Aug 21, 2023 · 10 min read
A Paradigm Shift in ML Validation: Evaluating Workflows, Not Tasks
It’s no surprise that recent advances in machine learning are starting to change how we think about the role of ML in applied domains. Doctors are using foundation models to write insurance letters to accelerate approval of life-saving care. Computational biologists are discovering new protein structures faster than ever. And teachers can finally design their lesson plans without sacrificing multiple nights of sleep.
But as applications of ML become more pervasive, how do we make sure these models work the way we want them to? Are our current validation methods sufficient?
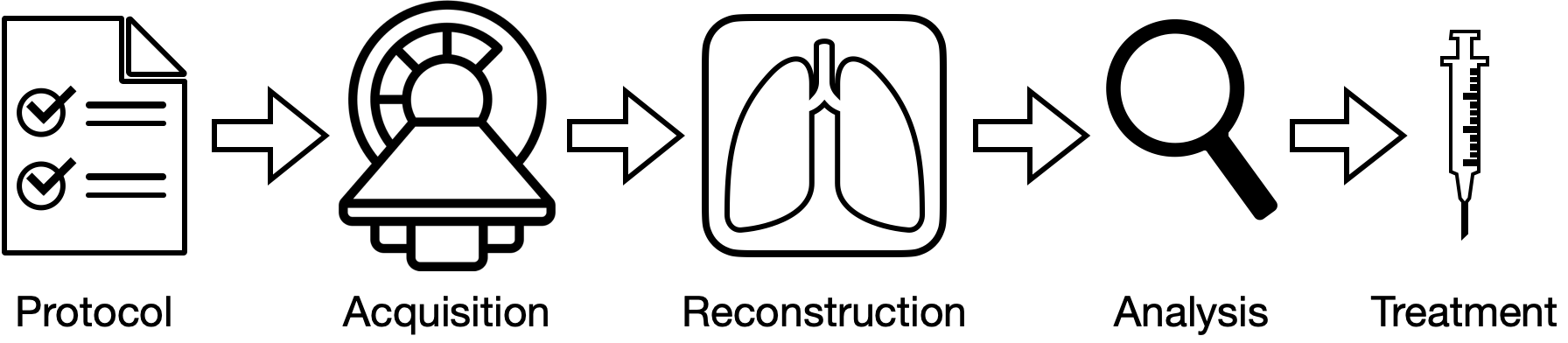
Workflows, like those in medical imaging, are composed of multiple tasks. The quality of later (downstream) stages of the workflow (e.g. analysis, treatment) depend on earlier (upstream) stages (e.g. how well images were acquired and reconstructed). Historically, machine learning benchmarks have been built for many of these tasks in silo, and thus, are not designed to evaluate methods as a part of an end-to-end workflow.
Over the past few years, we have been quite interested in how we can reimagine ML validation to be focused on user workflows rather than individual tasks. In this blog, we’ll dive into the bottlenecks and exciting directions we’ve explored for designing datasets & benchmarks for workflow-centric validation, particularly in medical imaging.
A brief history of ML validation
Over the years, the ML community has rallied around building open-source benchmarks spanning a wide array of applications. While data and tasks across these domains are heterogenous, ML benchmarks have helped unify them by standardizing tasks and validation procedures. This standardization has simplified comparison and made it easier to build and test ML methods in applied domains.
However, in practice, these tasks are just small steps of much larger pipelines. For example, a doctor could use ML-assisted tools for detecting pneumonia in an X-ray. But it is the combination of this detection with other analyses (patient history, lab results, previous scans, etc.) that determines how the doctor treats the patient.
The problem is that evaluating performance on a specific task is often not a good indicator of the quality of end-to-end workflows (e.g. in medical imaging). In these scenarios, we would want validation protocols that not only evaluate if a model is good for some task(s), but also evaluate how the model impacts a user’s end-to-end workflow.
