Repo: https://github.com/HazyResearch/ThunderKittens
With team: Benjamin Spector, Simran Arora, Daniel Y. Fu, Chris Ré

AI has grown tremendously through the teraflops of compute that bigger and bigger GPUs have brought online. With ThunderKittens (TK), we've explored how we can write performant and cute AI kernels on the biggest and baddest AI hardware out there.
While hardware utilization is undeniably crucial for large-scale AI in data centers, there's an equally exciting and transformative frontier on the other end of the spectrum: on-edge training and inference. Efficiently running ML on-edge enables greater amounts of user privacy, unlocks the development of models tailored to user-specific preferences, and invites a broader community to accelerate AI research.
Inspired by these possibilities, we wanted to write AI kernels for Apple Silicon and thought it would be fun to build a TK port for MSL (Metal Shading Language). This seemed like the perfect test for TK. The general vision for the DSL was to design around fundamental hardware properties - now, we wanted to explore how these primitives would hold up when put to the test on a completely different race track: the Apple M2 Pro.
Understanding The Apple GPUs
First, we decided to take a deep dive into hardware properties:
The M2 Pro has very high memory bandwidth relative to compute: ~200GB/s memory bandwidth and ~6.5 TFLOPs of compute. For comparison, the closest consumer-facing NVIDIA GPUs - the RTX 4090s - have ~1000GB/s memory bandwidth and 82.58 TFLOPs of compute. The 4090s get 2.5x flops per byte loaded!
For the M2 Pros, this broadly means:
- Shared memory isn't as crucial. ALUs can be kept active by directly loading values from HBM into registers, almost never leveraging shared memory for things like reuse.
- Incredibly simple kernels (without fancy producer/consumer asynchrony, for example) get the job done.
- Swizzling isn't worth the hassle (for now). ALU ops are too precious to be used for faster memory loads, so the simple and reasonable solution to bank conflicts is padding.
- Limited support for bf16. The compiler generally struggles to optimize bf16 ops. This led us down the unfortunate path of using some, shall we say, "aesthetically challenged" code to force the compiler's hand (i.e., meta template loop unrolling).
- Occupancy matters. A lot. Writing a fast FA kernel for D=128 is no walk in the park. Register use goes up, occupancy goes down, and performance takes a nosedive (yes, it's a delicate balancing act).
Porting ThunderKittens To Metal
So, we present... 🥁🥁🥁 ThunderMittens!!! The Apple Metal port for ThunderKittens
Most of TK was developed on H100s and most of its kernels are optimized for H100s. While the H100s and the Apple M2 Pro might seem like they're from different worlds, we were surprised to see how well our primitives held up.
How many major abstraction changes did we have to make? One. Wait, really? Yep, that's it.
The only major change a TK user needs to pay attention to is going from 16x16 base tiles to 8x8 base tiles. We do this because the M2 Pro can maximally allocate 128 registers per thread. The 8x8 base tiles also work nicely with the metal::simd_matrix<T,8,8> intrinsic.
Under the hood, relevant internals are modified/removed:
- Register layouts. The metal::simdgroup_multiply_accumulate intrinsic expects different layouts from the NVIDIA WGMMA instructions. Fortunately, a little shuffle dance does the trick.
- Swizzling. As discussed above, swizzling is disabled in ThunderMittens—the address calculations just can't be justified given the limited compute and speedy memory.
- WGMMA & TMA: These instructions are NVIDIA specific.
- Async loads/stores: These are currently deprecated on the M2s—we got things working without them.
With these changes, writing SOTA/near-SOTA performance Apple Metal kernels is a breeze. The true differences in hardware shine through not in the abstractions themselves, but in how they're used!
GEMM Kernel Implementation
See our GEMM kernel here:
namespace mittens {
template<typename T, unsigned N_BLOCK, unsigned K_BLOCK, unsigned M_BLOCK>
kernel void matmul(device T* D [[buffer(0)]],
device T* A [[buffer(1)]],
device T* B [[buffer(2)]],
const constant int &N [[buffer(3)]],
const constant int &K [[buffer(4)]],
const constant int &M [[buffer(5)]],
uint3 tg_id [[threadgroup_position_in_grid]],
uint simd_lane_id [[thread_index_in_simdgroup]]) {
using global_layout = gl<T, 1, 1, -1, -1>;
global_layout gl_a(A, nullptr, nullptr, N, K);
global_layout gl_b(B, nullptr, nullptr, K, M);
global_layout gl_d(D, nullptr, nullptr, N, M);
rt<T, N_BLOCK * TILE_DIM, K_BLOCK * TILE_DIM> a_reg;
rt<T, K_BLOCK * TILE_DIM, M_BLOCK * TILE_DIM> b_reg;
rt<float, N_BLOCK * TILE_DIM, M_BLOCK * TILE_DIM> d_reg;
zero(d_reg);
#pragma clang loop unroll(full)
for (int k = 0; k < K / (K_BLOCK * TILE_DIM); k++) {
kittens::ore::load(a_reg, gl_a, {0, 0, (int)tg_id.y, k}, simd_lane_id);
kittens::ore::load(b_reg, gl_b, {0, 0, k, (int)tg_id.x}, simd_lane_id);
mma_AB(d_reg, a_reg, b_reg, d_reg);
}
store(gl_d, d_reg, {0, 0, (int)tg_id.y, (int)tg_id.x}, simd_lane_id);
}
}
Attention Inference Kernel
And our standard attention inference kernel:
template<int D>
kernel void attend_ker(constant unsigned &N [[buffer(0)]], constant unsigned &H [[buffer(1)]],
device bf16* q [[buffer(2)]], device bf16* k [[buffer(3)]],
device bf16* v [[buffer(4)]], device bf16* o [[buffer(5)]],
uint3 blockIdx [[threadgroup_position_in_grid]],
uint laneId [[thread_index_in_simdgroup]]) {
static_assert(D == 64 || D == 128, "D must be 64 or 128");
using global_layout = kittens::ore::gl<bfloat, 1, -1, -1, D>;
global_layout gl_q(q, nullptr, H, N, nullptr);
global_layout gl_k(k, nullptr, H, N, nullptr);
global_layout gl_v(v, nullptr, H, N, nullptr);
global_layout gl_o(o, nullptr, H, N, nullptr);
rt_bf<8, D> q_reg, v_reg;
rt_bf<8, D, ducks::rt_layout::col> k_reg;
rt_fl<8, 8> att_block;
rt_fl<8, D> o_reg;
rt_fl<8, 8>::col_vec max_vec, max_vec_last, norm_vec;
const int block = blockIdx.z, head = blockIdx.y;
const int q_seq = blockIdx.x;
const int kv_blocks = N / v_reg.rows;
load(q_reg, gl_q, {block, head, q_seq, 0}, laneId);
neg_infty(max_vec);
zero(norm_vec);
zero(o_reg);
constexpr const bf16 q_mul = ((D == 128) ? 0.08838834764bf : 0.125bf) * 1.44269504089bf;
mul(q_reg, q_reg, q_mul);
#pragma clang loop unroll(full)
for(auto kv_idx = 0; kv_idx < kv_blocks; kv_idx++) {
load(k_reg, gl_k, {block, head, kv_idx, 0}, laneId);
zero(att_block);
mma_ABt(att_block, q_reg, k_reg, att_block);
copy(max_vec_last, max_vec, laneId);
row_max(max_vec, att_block, max_vec, laneId);
sub(max_vec_last, max_vec_last, max_vec);
exp2(max_vec_last, max_vec_last);
sub_row(att_block, att_block, max_vec);
exp2(att_block, att_block);
mul(norm_vec, norm_vec, max_vec_last);
row_sum(norm_vec, att_block, norm_vec, laneId);
mul_row(o_reg, o_reg, max_vec_last);
load(v_reg, gl_v, {block, head, kv_idx, 0}, laneId);
mma_AB(o_reg, att_block, v_reg, o_reg);
}
div_row(o_reg, o_reg, norm_vec);
store(gl_o, o_reg, {block, head, q_seq, 0}, laneId);
}
Performance Results
So, how do these perform? The attention kernel is within +- 15% of MLX's implementation and our GEMM is ~9% faster on most sizes.


