Feb 24, 2025 · 7 min read
Minions: the rise of small, on-device LMs
Embracing small LMs, shifting compute on-device, and cutting cloud costs in the process
TL;DR We shift a substantial portion of LLM workloads to consumer devices by having small on-device models collaborate with frontier models in the cloud. By only reading long contexts locally, we reduce cloud costs with minimal or no quality degradation. We imagine a future where an “intelligence layer” running persistently on-device interacts with frontier models in the cloud to deliver applications with cost-effective, “always-on” intelligence.
🌬️ The Tailwinds: Frontier Models Cost $$$, While Local Hardware Collects Dust

Compute is everywhere—our laptops, phones, cars, and even eyeglasses (shoutout to Chris, and no, not our advisor ❤️) — and the amount of compute on these consumer devices is growing rapidly (e.g. Nvidia just announced a desktop with Blackwell GPUs). Thanks to incredible packages like Ollama 😊 (along with many others), consumer devices can now run surprisingly capable small LMs. While we’re calling them “small”, remember that we’re talking about models that have billions of parameters and can tackle real tasks. And they are improving rapidly.
With models of that caliber on-device, we can envision a world where laptops host always-on coding assistants that look for bugs and refactor our code, personal agents that are tirelessly indexing and organizing our local documents, and smart security systems that detect anomalies before they escalate. We’re getting there—but not quite yet. Today’s local LMs handle more humble tasks, like auto-complete and text summarization. Any moderately challenging task is handled by frontier models on the cloud. However, these models are not cheap. Consider our code refactoring dream; asking OpenAI’s o1 a single question on a respectable code repository (with one million tokens) will cost us >$15!!!
❓ The Big Question: Can Local LMs Step Up?