One way to make ML systems useful in practice is to shift ML validation from being task-centric to being workflow-centric.
What is a workflow?
A workflow can be (loosely) defined as a sequence of tasks (x → y → z) performed to extract information relevant to a user’s decision making. In this paradigm, tasks are just small components that can be composed together as part of a larger end-to-end process. These tasks can be performed by different operators (e.g. ML models, human experts), each with different operating capabilities (e.g. speed, quality) and error profiles. Naturally, the quality of downstream tasks, tasks performed at later stages of the workflow, is dependent on the quality of upstream tasks, those performed at earlier stages. For example, in the medical imaging workflow shown above, the quality of the reconstructed image will influence the quality of our analysis, and thus, the treatment we administer to the patient.
Workflows are typically designed to give outputs that are interpretable by the user (e.g. a domain expert). This allows the user to make decisions based on metrics that they care about. For example, in cancer care, oncologists would be interested in identifying traits such as the size of a tumor, how far the cancer has spread (i.e. metastasis), and what treatment solution (chemotherapy, radiation, etc.) would be most potent.
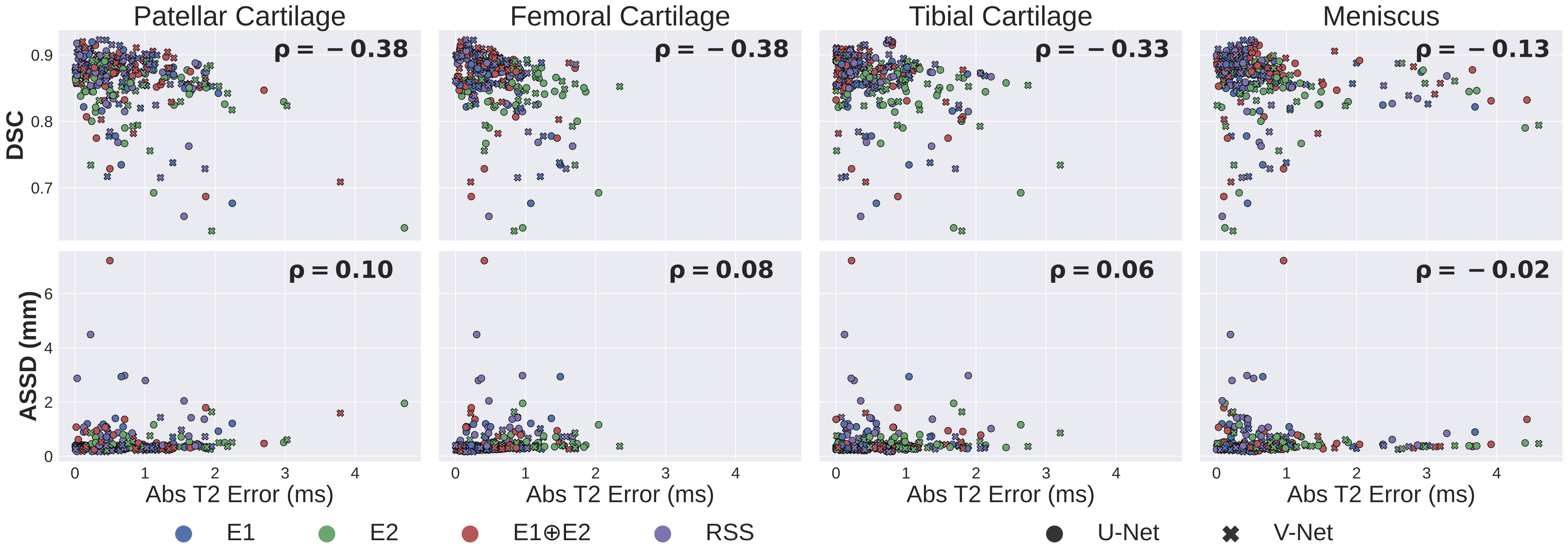
Standard metrics used for benchmarking ML algorithms for knee MRI segmentation — e.g. Dice (DSC) and average symmetric surface distance (ASSD) — are poorly correlated (p) with clinically-relevant biomarkers, such as estimates in MRI.
