Jan 13, 2023 · 9 min read
Data Wrangling with Foundation Models
Avanika Narayan, Ines Chami, Laurel Orr, and Chris Ré.
Introduction
In recent months, generative foundation models (FMs) (e.g., GPT-3, StableDiffusion) have taken the world by storm. Text-based models have excelled on SAT and IQ exams, image-based models have been used in the creation of book covers and album art, and dialogue assistants have proven effective in explaining and fixing code bugs. With special focus on unstructured data domains (e.g., images and text), numerous startups have built real-world applications including advertisement copy generation (Jasper), code generation (Github Copilot), and conversational agents (ChatGPT). All the success of FMs for unstructured applications has yet to be realized for structured data—e.g. tabular data or knowledge graphs. Structured data, a critical resource for powering businesses, has been largely overlooked despite comprising 20% of all data!
Structured data tasks involve transforming raw data into usable data via cleaning, matching, deduplication and enrichment — a process called data wrangling. These tasks are critical in enabling any organization to function efficiently. Earlier this year, we took a leap and began studying the application of FMs to structured data tasks such as cleaning and integration — we were the first folks to do so. At the time, this idea was controversial. The common wisdom was that AI models needed to be carefully fine-tuned on structured data to adapt to those tasks. The idea that a large language model, with no emphasis on structured data and trained only on unstructured natural language data like Wikipedia, Reddit, and Twitter, could perform these tasks without additional tuning seemed absurd.
In May, we published our work (SIGMOD 2022 Keynote, ArXiv), which will appear in VLDB 2023, demonstrating that large language FMs can be used out-of-the-box to achieve SoTA performance on structured data tasks. Since then, we have focused on building a community that is excited by the idea of using FMs for structured data tasks. Following the release of our work, we have seen FMs being used for a number of structured data tasks:
- Tabular data prediction
- Parameter efficient prompt tuning for data wrangling tasks
- Production ready modern data stack workflows
- Natural language querying over data lakes
- Code generation for data wrangling and EDA tasks
- and much more!
These efforts are just the beginning, and we expect to see much more exciting work in the future applying FMs to structured data settings.
Energized by the rising interest in applying FMs to structured data, we pushed to make structured data tasks core elements of FM benchmarks. We started by adding cleaning and integration tasks to Holistic Evaluation of Language Models (HELM): a benchmark aimed at increasing the transparency of open and closed-source language models. This is only the first step. We encourage the community to jump in and build better models and methods that push the state-of-the-art of FMs on these tasks.
In the remainder of this blog post, we describe our work in applying language FMs to structured data tasks.
Background
Language FMs (e.g., GPT-3, OPT) have a unifying interface taking a textual prompt as input and generating text as output. Excitingly, at a large enough scale (e.g., billions of parameters), these models have demonstrated the ability to transfer to new tasks given a simple textual description of the task (e.g., “translate the following text from French to English”) and/or a few examples of the task (e.g., “Bonjour → Hello”). This property is called in-context learning and enables FMs to transfer to new tasks in the absence of any task-specific finetuning. As a result of this task-less property, non-ML practitioners can apply FMs to their respective tasks by simply designing and tuning natural language prompts, without having to write any code or train models. In the context of data management practices, this no-code property allows for the construction of systems and data pipelines that are more accessible to non-machine learning or data experts (e.g., business users).
Our research explores the applicability of FMs to five enterprise data integration and cleaning tasks which constitute complex data pipelines:
- Schema matching: finding semantic correspondences between elements of two schemas
- Entity matching: identifying similar records across different structured sources
- Error detection: detecting erroneous entries in table
- Data imputation: filling missing entries in a table
- Data transformation: converting data from one format to another
Existing ML-driven data pipelines require a significant amount of engineering effort as they rely on task-specific architectures for individual tasks, hard-coded knowledge and labeled data. Excitingly, FMs display several appealing properties that directly counteract these limitations. Concretely, they have a task-agnostic architecture (text in and text out), contain a lot of encoded knowledge from their training data, and can transfer to new tasks with limited labeled data due to in-context learning.
Approach
To use a FM for structured tabular data tasks, we have to address two main technical questions. First, how do we feed tabular data to these models that are trained and designed for unstructured text? And second, how do we cast the data tasks as natural language generation tasks? In other words, how do we craft good prompts that allow FMs to work on structured data tasks?