Small LMs are improving rapidly. Perhaps even more rapidly than their frontier counterparts. But it’s undeniable that for some higher order/domain-specific reasoning tasks (i.e., medical reasoning) frontier models have a clear advantage. Instead of entirely replacing big models with small ones, we ask: can small models on-device collaborate with larger devices in the cloud to solve these challenging tasks at reduced cost?
To mimic the dream use cases mentioned above – of continuous grunt work on device – we analyze three data-intensive tasks, that involve retrieving and integrating data from long, domain-specific documents:
-
Financial analysis over 100-page 10-K reports (FinanceBench)
-
Medical reasoning over patient records (LongHealth)
-
Question answering over scientific papers (QAsper)
💻 The Naive Attempt: Minion

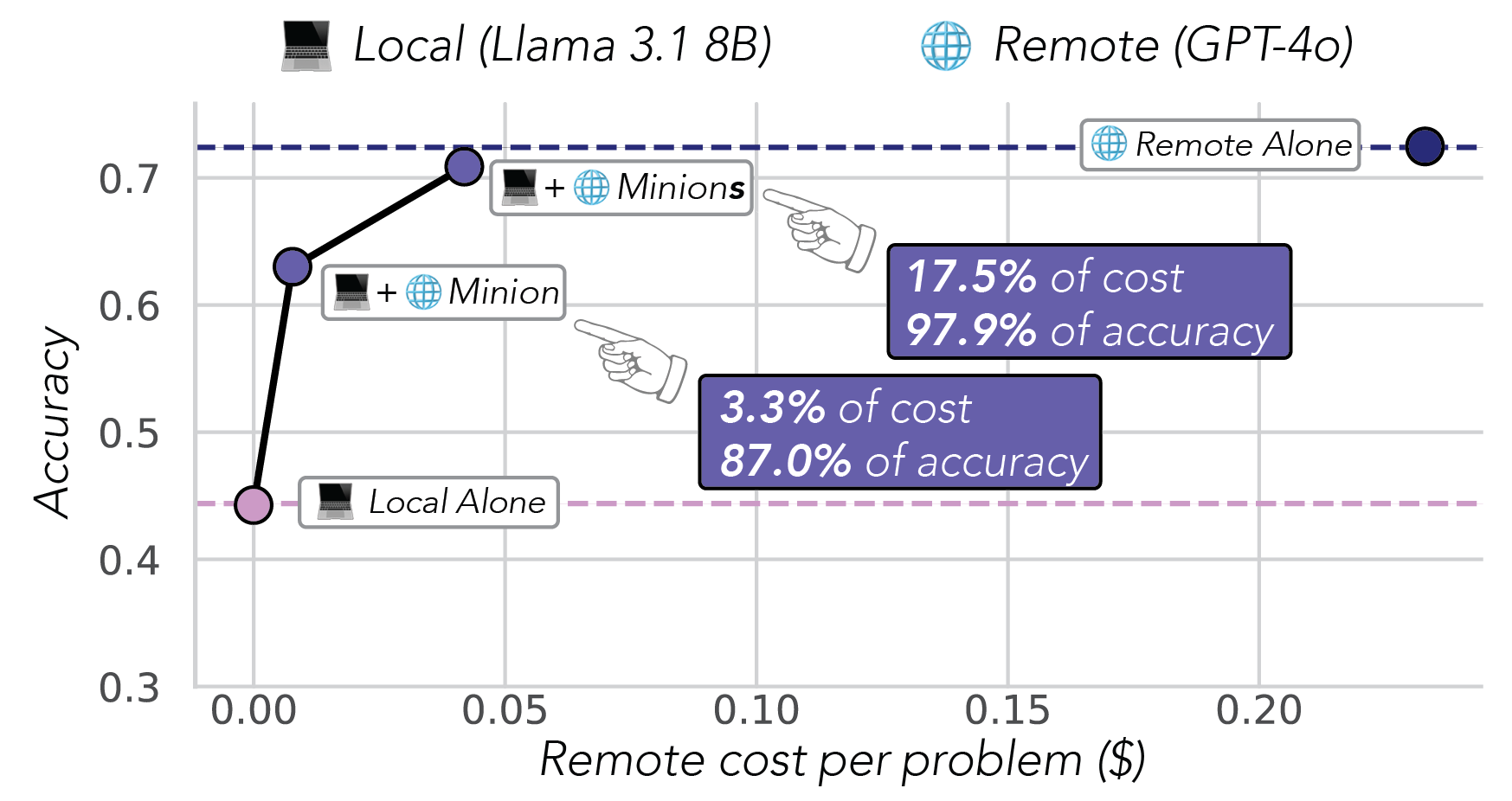
We first tried a simple approach: letting the on-device LM (between 1-8B parameters), which has access to the long documents, chat freely (see Figure 1 below) with a cloud model—like a junior analyst consulting a senior expert. The models choose what information to share and when to terminate the conversation. Since the long document is not sent to the cloud, we pay only 3.3% of the cloud cost while maintaining 87% of cloud model performance. Not bad at all!
But why do we lose 13 points? It seems like performance takes a hit due to two limitations of the current generation of small LMs:
-
Long Context Struggles – As document length increases, small LMs perform worse.
-
Multi-Step Confusion – As instructions become more complex and multipart, small LMs struggle to follow them reliably.
Beyond these challenges, hardware utilization (on consumer GPU like 4090) remained low, leaving potential accuracy gains on the table (h/t Large language 🐒’s). A back-and-forth chat does not take advantage of batching on-device, which is crucial for achieving high utilization.

