Dec 10, 2024 · 9 min read
Smoothie: a label-free approach for inference-time LLM routing
Neel Guha, Mayee F. Chen, Trevor Chow, Ishan S. Khare, Christopher Ré
TLDR: We study algorithms for LLM-routing in the inference-time setting: given open-ended generations from K different LLMs for an input, can we learn to select the best generation, without needing any labeled data? Our algorithm, Smoothie, accomplishes this, and we show it can achieve substantial gains over other unsupervised baselines for generation tasks (e.g., instruction-following, NLG, and more)–by up to 27 points.
Motivation
Our work builds on two trends in LLM development and usage over the last twelve months.
- The first is the mechanism of routing. Routing leverages the idea that specific “expert” submodules, each with their own strengths and weaknesses, can work together effectively when samples are directed to the most appropriate submodule. This approach, in contrast to monolithic AI systems, enables systems to harness the collective intelligence of its components.
- The second is the paradigm of test-time compute.1 In this regime, developers are able and willing to allocate more resources at inference-time to produce high quality generations. In particular, they can produce multiple outputs from a single LLM–or multiple LLMs–for a single input.
Recent work has begun exploring the intersection of these areas–a paradigm known as inference-time routing. For example, rather than producing a response from one model for an instruction, developers will (1) produce responses from multiple different models, and then (2) identify the best response to return to the user. Typically, this requires labeled training data—either to simply identify the best model or to train a router, such as an MLP classifier or a KNN retrieval model. However, acquiring this labeled data in the context of model routing can be resource-intensive. For each training sample’s input, we first need to generate the responses from all the LLMs in the ensemble. Then, we must annotate each LLM generation’s quality, or write a reference output and use some scoring mechanism against this reference to score each generation (using metrics like ROUGE, BARTScore, or LLM-as-a-judge. This can be time-intensive for open-ended generation—imagine manually writing out a summary of a Dostoevsky novel or comparing multiple LLM-generated summaries of it!2
Our work introduces an algorithm for inference-time routing, which we call Smoothie. Given a test set of inputs and generations from K different LLMs for each sample in this test set, Smoothie “selects” which LLM’s generation should be used for each sample. We think Smoothie is exciting for three reasons:
- Smoothie works for open-ended generations: instruction-following, summarization, data-to-text, and more! It’s not constrained to purely classification tasks. The key innovation is that while ensembling techniques are well-established for classification, our approach can ensemble outputs for open-ended generative tasks.
- Smoothie does not require labels! No data needs to be annotated, compared, or ranked.
- Smoothie is extremely efficient, and just requires computing embeddings of every LLM’s generations with a small encoder (e.g., BERT)! No training is required!
The remainder of this blogpost describes Smoothie at a high level, and some of our experimental results. If you’d like the more detailed version, we recommend you check out the paper!
Smoothie
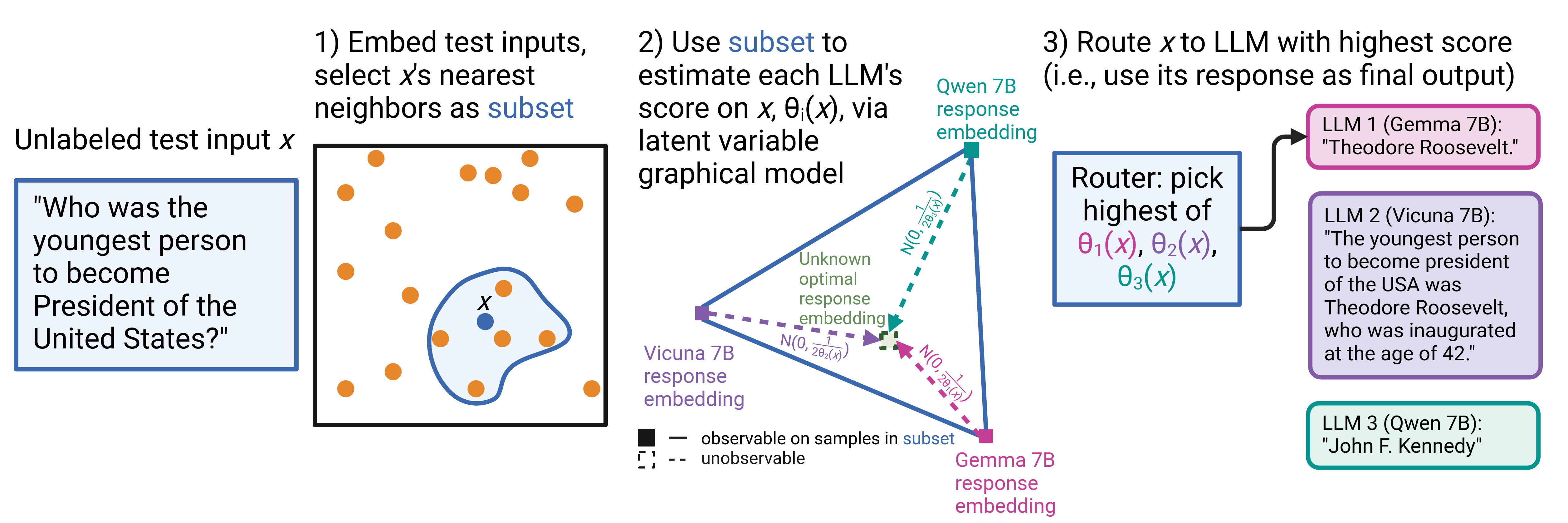
At a high-level, Smoothie treats the LLM generations for each test sample as “voters” on the unknown ground-truth label. Using an approach inspired by Weak Supervision, which uses probabilistic graphical models to aggregate noisy labels for annotating training datasets, Smoothie estimates a quality score for each LLM by looking at the generations’ embedding similarities (“voter agreement”). We then route the test sample to the LLM with the highest estimated score.