To answer the first question, we first need to convert structured tabular data inputs to text representations. Concretely, for a table with column names attr1, …, attrm and for a table entry with values val1, …, valm, we serialize the data as a string representation as follows:
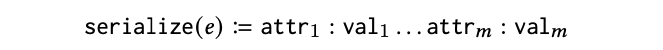
To answer the second question, we proposed to cast a variety of structured data tasks as generation tasks. Concretely, we construct natural language question answering templates for each task. For instance, the template for a product entity matching task is:

In our paper, we introduce prompt templates for other data wrangling tasks such as data imputation, error detection, schema matching and data transformation. At inference time, we complete the above template with the serialized tabular data for each table entry. An example prompt to evaluate whether two Apple MacBook products are the same based on their title and price attributes is shown in Figure 1. The prompt is then fed into the model which produces a yes/no answer that is used as the final result.
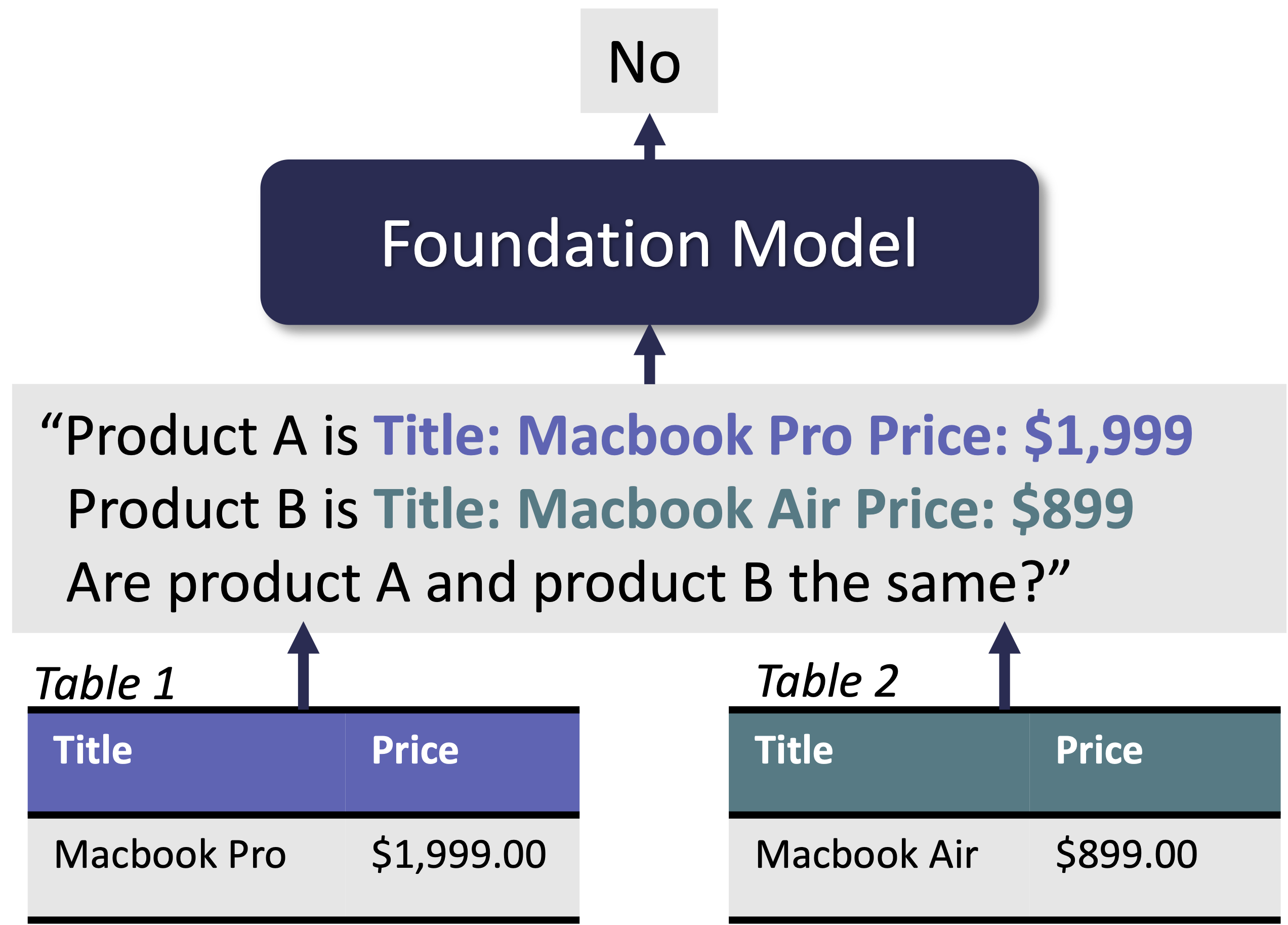
Figure 1. A large FM can address an entity matching task using prompting. Rows are serialized into text and passed to the FM with the question "Are products A and B the same?". The FM then generates a string "Yes" or "No" as the answer.
