Oct 13, 2022 · 4 min read
Fast Stable Diffusion with FlashAttention + Diffusers
We sped up Stable Diffusion in the Diffusers library by adding FlashAttention - improving throughput by up to 4x over an unoptimized version of diffusers. On a single A100, we can now generate high-quality images with 50 denoising steps faster than 1 image/second. You can see the diff (68 lines) here, and find install instructions here.
We’re really excited about where else we can see speedup with FlashAttention, and what folks might be able to do with a faster Stable Diffusion. Would love to hear about more exciting use cases like this!
Some notes on FlashAttention, our integration, and how we benchmarked it below.
FlashAttention
We built FlashAttention to speed up the core attention computation, by aiming to minimize the number of memory reads and writes. FlashAttention is an algorithm for attention that runs fast and saves memory - without any approximation. FlashAttention speeds up BERT/GPT-2 by up to 3x and allows training with long context (up to 16k).
We're super excited and humbled by the adoption we've seen in just four months: integrations in PyTorch (nn.Transformer), HuggingFace, Mosaic ML's Composer, and Meta's fast inference engine. We've also seen a number of reimplementations, from the xformers team at Meta, to OpenAI Triton, and Jax (side note - this is one of our favorite things about the ML community)!
The key insight in FlashAttention is that on modern GPUs such as A100, the tensor cores are so fast that attention ends up being bottlenecked by reading and writing from GPU memory.
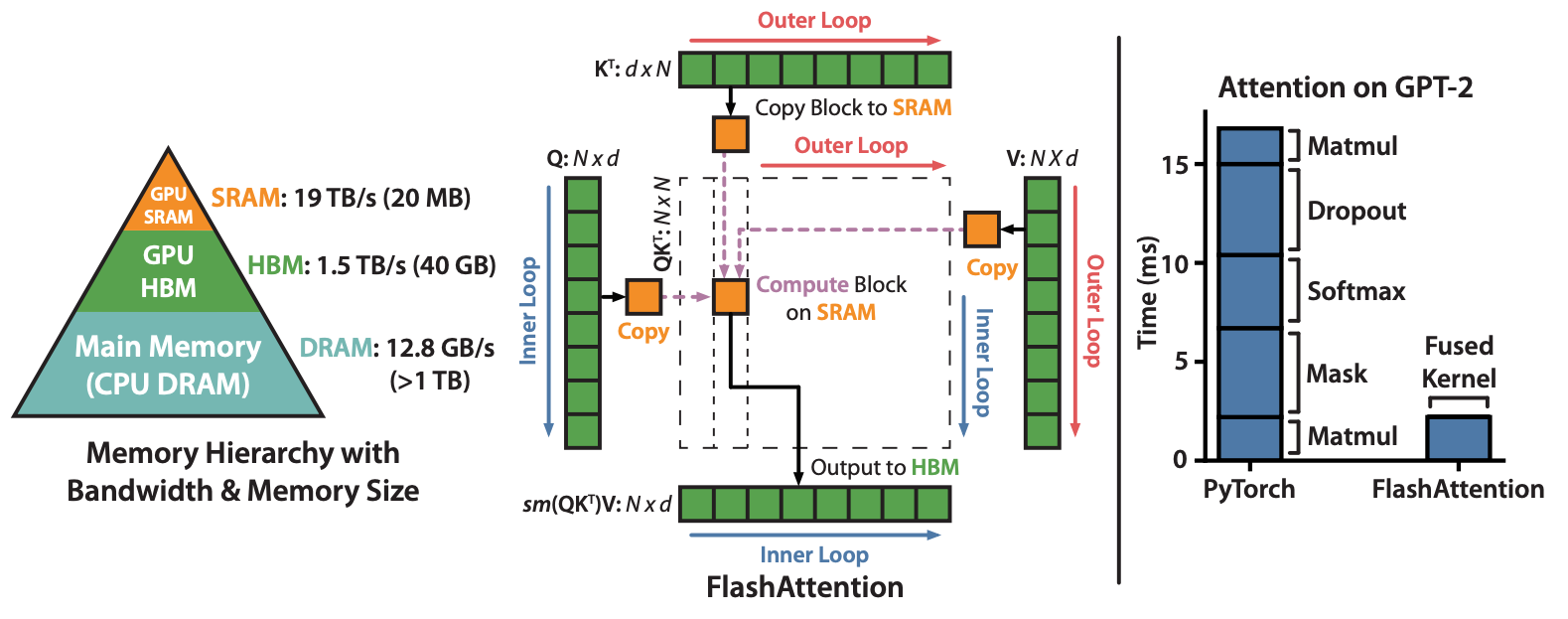
FlashAttention speeds up attention by reducing the GPU memory reads and writes.