Intuition: majority vote on classification tasks. The intuition for Smoothie is rooted in the rule-of-thumb that *agreement* among many voters often translates into high-accuracy voters—a principle present in majority vote as well as weak supervision. As an example, suppose that we wished to determine what LLM to route to for a binary classification task like sentiment analysis. If we had 5 models and they generated ['positive', 'negative', 'positive', 'positive', 'positive'] as their responses, then a majority vote tells us that it’s likely that the sentence does have positive sentiment. Then, we could select the first, third, fourth, or fifth model to use for this sample, since they all generate the majority output. We could improve on this by using a “weighted majority vote” via Weak Supervision algorithms, which are able to learn these weights without labeled data. As an example of intuition behind the weighted vote, suppose that model #2 tends to disagree with all other models; then, there’s a good chance it’s low-quality, and we’d want to downweight its vote.
Smoothie’s insight: how to vote on open-ended generation tasks. The above method described only works when we work with classification tasks, where a notion of agreement among LLM generations is simple. I.e., two models “agree” when they produce identical class predictions. But how do we extend this to generation tasks? How do we determine how much two LLM-generated summaries of Dostoevsky agree with each other?
Our insight is to utilize model embeddings3. Smoothie embeds each LLM generation (using an off-the-shelf embedding model), and then uses the euclidean distances between embeddings to express agreement. Smoothie determines the quality score of each LLM by using the following idea: LLM generations that have low Euclidean distances with all other generations (i.e., are close to the ‘centroid’ of all the generations) are assigned high quality scores, while outlier LLM generations that are far from other generations are assigned low quality scores.
Finally, we construct two versions of Smoothie, Smoothie-Global and Smoothie-Local, where the former produces just one quality score per LLM by averaging agreements over the entire test dataset, while the latter produces a per-sample score by using just the k-nearest neighbor samples (where k=1 when we just have one test sample available). Which version to use largely depends on practitioner preference—are you happy with just figuring out the best LLM for your task, which might be easier to integrate with your pipeline, or do you want to optimize farther to find the best LLM for each task sample?
Bonus: the math behind Smoothie. The description above provides high-level intuition regarding Smoothie, but the more formal details are in our paper. For statistics fans though, here’s the core idea: Smoothie’s estimated quality scores are actually a consistent, method-of-moments parameter estimator for a latent variable graphical model—specifically, a multivariate Gaussian random vector. In this model, we treat the vector difference between each LLM response embedding and the unknown ground-truth embedding as a Gaussian variable with mean 0 and a diagonal covariance matrix. The covariance matrix has entries that are inversely proportional to the LLM quality score, reflecting the assumption that each LLM’s generation quality is independent. To estimate the quality scores, we draw on great work from Shin et. al., which exploits independence assumptions in the graphical model and allows us to bypass the need for labels to determine quality.
Results
We encourage taking a look at the full paper to learn more about our experiments, but here are some quick highlights.