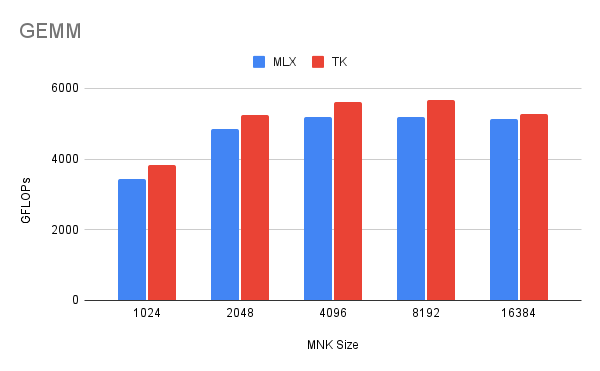
Importantly, the kernels continue to be simple to write. While the MLX GEMM implementation takes over a hundred lines of code to write, ours gets the job done in 11. The DSL's abstractions coalesce the differences between Metal and CUDA, such that our attention kernels on 4090s and the M2s are effectively identical (4090 attention). Since both kernels are implementations of the FA algorithm, they consist of the same set of TK tile-based ops. However, the NVIDIA 4090s and M2 Pro GPU are also very different from each other, and that's alright: in TK, you can do things like swap in HBM-to-register loads for Metal (vs HBM-SMEM loads for 4090s). The DSL acknowledges that different pieces of hardware may very well want to run the same algorithm differently.
Writing Metal Kernels
Despite the similarities in our TK kernels, there are notable differences in how we write kernels in Apple Vs NVIDIA. Most development was done in XCode. This gave us easy access to profiling through tools like the XCode Metal GPU Debugger. While distinct from NCU, the debugger has proven invaluable for ThunderMittens. We attach an example below of what we were staring at for 90% of our dev time.

We often found that the statistics provided to us by the debugger were not enough for thorough profiling. Repetitive trial and error seemed to be best for detailed understandings of our primitives.
More To Come...
Even with our notable results, the Apple MLX port is still in its early stages. There are many more architectures (Based linear attention, FFTConv, Mamba) that we’d like to write kernels for in ThunderMittens. We’re also excited about how the primitives change with the M3s and M4s. We’re always open to and would love to support open-source contributions to the repo!