Why can evaluating workflows help?
Workflow-centric validation shifts the focus from evaluating the ML model to evaluating how successful a user’s workflow would be if they were to use the model. In other words, we care about the quality of the full workflow rather than only the quality of a single or a few tasks. This perspective can give us a realistic working template of how ML models can be used successfully in practice.
By thinking of a workflow as a series of tasks, we can also study error propagation — i.e. how do errors in upstream tasks impact quality among downstream tasks? This paradigm allows us to better understand how these errors affect the overall quality of the workflow. For example, we can ask: “How much do errors in my reconstructed image affect the treatment I prescribe to my patient?”
Relatedly, understanding user workflows is also critical for understanding what outcomes matter to the ML users. Historically, ML benchmarking has evolved to focus on generalist metrics, like accuracy, AUROC, or Dice, but these metrics may not be correlated with the user-relevant outcomes. This makes it difficult to gauge how ML models will translate from benchmarks to the quality metrics users care about in the real world.
Designing workflow-centric datasets and benchmarks in medical imaging
In light of these challenges, we have been quite excited by how we can enable workflow-centric validation, specifically in the context of how we design datasets & benchmarks. We believe there are two fundamental principles that differentiate workflow-centric datasets from standard ML datasets:
- The dataset mirrors user workflows. This means data is collected from different stages of the workflow and models can be built to benchmark at each stage independently and on the workflow as a whole.
- The dataset allows us to measure the quality of user-relevant outcomes. In other words, we can define new metrics that are more aligned with what the user cares about.
A few years ago, we applied these principles when building the Stanford Knee MRI with Multi-Task Evaluation (SKM-TEA [pronounced: skim tē]) dataset, a 1.6TB dataset of clinical knee MRIs consisting of raw data, reconstructions, segmentations, detection, and classification labels. By including ground truth labels at different stages of the MRI pipeline, SKM-TEA enables model developers to benchmark MRI workflows in an end-to-end manner, from acquisition, to reconstruction, to analysis. The dataset also complements standard ML benchmarking metrics with a new clinical-relevant metric based on a workflow for estimating , a biomarker that can help characterize biochemical properties of tissues.
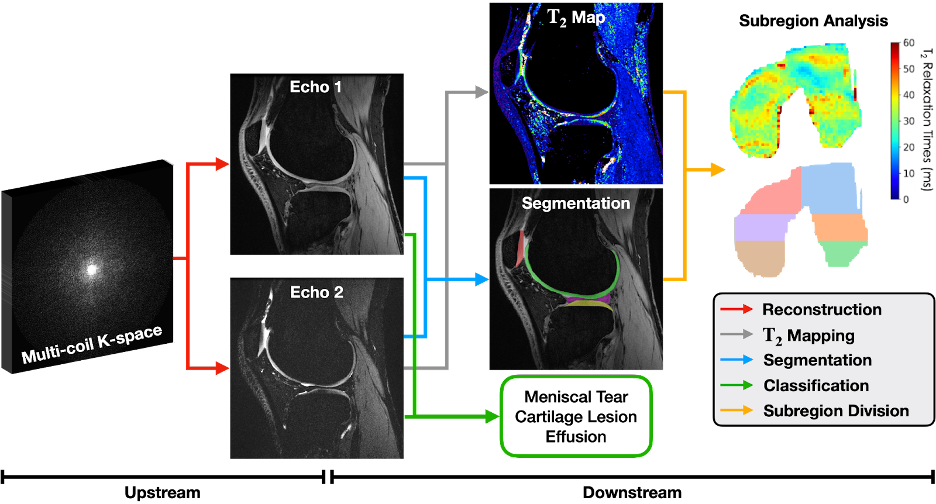
An example knee MRI workflow in SKM-TEA for quantifying biochemical properties of tissues and detecting pathology. Raw data must first be reconstructed into images (red arrow), which then can be used for downstream analysis tasks like pathology detection/classification (green arrow) and tissue segmentation (blue arrow). Reconstructed images and tissue segmentations can also be used to estimate regional , a clinically-relevant biomarker for measuring biochemical changes in different regions of the knee.
