May 15, 2026 · 13 min read
From Minions to OpenJarvis: A Retrospective on Two Years in Local AI

For two years, the dominant story in AI has been the growing cloud: bigger clusters, larger models, more gigawatts. Another story is unfolding in the opposite direction: on-device inference, smaller models, watts instead of gigawatts.
Over the past two years, we've explored this through three projects, Minions, Intelligence per Watt, and OpenJarvis, each making a version of the same argument: the future of inference is hybrid by design, local by default.
TL;DR. Across three projects, we argue that capable AI inference can run on hardware people own, with cloud reserved for what genuinely needs it. Minions showed local and cloud are complements: cloud decomposes long-context tasks, local executes subtasks in parallel, recovering 97.9% of GPT-4o's accuracy at 5.7× lower cost. Intelligence per Watt (IPW) introduced task performance delivered per watt of power as a unified metric for local viability: IPW improved 5.3× in two years, and 88.7% of single-turn chat and reasoning queries are answerable locally. OpenJarvis decomposes the personal AI stack into five composable primitives that run on a user's own devices, treating efficiency and on-device learning as first-class capabilities alongside accuracy. A single shared deployment ties the arc together: optimize with cloud at search time, run local at inference time.
Sections: State of Play · How did we get here? · Impact · What we're releasing today · What's next? · Build with us
State of Play

Local AI is having its moment, driven by two compounding trends.
On the demand side, users are pulling for on-device. Personal-AI runtimes like OpenClaw and Hermes Agent have built large user bases around personal AI leveraging cloud intelligence, building agents for their daily life. The local stack can now actually answer most of the queries those users send without sacrificing privacy, cost, latency, and offline operation.
On the supply side, the components are landing. M4-generation Mac Minis became developer favorites as unified-memory inference boxes. Open-weight families like Qwen3, gpt-oss, Gemma, and IBM Granite now trail frontier cloud models by 6 to 12 months on most personal-AI tasks, rather than years. NVIDIA shipped DGX Spark, a desktop with 128GB of unified memory and a petaFLOP at FP4. The full stack from silicon to scaffolding has quietly become deployable.
The two trends compound. Total LLM usage is expanding faster than cloud capacity can absorb, so routing inference workloads to local hardware lets cloud capacity concentrate on the queries that genuinely need frontier capability. The world will be hybrid by design and local by default.
How did we get here?
Three projects, three starting questions:
- How can local and cloud models collaborate on long-context tasks? (Minions)
- How much intelligence can local hardware actually deliver per unit of energy? (Intelligence per Watt)
- How do we run an entire personal-AI stack on-device? (OpenJarvis)
Taken together, they trace a single line of inquiry: how do we deliver capable AI on hardware people own, while still drawing on the cloud where it adds the most value?
- Minions established that local and cloud models can collaborate productively.
- Intelligence per Watt established that local hardware is closing the efficiency gap fast enough to matter.
- OpenJarvis established that an entire personal AI stack can run on a user's own devices when efficiency is a first-class design constraint.
Minions: Local and cloud models are a match
Minions started from a specific observation. When you give a small on-device model and a frontier cloud model the same long-context document QA task, the cloud model crushes it and the local model fails. The failure has two compounding sources: long contexts and complex multi-step instructions. Decompose the task into small, simply-specified subtasks over short context shards, and each piece falls within the local model's reach.
This suggested a protocol: the cloud model decomposes the task into small, local-shaped subtasks; the local model executes each subtask over a shard of the context, in parallel; the cloud model aggregates. Two variants emerged: Minion (a single local model in extended chat with the cloud) and MinionS (the cloud decomposes into parallel local subtasks).
The numbers came out cleanly. On FinanceBench, ConvFinQA, MuSiQue, QASPER, and similar long-context benchmarks, MinionS recovered 97.9% of GPT-4o's accuracy at 5.7× lower cost; the cheaper Minion variant hit 87.9% at 30.4× lower cost.
