Jun 13, 2023 · 7 min read
Why is in-context learning lower quality than fine-tuning? And…what if it wasn't?
Foundation models (FMs) are one of the most exciting recent developments in AI. The most interesting thing about these models is their ability to learn in-context (ICL): an FM is able to perform a broad range of tasks from data wrangling to sentiment classification without any additional model training. ICL changes the feel of how we interact with AI systems. The user adds more examples and refines the description, allowing for iteration and rapid improvement of quality. While ICL is versatile, there is a consistent quality gap1 with fine-tuning. We wondered: why?
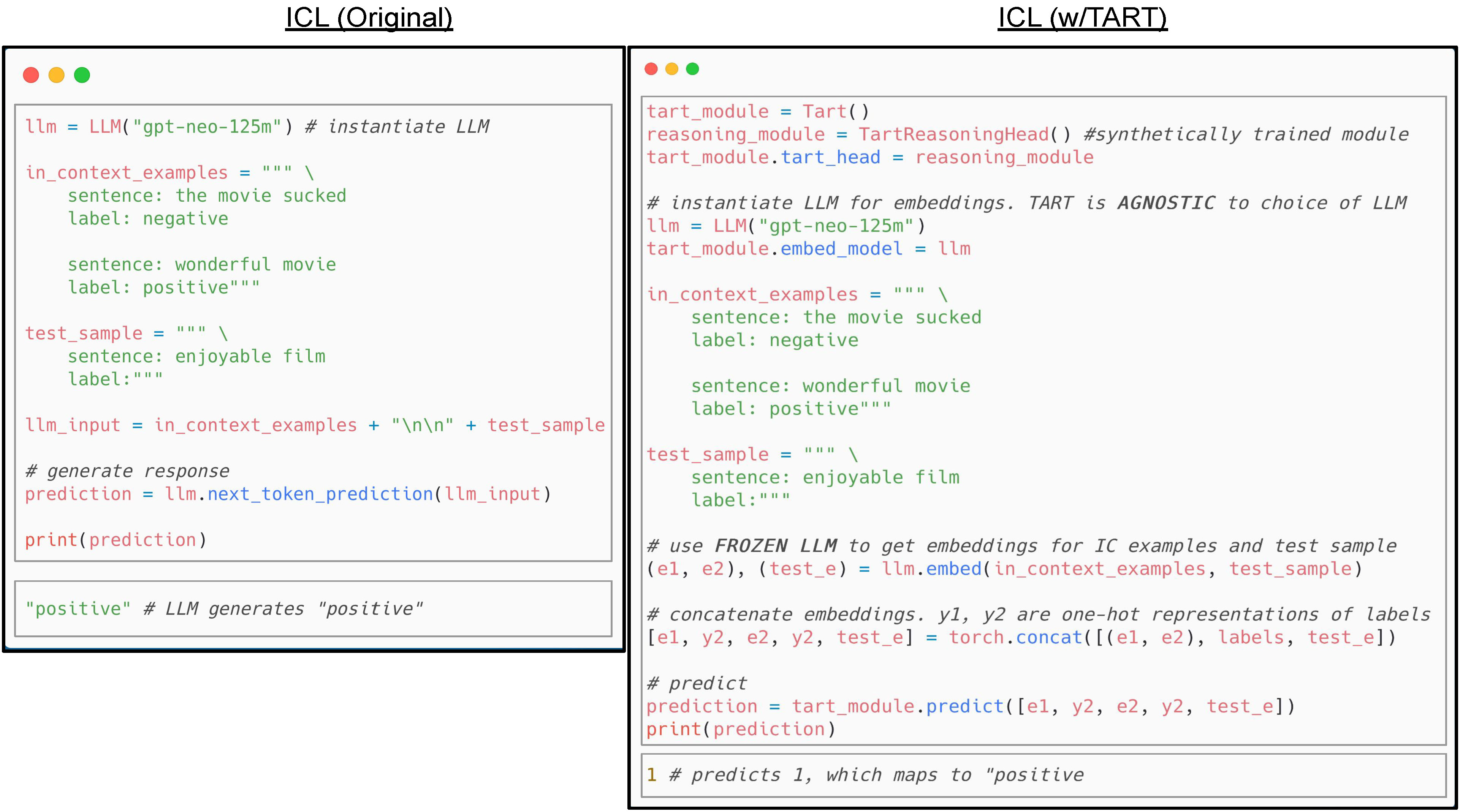
Figure 1: ICL with Task Agnostic Reasoning Transformers (TART). In this toy example, we're classifying "enjoyable film" as positive or negative sentiment. ICL is amazing because the foundation model just needs a few examples to infer that we're doing sentiment classification, and what the label means — without being explicitly trained to do sentiment classification. In TART, the same flow is given. Notice the reasoning module (reasoning_module) does not depend on the particular task or the underlying LLM. As a result, you can use the same Tart head across many tasks, models, and even modalities! We'll describe how we trained TART, and how we got to this idea.