FlashAttention fuses the matmuls and softmax of the attention computation into one kernel:
softmax(Q @ K.T) @ V
Tiling (h/t Rabe & Staats) helps us achieve this goal by reducing the total amount of memory we need to compute attention at one time. Our CUDA kernels give us the fine-grained control we need to ensure that we aren’t doing unnecessary memory reads and writes.
Diffusers Integration
Now onto the integration with HuggingFace Diffusers. We’ll admit, we’re a bit late to the game on this one - we were inspired by folks on Reddit and elsewhere who have already spun up their own FlashAttention integrations, so we decided to throw our hats in the ring as well.
Our integration is pretty simple – less than 70 lines of code. You can see the implementation details in the diff, or try it out for yourself.
Diffusers + FlashAttention gets the same result as the original Diffusers – here’s the output with the same seed for the prompt “a photo of an astronaut riding a horse on mars”:


Left: Output from Diffusers. Right: Output from Diffusers + FlashAttention.
Benchmarking Diffusers + FlashAttention
We benchmarked Diffusers + FlashAttention against the original CompVis Stable Diffusion code, as well as various optimized/unoptimized versions of Diffusers (h/t @Nouamanetazi). We added FlashAttention to Nouamane's half precision code as a starting point. You can find our benchmarking code on GitHub (also following Nouamane's benchmarking scripts).
The upshot: we see 3-4x speedup over unoptimized versions of Stable Diffusion, and 33% speedup over the super optimized version of Stable Diffusion in Diffusers 0.4.1.
On A100, we get throughput up to 1.04 images/s – almost 3x faster than unoptimized versions of Diffusers or CompVis! We also end up 33% faster than Diffusers version 0.4.1 (see this Tweet thread).
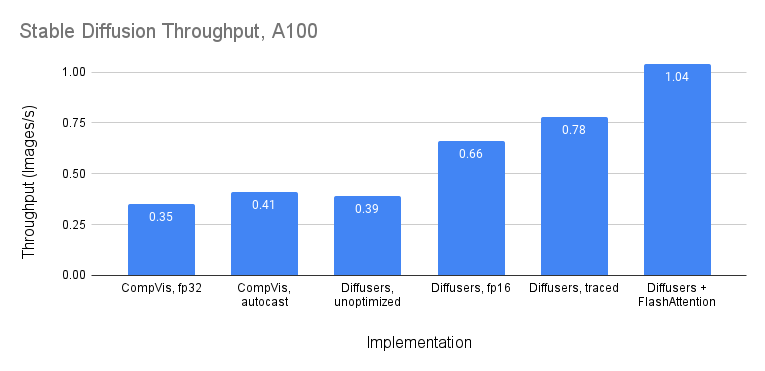
Throughput on A100. Diffusers + FlashAttention gets up to 1.04 images/s.
On T4, where the memory system is slower, the speedup over the unoptimized versions is even larger: >4x speedup over unoptimized versions of CompVis.
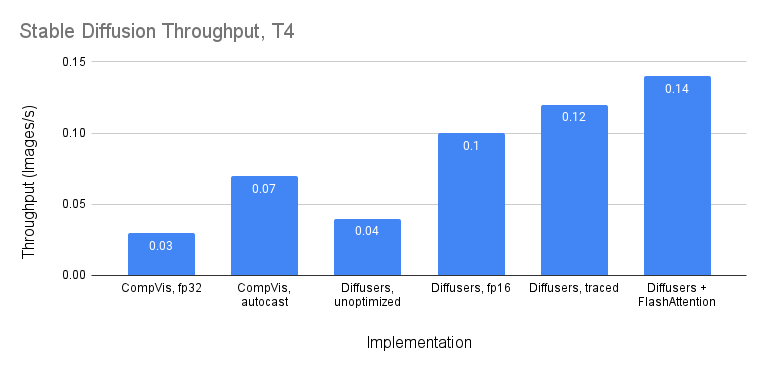
Throughput on A100. Diffusers + FlashAttention gets 4x speedup over CompVis Stable Diffusion.
An extra plus here for throughput – FlashAttention reduces the memory footprint, so you can run with much larger batch sizes. On A100, we can generate up to 30 images at once (compared to 10 out of the box). Really excited about what this means for the interfaces people build with this!
Try it Yourself
If you’re excited about this stuff, check out our branch of Diffusers on GitHub, and check out FlashAttention. If you have other use cases where our stuff could be helpful, please reach out to let us know!
Dan Fu: danfu@cs.stanford.edu; Tri Dao: trid@stanford.edu