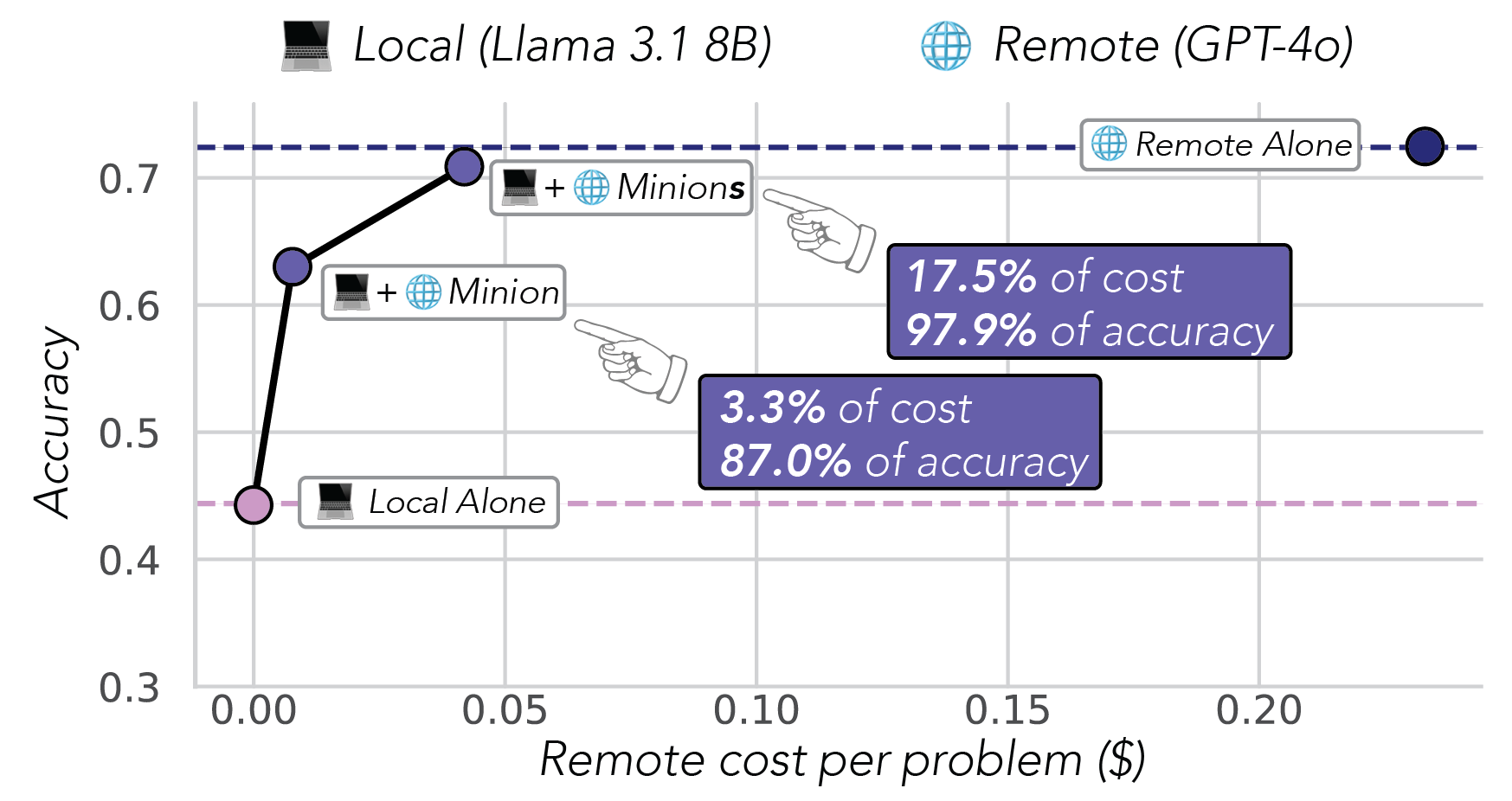
The shape of the gain (cloud for planning, local for parallel grunt work) generalized further than we expected. It is the same asymmetry we'll return to in OpenJarvis, one layer up: cloud at search time to optimize the stack, local at inference time to run it.
Intelligence per Watt: Local compute is underutilized (and getting better!)
Minions showed that local participation pays off, but it did not answer the underlying measurement question: how much intelligence can local hardware actually deliver per unit of energy, and how is that changing? Benchmarks measured accuracy. MLPerf and ML Energy measured throughput or energy. Nothing measured them together at the granularity of a model-accelerator pair on a real workload distribution.
So we built one. Intelligence per Watt (IPW) is task accuracy divided by mean power draw, measured per query, on real inference workloads. We instrumented a hardware-agnostic profiling harness across NVIDIA, AMD, Apple, and SambaNova accelerators, ran 1M+ queries across WildChat, NaturalReasoning, MMLU-Pro, and SuperGPQA through 20+ local LMs, and tracked how the numbers moved from 2023 to 2025.