The above figure illustrates how to use FMs in a zero-shot setting, i.e., no demonstrations are provided to the model. It is also possible to improve the performance of FMs using few-shot demonstrations, i.e., by including a few examples for desired input/output pairs in the prompt template (see Figure 2).
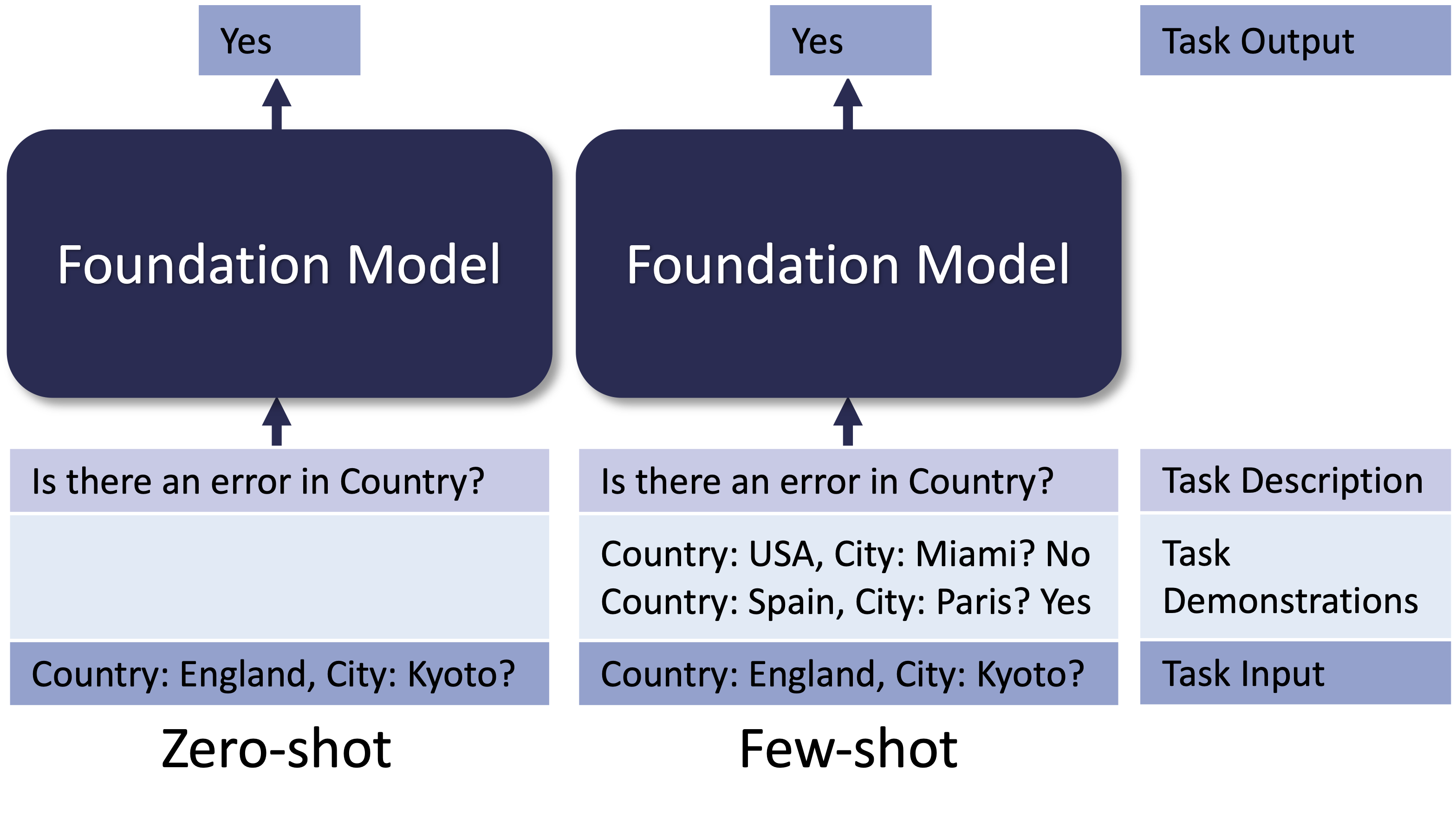
Figure 2. Different ways to use FMs with "in-context" learning on an error detection task. For zero-shot (left), the prompt is the task description and the example to complete. For few-shot (right), the prompt adds demonstrations of how to complete the task.