Roughly, fine-tuning improves a model by adding new information into the representations and showing the model how to reason in a task-specific way. However, large language models (LLMs) are large — even smaller models are trained on trillions of tokens — so how do a few dozen examples change their representation? More precisely, we trained a classifier over the frozen representations using the same examples and found that it outperformed ICL by 15.8% (see paper). This suggests that the data and the features required to perform the task are indeed present in the model—perhaps it’s the reasoning with those examples that is the source of the gap?
We then had a thought: what if we could teach the models to reason in a way that didn’t depend on the specific task? Logic and probability theory have axiomatized reasoning for centuries independently of any task. Maybe these models just need to read their Aristotle? So our idea was to teach each model the abstract, general problem of probabilistic reasoning2. To do this, we simply fed the foundation model random instances of Gaussian logistic regression problem (random weights, random features) with the hypothesis that it would teach the model to improve basic reasoning (see Figure 3 (left)). As is well known, logistic regression is a simple form of message passing–a pretty general probabilistic inference and reasoning technique. It’s worth noting that this is not what traditional fine-tuning does — fine-tuning gives the model more data about the specific task at hand. In contrast, in this approach, the training data is completely independent of the specific task. Nevertheless, the models improved! We showed that these LLMs, fine-tuned on synthetic logistic regression tasks, showed improved ICL performance by up to 19%. This suggested to us that probabilistic reasoning ability is lacking in modern FMs and a key source of the ICL gap. So, many models are not learning these abstract reasoning concepts automatically from text?
Figure 2: Brain transplants for FMs!
We then went one step further: if the model is fed task-agnostic data, do we really need to train every model to reason individually? Here is an odd idea: can we train one transformer stack that only knows how to reason and transplant this to different models? Although biomimetic arguments are always dangerous, we imagine this like a cartoon version of a cortex of the brain that we could transfer to new models (see Figure 2). That is, can we train this cortex-like module and have it transplanted to different models? Seems weird but fun: This would be interesting because it would suggest that this capability was somehow uniformly lacking from many modern FMs — and in the same way! We called this new cortex-like-model TART for Task-Agnostic Reasoning Transformer. Surprisingly, on NL binary classification tasks it closed the gap between ICL and fine-tuning to 3%. And, TART transferred in a pretty surprising way: not only across language models of different sizes (100M - 7B), but even different model families (GPT-Neo, BLOOM and Pythia) — and shockingly to us, even across different modalities like audio and image (see Figure 4)! When applied to other modalities, TART performs within 1% of full model fine-tuning performance on image tasks and 3.7% on audio tasks. For more details on using TART, see “How do we use TART?” section below!

Figure 3: TART reasoning module training procedure: The reasoning module is trained on sequences of synthetically generated logistic regression tasks. Notice that this task is agnostic to any downstream evaluations (e.g., natural language text classification, image classification etc.)
We also demonstrated how to close a few practical gaps like the context length restrictions accommodating 10X more examples than in-context learning. As a result of TART’s architecture, we can model each example as two tokens (one each for the feature x and label y) as opposed to standard ICL where each example spans 100s of tokens.