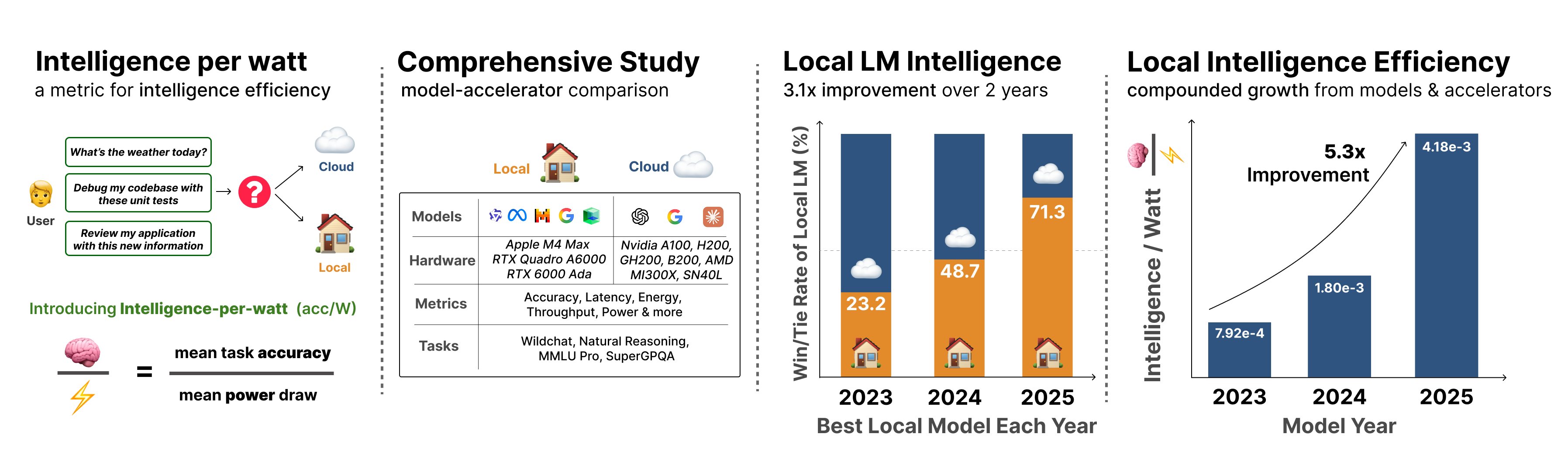
We found three interesting findings from our IPW study. First, 88.7% of single-turn chat and reasoning queries can be answered correctly by some local LM (≤20B active parameters), with coverage on the best single local model moving from 23.2% (2023) to 71.3% (2025). Second, IPW improved 5.3× over two years, roughly 3.1× from better models and 1.7× from better hardware. Third, local accelerators still trail cloud accelerators by 1.4-7.4× on the same workload, but routing inverts the per-query gap at the system level: a hybrid local-cloud router delivers 60-80% reductions in energy, compute, and cost compared to a batched cloud baseline, because the dominant effect is sending easier queries to local models rather than cloud models.
Overall, we find that efficient AI infrastructure comes from straddling local and cloud models and hardware, rather than from waiting for local silicon to match cloud silicon per query.
OpenJarvis: A local-first stack for personal AI
By late 2025, open-weight 4B-32B models had become genuinely capable for personal AI workloads, with the deployment bottlenecks shifting to the engineering stack around them. In almost every personal-AI framework, the local component is a thin orchestration layer while the intelligence is leased from someone else's data center. Your most personal data (e.g. emails, calendars, documents, messages) routes through cloud APIs, with their associated latency and inference costs.
We built OpenJarvis as an opinionated framework for personal AI that runs on your personal devices. It exposes a personal AI system as five composable primitives: Intelligence (the on-device language models), Engine (the inference runtime), Agents (the reasoning loops), Tools & Memory (interfaces and persistent local state), and Learning (the optimizer that improves all of the above from local traces). Each primitive is an independent slot, benchmarkable and substitutable on its own.