🎩 The Sophisticated Attempt: Minions

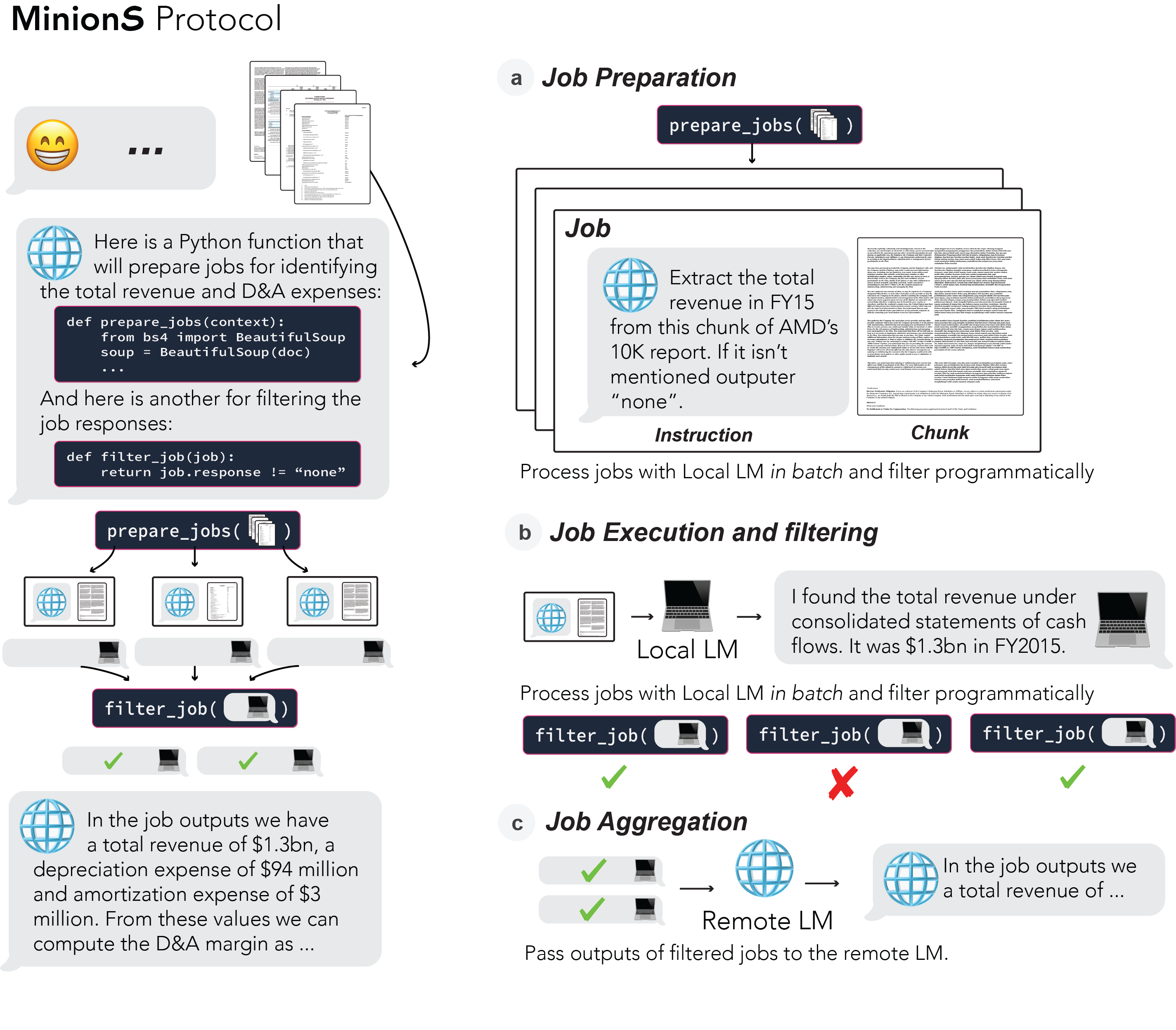
The lessons we learned led us to the enhanced Minions protocol (emphasis on plural S). Minions introduces a decomposition-execution-aggregation loop that addresses the weaknesses of small LMs, while making them work harder (in Minions, we work harder *and* smarter).
Here is how it works:
-
Decompose – The remote LM decomposes the task into smaller, single-step subtasks to be executed on chunks of the context. But how can it decompose the task and chunk the context without seeing it? To this end, we have the remote LM generate code for task decomposition and chunking, that is executed on-device where the context is available.
-
Execute – The local LM runs the subtasks in parallel, filtering only the most relevant outputs and communicating them to the remote LM.
-
Aggregate – The remote LM combines the local outputs, finalizing the answer or looping and requesting another round of subtasks.
Minions delivers 97.9% of the accuracy of remote-only solutions while costing just 17.5% as much!