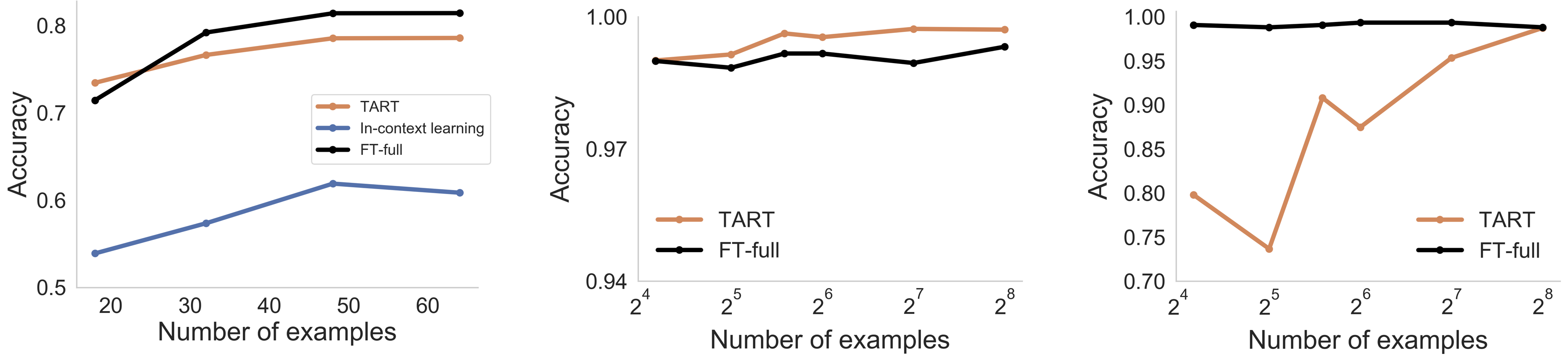
Figure 4: Fine-tuning vs. ICL vs. TART Performance. (Left) Average accuracy over NLP classification tasks on BLOOM-560M. (Middle) Accuracy over MNIST on ViT-large. (Right) Accuracy over Speech Commands on Whisper-large.
We are really excited about this result because of the new directions TART suggests:
- We can close the gap. The quality gap between in-context learning and fine-tuning may be smaller than we thought. Fundamentally, this may suggest a way to improve foundation model pretraining to make them better reasoners. The transfer across model families and modalities suggests that this “reasoning gap” is fairly widespread.
- ICL for more (even mixed) modalities is possible. The transfer over modalities suggests reasoning across text, images, and maybe even video in an in-context manner is feasible!
- Personalization at inference-time. TART demonstrates that inference is powerful enough to personalize models. We can imagine new optimizations for model serving and fine-tuning based on inference in this setting. It removes the long cycle times to fine-tune many large models and suggests that personalization can be done on your laptop alone!
We're genuinely excited about the direction of reasoning over these models and more test-time computation. This is an exciting space and we’re inspired by works (amongst many others) from Zhang et al., Sun et al., Huang et al., Garg et al., Xie et al., Ramos et al., and Bai et al.
This work is meant to be art that stimulates some fun discussion. We hope you enjoy playing with it as much as we enjoyed doing it. Please see the TART GitHub repository for notebooks, code, and training information and our paper for more details! We encourage users to try TART on more datasets, modalities and tasks! HAVE FUN!
Additional Resources
- How do we use TART? Checkout out this notebook for more details.
- How do we train the TART Reasoning Module? Checkout out this notebook for more details.
Acknowledgements
We thank Ines Chami, Karan Goel, Mayee Chen, Michael Poli, Arjun Desai, Khaled Saab, and Michael Zhang for all their feedback on this post!
- often up to 20% when evaluated on natural language binary classification tasks↩
- In the olden times of machine learning, we had a more fluid separation between inference and learning, e.g., in graphical models. Probabilistic reasoning here can be viewed as estimating the latent parameter (the weight theta) and then using theta and the features to estimate the class of the test example. Today, people often think that the only way to learn the model is to run SGD (and indeed this was one source of confusion!) but it’s possible to estimate these parameters through many different algorithms.↩