Since the release of SKM-TEA, we’ve been very excited to see new methods being benchmarked in an end-to-end way. New MRI reconstruction methods are being designed to be aware of downstream tasks, and model developers are starting to use biomarker-based metrics as a routine endpoint for evaluation. With this dataset, we’ve even been able to run larger retrospective studies for looking at diverse clinical biomarkers across different stages of the MRI pipeline.
What are the challenges?
Despite the advantages of workflow-centric validation, building and adopting these benchmarks is not easy, for many reasons:
- Workflows aren’t public: In many cases, clear definitions or code for workflows are seldom available. If they are available, they are rarely built for public use (e.g. not modular, no clear entry points). Like traditional benchmarking, this makes it challenging for creating transparent understanding where the gaps in performance are.
- Analysis workflows are not standardized: In any domain, users have particular, often personalized, workflows, which makes it difficult to standardize what workflows warrant benchmarking. In fact, these workflows are so unstandardized that the FDA (and other regulatory agencies) rely on companies asking for ML approval to define their own testing procedure.
- Too much work: Frankly, validation can be hard to orchestrate. Labeled data for benchmarking each task of a workflow is not always available and is often expensive to collect. Additionally, evaluating models when the workflows are vague and hard to benchmark make it even less appealing to do.
- Metrics qualitative utility: User interaction is inherently a qualitative process, and it’s no different when we think about how users would interact with ML tools. However, current metrics are not designed to capture the nuances of how users would feel when interacting with these ML systems.
A path forward
Fortunately for us, solutions to these challenges are rooted in actions that the ML community has excelled at:
- Facilitate open-source: Work with domain experts to develop and distribute their workflows and associated user-informed metrics. This can help establish some user-led consensus on end-to-end workflows where ML methods can be helpful for their fields.
- Make workflows usable: Build benchmarking suites so that with minimal code, users can get up and running with endpoint-driven workflows. This can reduce the barrier on entry for both ML experts with limited domain knowledge and domain experts with limited ML knowledge.
- Show user utility: Demonstrate that evaluating models in a workflow-centric way actually leads to downstream outcomes for patients (less cost, better prognosis, etc.). Making these benchmarks visible to the public ensures there is transparency, which is critical for facilitating ML adoption.
- Build interactive tools: Use user interfaces to ground the qualitative nature of user-model interactions in more quantitative metrics (time to success, rate of retention, etc.). Libraries like Streamlit and Gradio have considerably simplified building applications for ML models. More recently, we built Meerkat to focus on bridging the gap between ML models and data interfaces, which can help with large scale data visualization and exploration, and qualitative validation studies for new ML tools.
A Meerkat interface for conducting reader studies to evaluate image reconstruction quality.
We are excited to keep pushing the boundaries of applied ML validation, especially with the rapid proliferation of new application-driven foundation models and their benchmarking. If you’re interested in these directions, please reach out!
Aside: While this blog post has been about medical imaging, it is far from the only setting where workflow-centric validation can be a huge unlock. We are starting to see similar trends emerging in a variety of different applications in medicine (e.g. analyzing electronic health records), law, drug discovery, among others. Studying how different fields handle the validation and (at later stages) approval for using this ML tools will be critical for improving validation generally for applied ML domains.
Acknowledgements
Many thanks to Chris Ré, Shreya Rajpal, Brandon Yang, Karan Goel, Sabri Eyuboglu, Akshay Chaudhari, and Parth Shah for their feedback on this post.