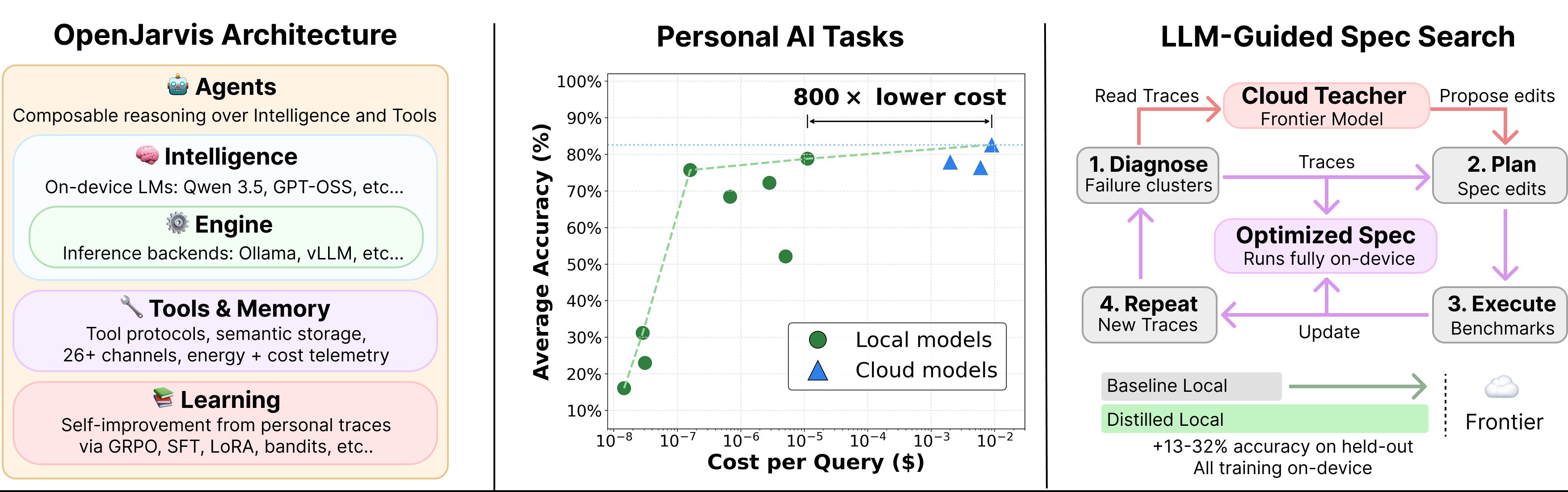
Three design commitments fall out of this. First, efficiency is a first-class constraint, not an afterthought. On a laptop running on battery, constraints such as energy, dollar cost, FLOPs, and latency are hard requirements, not nice-to-haves. OpenJarvis ships a hardware-agnostic telemetry layer that profiles power draw across NVIDIA, AMD, and Apple Silicon, and treats those metrics as evaluation targets alongside accuracy. Second, learning happens locally. Because execution is local, traces stay on-device, and the same traces can drive closed-loop optimization across model weights (SFT, LoRA, GRPO), prompts (DSPy, GEPA), engine configuration, and tools selected. Third, the cloud teaches the local stack at search time. A frontier model reads on-device traces, identifies failure clusters, and proposes coordinated edits across the four editable primitives. A held-out gate accepts only edits that don't regress. The resulting stack runs entirely on-device. We call this loop LLM-guided spec search, and it is how OpenJarvis closes the frontier-local gap on hard tasks without giving up local execution at inference time.
Where local trails cloud, we lean on the cloud at search time to optimize the local stack, and let the optimized stack run on-device at inference time. Cloud at search time, local at inference time.
Impact

We are grateful that the metrics, methodologies, and libraries from this program are actively in use by an unusually wide range of partners, spanning chip manufacturers, local AI platforms, and LM training shops. Each community framed the value differently, but the underlying claim is shared: local and cloud compute are complements, not substitutes.
Minions
Minions found an audience faster than we expected. Ollama launched a same-day collaboration, making "your local model and a cloud model, talking to each other" a first-class workflow. AMD brought the protocol to Ryzen AI through Lemonade, and Docker built MinionS into Compose and Model Runner under the framing "Hybrid AI isn't the future, it's here." Together AI wrote it up as "embracing small LMs, shifting compute on-device," which captured the thesis better than we did. Secure Minions then closed the loop on the obvious next question: can you run this protocol if you don't trust the cloud provider? We found that by using H100 confidential computing as a remote-attested enclave, even root users on the cloud side cannot read plaintext!
Intelligence per Watt
IPW gave the field a shared name for something it had been measuring in disconnected pieces. NVIDIA built on the framing in their developer blog on token-factory revenue and performance-per-watt; IBM Research wrote up the work alongside Granite 4.0; SambaNova published a benchmark post on best intelligence-per-joule. Laude Institute awarded a Slingshot grant for follow-on work, Gartner cited IPW in their efficiency reports, and the Computing Research Association hosted a Jeffersonian dinner, in which AI luminaries discussed IPW and other topics. Once you have a unified accuracy-and-power number, a lot of efficiency arguments that previously lived in disconnected dimensions snap into the same frame.