🔍 Tuning The Minions
Digging deeper, we found key levers that allow us to navigate the cost-accuracy tradeoff:
-
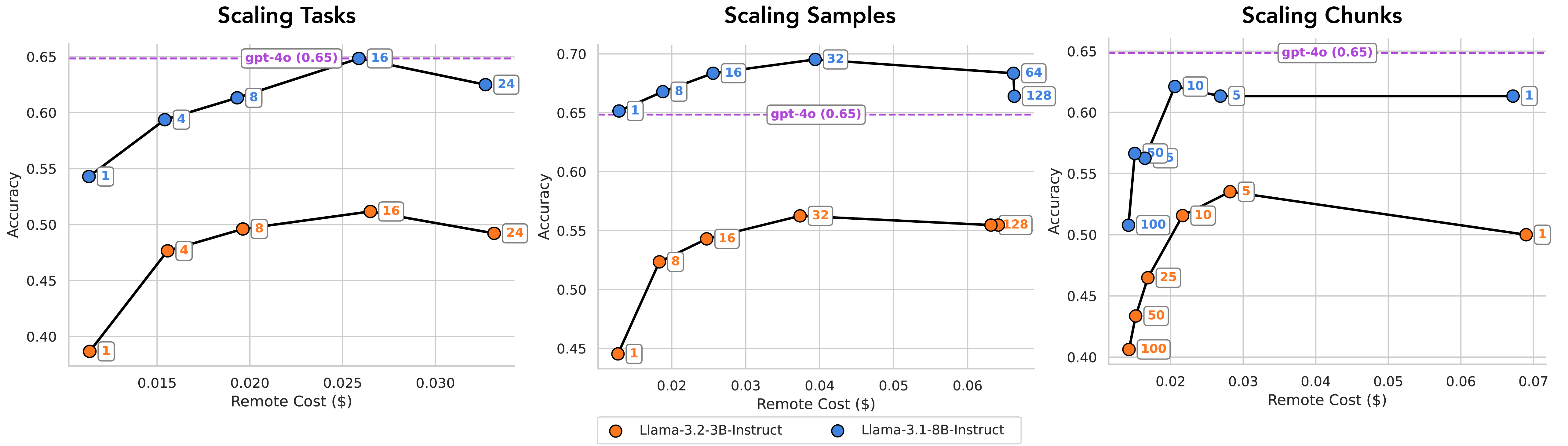
Model Choice Matters – Currently, local models below 3B parameters are not effective for the Minion/Minions protocols. By fixing the remote model and varying the local model (exploring different sizes and generations), we show that the Minions protocol wouldn’t have been feasible until mid-2024 (until the release of gpt4-turbo and llama3.1-8B)!
-
Scaling Inference-Time Compute Improves Performance – Techniques like repeated sampling, finer-grained decomposition, and context chunking (see Figure 4) at the execution stage boost quality—but at the cost of longer runtimes on laptops and increased remote usage. This is illustrated with the scaling curves in the figure below.
-
Sequential Communication Helps – Allowing for more communication rounds generally improves accuracy at the cost of compute.
🚀 To infinity and Beyond

Minions is a first step towards establishing a communication protocol between small on-device LMs and frontier LMs. As GPUs become ubiquitous across consumer and edge devices, we need smarter ways to distribute AI workloads—reducing reliance on expensive cloud APIs while unlocking powerful local applications. If you are a practitioner, researcher, or hacker, we’d love to get you involved with Minions:
-
Practitioners: we encourage you to apply Minions to your own workloads — please see our GitHub repository to quickstart.
-
Researchers: we see significant opportunities for further research, including improving communication efficiency through better co-design of local and remote models, alternative communication signals beyond natural language, and enhancing inference speed via systems and algorithmic advances.
-
Hackers: we are just getting started with Minions, and are excited to continue building. If you are excited by our vision, we’d love to see PRs and new projects that expand our community!
📚 Additional Resources
- How do you use Minions? Check out our Github here for sample scripts: https://github.com/HazyResearch/minions
- Want to learn more? Read our paper here: https://arxiv.org/abs/2502.15964
🙏 Acknowledgements
A huge thank you to Jeff Morgan, Michael Chiang, Patrick Devine, and the entire Ollama team for their support throughout this release. We’re also grateful to Together AI for generously providing compute resources and credits. Lastly, thanks to the many folks who have provided invaluable feedback on this work - Aditi Jha, Andrew Drozdov, Cody Blakeney, Jordan Juravsky, Jon Saad-Falcon, Ben Viggiano, Mayee Chen, Neel Guha, Jerry Liu, Kelly Buchanan and Michael Zhang.