Results
We evaluated the out-of-the-box performance of GPT-3 on the five challenging data wrangling tasks previously discussed: entity matching, error detection, schema matching, data transformation, and data imputation. We found that even with no demonstrations, these models achieve reasonable quality on multiple challenging data wrangling benchmarks. Additionally, with only 10 manually chosen demonstrations, GPT-3 was able to match or outperform the existing state-of-the-art ML-based methods on 11 out of 14 benchmark datasets. Unlike prior approaches, our method uses a single model for all tasks, requires limited amounts of labeled data, and doesn’t need hard-coded knowledge to complete the evaluation tasks.
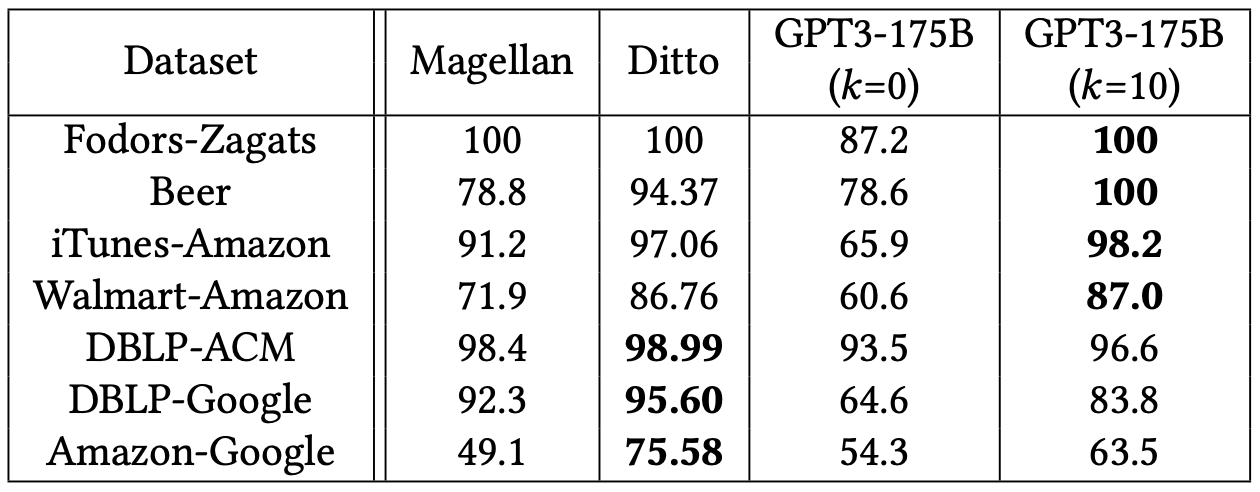
Table 1. Entity matching results measured by F1 score where k is the number of task demonstrations.
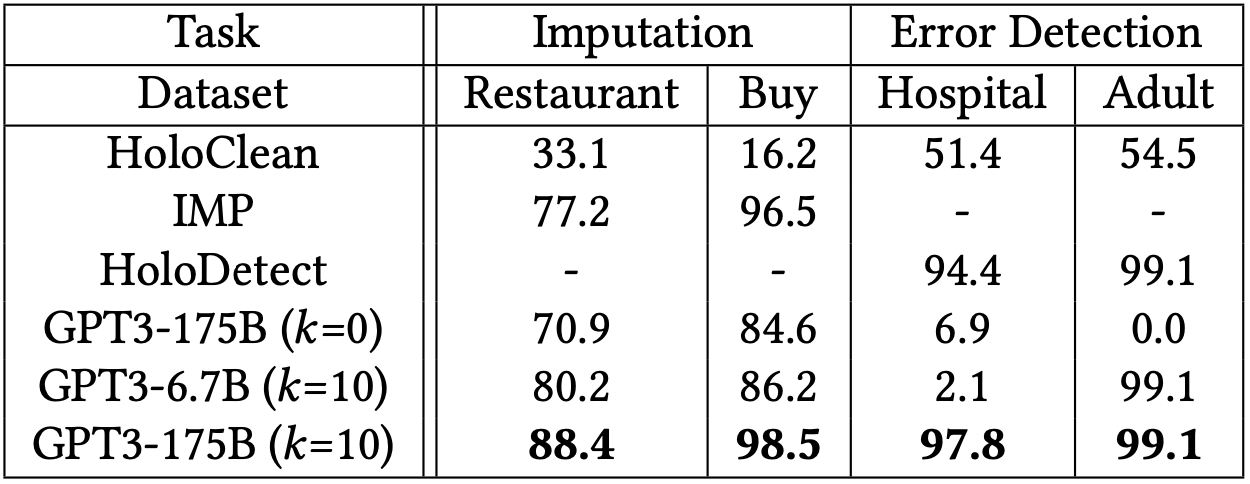
Table 2. Data cleaning results, measured in accuracy for data imputation and F1 score for error detection where k is the number of task demonstrations.