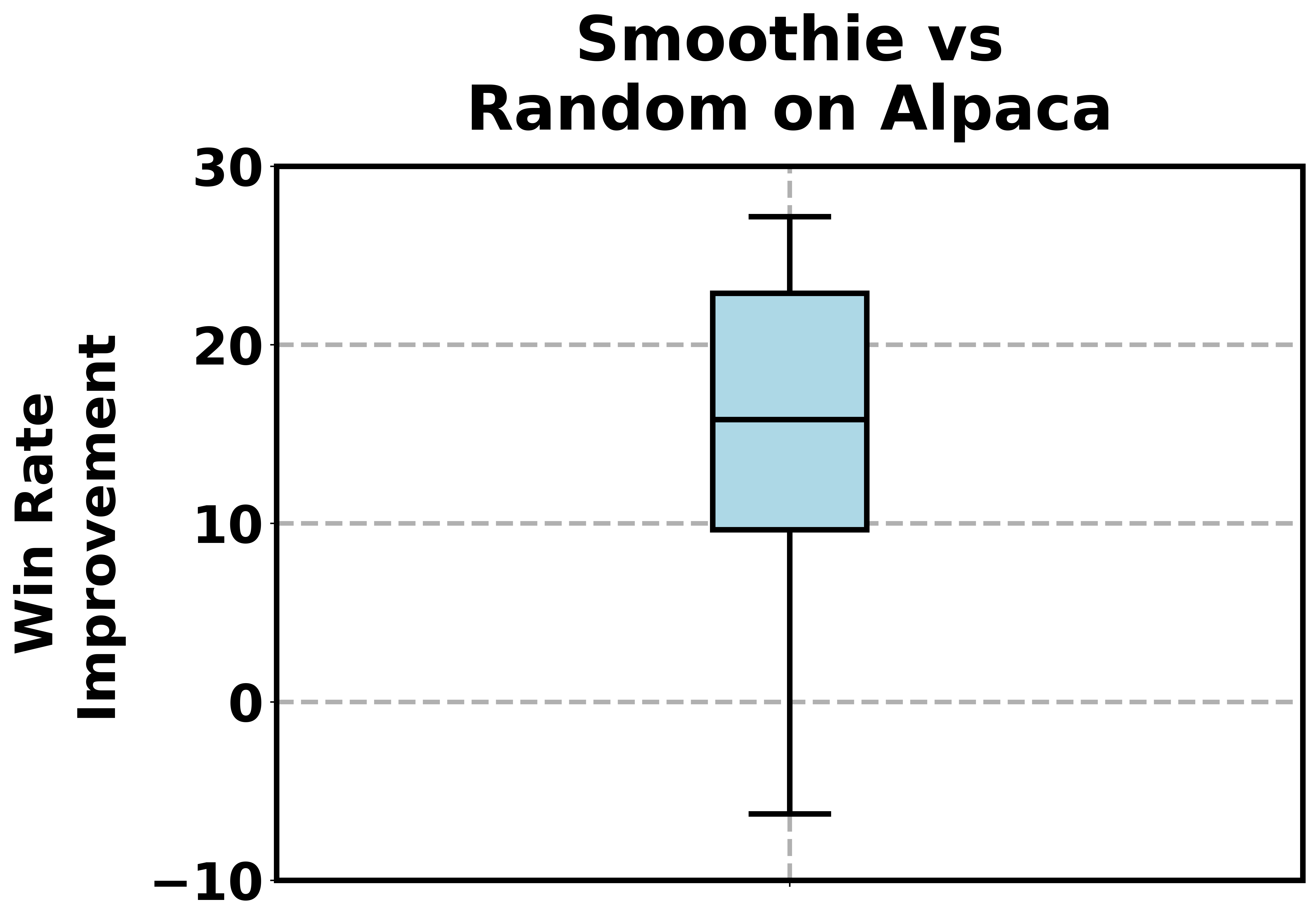
- AlpacaEval is an instruction-following benchmark, with generations of many leading LLMs available on its leaderboard. When we apply Smoothie-Global to route AlpacaEval samples to one of five LLMs, we achieve an average of 15 points improvement—and a maximum of 27 points—in win-rate against GPT-4 references, compared to randomly selecting one of the LLMs.
- We created a multi-task dataset (SQuAD, TriviaQA, and Definition Extraction) and applied Smoothie-Local to it using an ensemble of five 7B models. Smoothie improves over random routing by 9.6 points accuracy, and also outperforms labeled baselines.
- Smoothie-Local routed to the highest-accuracy LLM per sample over 75% of the time across the multi-task dataset.
| Method | Multi-task routing accuracy |
|---|---|
| Random | 65.4 |
| PairRM | 71.8 |
| Labeled KNN | 71.7 |
| Best Model | 73.2 |
| Smoothie-Local | 75.0 |
Check out our paper for more results, including: 1) evaluation on additional datasets like Mix-Instruct, GSM8K, and summarization tasks; 2) a more efficient variant of Smoothie that does not require obtaining all the generations per test sample in advance; and 3) an application of Smoothie to prompt selection.
Future directions
If you’re interested in chatting more, please reach out to Neel Guha (nguha@stanford.edu) and Mayee Chen (mfchen@stanford.edu)! We also encourage taking a look at our code, especially this simple tutorial we put together for how to easily apply Smoothie to your routing workflows.
We’re really excited about this direction, and applying classical statistical tools to new versions of problems as they manifest in the current age of generative AI. We see Smoothie as the first step, and believe there’s room to get significantly better! For example:
- Beyond just embeddings, how can we incorporate other forms of signal to determine LLM response quality, such as reward models and unit tests?
- How do we make Smoothie better for structured tasks with a clearer notion of correctness? We observe some promising results on GSM8K, but we’d like to investigate this further....
Lastly, we’d like to thank Simran Arora and Jon Saad-Falcon for their helpful feedback on this post!
- Check out some other work by our lab here, on test-time compute scaling curves and leveraging test-time compute for compound systems!↩
- Aside from manual annotation, using LLMs to label the quality of the training data for routing might be less time-consuming. However, it can still be costly and can also introduce additional biases, such as preferring longer generations.↩
- Using model embeddings to improve weak supervision approaches has been explored previously for classification tasks, such as Liger and Embroid.↩