What we're releasing today
Hybrid capabilities
OpenJarvis v1.0 makes three hybrid patterns from this research arc first-class:
- Hybrid local-cloud collaboration. OpenJarvis supports a growing family of techniques for coordinating frontier cloud models with local models, including Minions, Advisor Models, Conductor, and ToolOrchestra. Each carves up the work differently; OpenJarvis exposes them as composable patterns so researchers can study existing protocols and build new ones without rewriting the stack.
- LLM-guided spec search. A frontier model reads traces, proposes coordinated edits across all five primitives, and a held-out gate accepts only non-regressing edits. The resulting spec runs entirely on-device.
- Per-query routing through a query-complexity analyzer: easier queries stay local while only queries that need frontier capability escalate. This is the routing pattern that recovers the 60-80% energy, compute, and cost reductions from IPW versus a batched cloud baseline.
OpenJarvis Prebuilt Agents
Each agent template is expressible because the five primitives sit behind a single typed interface; any slot is swappable without touching the rest. The v1.0 release ships:
- Eight built-in agents across three execution modes (on-demand, scheduled, continuous), including a deep-research agent with inline citations, a CodeAct-style coder, and a continuous monitor with memory compression for long-horizon workflows.
- Seven starter presets that bundle an agent with a hardware-appropriate engine, connectors, and tools, installable with
jarvis init --preset <name>. Variants cover Apple Silicon, Linux GPU servers, and CPU-only laptops. - Four local engines (Ollama, vLLM, SGLang, llama.cpp) and five cloud engines (OpenAI, Anthropic, Google Gemini, OpenRouter, MiniMax), all behind a single Engine interface.
Code: github.com/open-jarvis/OpenJarvis
Website: open-jarvis.github.io/OpenJarvis
What's next?
We're particularly excited about three areas of future research.
Closing the frontier-local gap
A persistent accuracy gap remains between closed-source frontier cloud models and open-source local models, especially on complex reasoning, agentic, and research-heavy tasks. The gap varies substantially by domain: chat and simple retrieval are nearly saturated locally, while browser-based agentic tasks and coding tasks still favor the cloud. Closing this gap matters because it determines how much of the workload can stay on-device without quality regressions, and methods that mitigate it (better local models, smarter routing, hybrid local-cloud protocols) are how local-first deployment becomes the default rather than a tradeoff.
Local-first model architectures
Today's mixture-of-experts models decouple total parameter count (capacity) from per-token compute by activating only a small subset of experts per query, which works well for cloud serving at increasing batch sizes, but wastes resources on single-user local devices, where most experts sit cold across queries. Local devices have an opposite resource profile from datacenters: abundant memory capacity (128GB+ unified memory on modern workstations) paired with relatively constrained memory bandwidth (around 500 GB/s on Apple Silicon versus 4.8-8 TB/s on HBM3e datacenter accelerators), and per-device power budgets in the tens of watts rather than hundreds. The local-friendly architecture should look different: dense rather than sparse, small active footprints, smart quantization, and trained with local serving as a first-class objective. We expect the next generation of open-weight models tuned for local-first deployment to look substantively different from today's releases.
Local-cloud collaboration as a research area
Every project in this arc is an instance of the same underlying question: how should a frontier cloud model and a local model divide labor on a single query, task, or workflow? Minions answered it one way for long-context QA; Archon, Advisor Models, Conductor, ToolOrchestra, and SkillOrchestra answer it differently for other workloads. The field does not yet have a shared vocabulary for comparing these on equal footing. We need a taxonomy that maps workload characteristics to hybrid paradigms (coding wants a specific collaboration protocol, long-context retrieval wants another, agentic tool use wants a third), and we need to extend IPW's profiler to hybrid execution. This is the thread we are most excited to coordinate on with the broader community.

Build with us
We're looking for collaborators across three fronts:
- Researchers working on local-cloud collaboration, efficient local architectures, on-device learning, or intelligence efficiency in ML systems. The OpenJarvis evaluation harness covers 30+ benchmarks across accuracy, latency, energy, cost, and more; we'd love to compare notes.
- Developers building on OpenJarvis or running it on hardware we haven't profiled yet. PRs, issues, and use-case reports all help us understand where the bottlenecks actually are.
- Users willing to point OpenJarvis at their files, calendars, and messaging platforms and tell us what works and what breaks. (All it takes is
pip install openjarvis, thenjarvis init).
Resources:
- Intelligence per Watt initiative: intelligence-per-watt.ai
- Intelligence per Watt codebase: github.com/HazyResearch/intelligence-per-watt
- OpenJarvis codebase: github.com/open-jarvis/OpenJarvis
- Discord: discord.gg/CMVBmDQ5Fj
- Twitter: @OpenJarvisAI