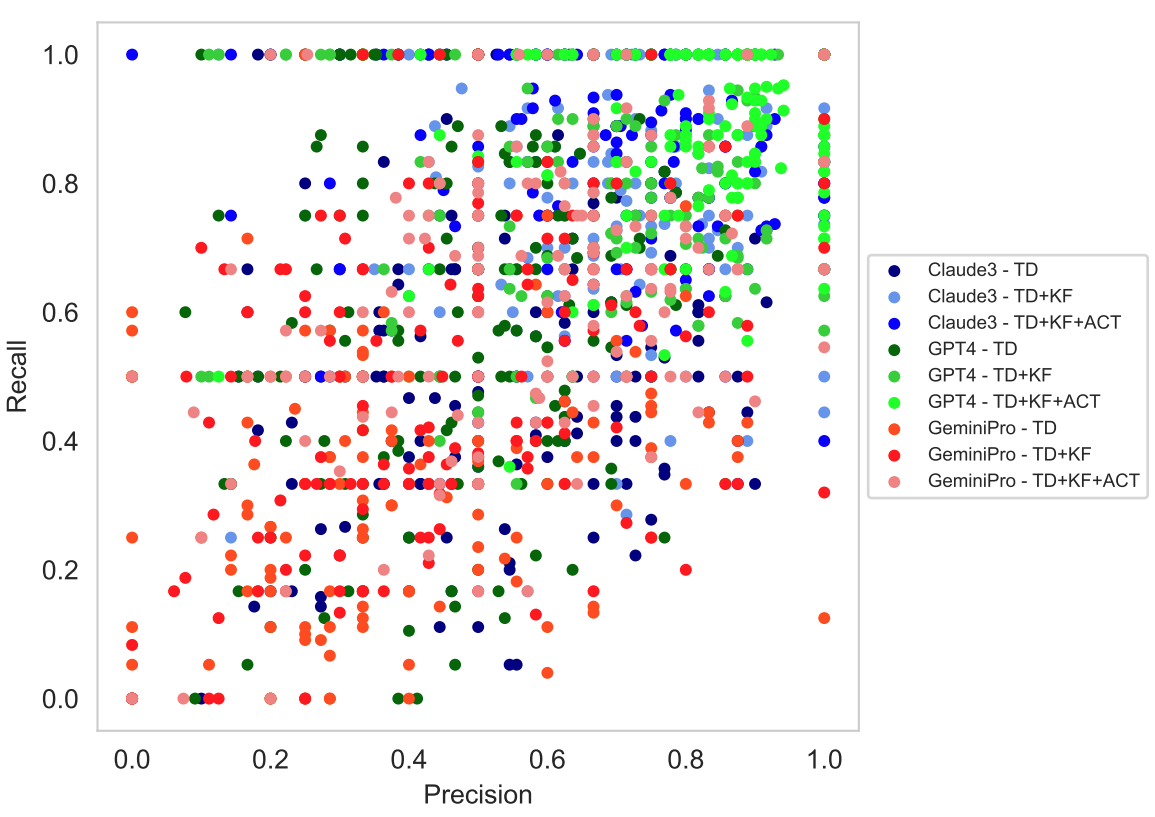
Results: Each point in the above figure is the precision/recall score for a single SOP generated by a single model. Higher and to the right is better. We find that most models demonstrate strong out-of-the-box capability to identify all steps in a demonstration (relatively higher recall) but are relatively more prone to hallucinating inaccurate or superfluous steps (lower precision).
Demo Segmentation
Task: Identify when each workflow starts and ends in a concatenated sequence of demonstrations.
Evaluation: Clustering accuracy of the model's prediction for each frame in the sequence.

Results: In the figure above, we visualize the performance of GPT-4 on sequences with 3 demonstrations. Green timesteps indicate a correct segmentation assignment, while red timesteps indicate an incorrect assignment. The black vertical lines indicate the true start and end of each demonstration.