Table 3. Data integration results, measured in accuracy for data transformations and F1 score for schema matching. Previous SoTA method is TDE for data transformation and SMAT for schema matching.
Discussion
These results demonstrate that a single FM can be applied out-of-the-box to a wide-range of data wrangling tasks! This work is a preliminary exploration and we couldn't be more eager about the direction of applying FMs to structured data tasks. While we’ve shown exciting results, there is still much to do. Below we enumerate a few challenges towards this end.
-
Model Size: We find an unsatisfying trade-off between model size and performance. Concretely, we observe that smaller models (<10B parameters) perform worse than larger models (>100B parameters) out-of-the-box, and require some amount of task-specific fine-tuning to perform competitively with larger models. However, the larger models are costly to run resulting in concerns around scalability. We believe we can make advances to get the best of both worlds— in recent work we show how to improve effectiveness of smaller models via new prompting strategies.
-
Prompt Brittleness: We find that the prompting regime can be quite brittle. Concretely, performance fluctuates based on prompt formats and choice of in-context examples. As seen in Table 4, we find that prompt formatting (i.e., word choice, punctuation) can have a significant impact on model performance. and that examples need to be carefully crafted for FMs to learn new tasks. In an effort to reduce brittleness in the prompting process, we have developed Manifest, a toolkit for prompt programming, which seeks to systematize prompt engineering workloads.
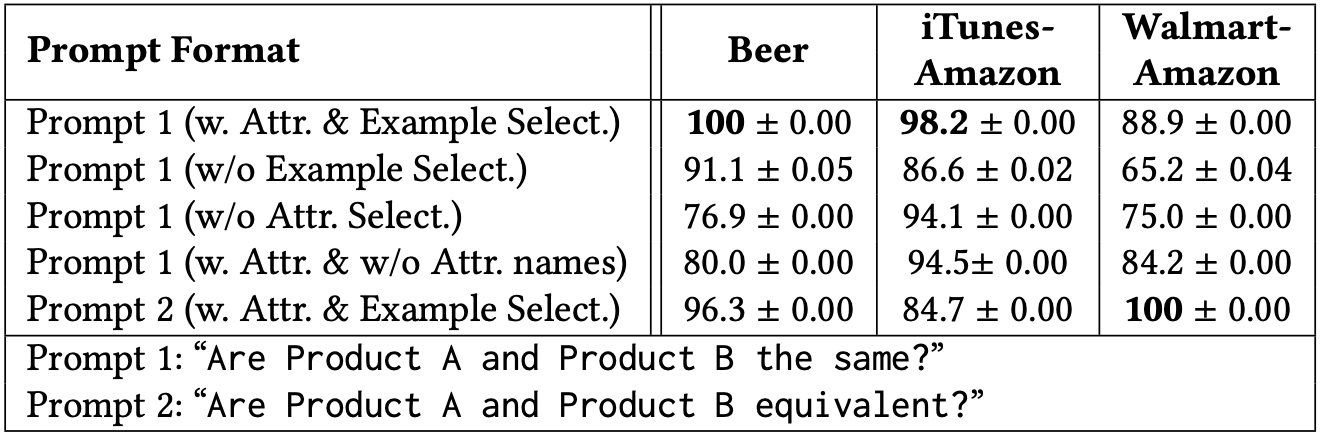
Table 4. Entity matching ablation results (F1 score) for different prompt formats k=10. For all datasets, we evaluate on up to 200 samples for cost purposes.
What's Next
Our work builds upon years of past efforts towards data wrangling pipelines and is a first step towards realizing the application of FMs to these data wrangling tasks. We want this excitement to lead to a community-wide effort to understand how these models can be used to solve traditional and new structured data problems
We hope that our prompting approach can solve people’s own structured data problems. We make it easy for folks to try out our prompts with our open-source code repository. We encourage users to try out our prompts, share what they tried with us, and contribute new tasks via pull requests. If you have other use cases where our methods could be helpful, please reach out to let us know!
Avanika Narayan: avanikan@stanford.edu