Apr 14, 2020 · 18 min read
Ivy: Instrumental Variable Synthesis for Causal Inference
Charles Kuang, Frederic Sala, Nimit Sohoni, James Priest, and Christopher Ré
In science and medicine, randomized controlled experiments (RCEs) are a reliable way to measure cause-and-effect relationships. It’s not always practical to conduct RCEs due to cost, time, ethics and other concerns, and a popular alternative is to use instrumental variables (IVs), variables in observational data that resemble the behavior of RCEs. In practice, perfect IVs are hard to find, and practitioners sometimes heuristically combine a set of imperfect IVs in the hope of synthesizing an IV of better quality. In this post, we build on these approaches and explore how and under what conditions we might be able to synthesize an IV of higher quality by making use of imperfect IVs more effectively compared to existing heuristics.
TL;DR: In science and medicine, randomized controlled experiments (RCEs) are a reliable way to measure cause-and-effect relationships. It’s not always practical to conduct RCEs due to cost, time, ethics and other concerns. A popular alternative is to use instrumental variables (IVs), variables in observational data that resemble the behavior of RCEs. In practice, perfect IVs are hard to find, and practitioners sometimes heuristically combine a set of imperfect IVs in the hope of synthesizing an IV of better quality. In this post, we build on these approaches and explore how and under what conditions we might be able to synthesize an IV of higher quality by making use of imperfect IVs more effectively compared to existing heuristics.
Introduction
Traditionally, statistics is great for figuring out correlations between variables—but not necessarily their causal relationships! To illustrate this idea, we’ll use a running example where we consider finding the causes of heart attacks.
Example: Does Smoking Cause Heart Attacks? It’s easy to observe that there is a positive correlation between smoking and heart attacks. Intuitively, we speculate that smoking causes heart attacks (and not the other way around!), but we can’t directly infer this from the correlation measure, as it does not provide any causal information.

Source: https://www.healthy-heart-guide.com/wp-content/uploads/2015/04/smoking-and-heart-disease.jpeg
{kind=link}
To figure out the causal relationship between smoking and heart attacks, one reliable approach is to conduct a randomized controlled experiment (RCE): randomly assign half of the population to the exposure group which is forced to smoke, and the other half to the control group which is forbidden from smoking. In the end, we compare the occurrence rate of heart attacks between the two groups. But such an experiment---where we have to force people to smoke---is extremely unethical!
Causal Inference How can we circumvent experiments in cases like these? Enter causal inference, the study of causes and effects. One of the main goals in this field is to estimate the causal effect between a pair of variables from observational (non-experimental) data. The potential cause (smoking, in this example) is called a risk factor, and the variable on which we are trying to measure the effect (heart attack) is called the outcome.
Why are causal effects challenging to estimate? If we only get to work with observational data, the causal relationship can end up being obscured by confounders, variables that directly influence both the risk factor and the outcome. For instance, high stress levels can act as a confounder that both increases a person’s likelihood of smoking and the person’s chance of getting a heart attack. Even more challenging is that confounders can be unmeasured! For example, it is difficult to reliably quantify and measure every aspect of a person’s stress levels in the data.
There are many schools of causal inference that provide solutions to causal effect estimation. In this post, we focus on the setting where we have access to instrumental variables (IVs). At the end of this post we give a brief overview of various causal inference methods including IV methods.
Our Setting We consider the scenario where we have access to instrumental variables (IVs)— variables from observational data that fluctuate independently of confounders, and influence the outcome only through the risk factor. Intuitively, IVs are akin to RCEs conducted by nature and hence have the potential to provide reliable causal estimates.
In practice, perfect IVs are rare, and practitioners sometimes heuristically combine a set of imperfect IVs in the hope of synthesizing an IV of better quality. This synthesis problem is common in Mendelian randomization (MR), an application of IV methods in genetic epidemiology (Burgess et al., 2017). Our work builds upon the insights of MR practitioners and seeks to understand how---and when--- it is possible to synthesize an IV of higher quality.
Instrumental Variables
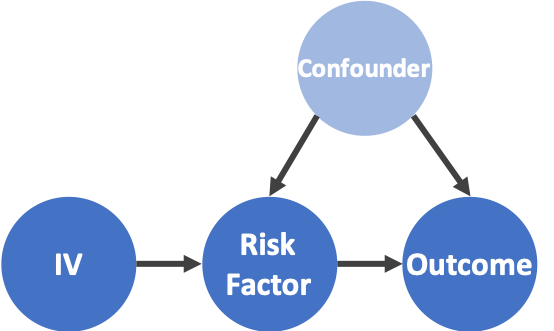
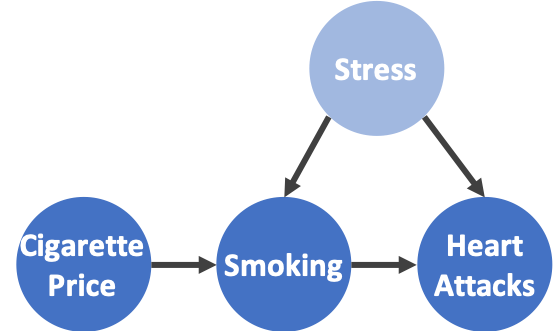
Figure 1: Estimation of causal effects using an instrumental variable. Left: a conceptual model of using an IV for causal effect estimation. Latent variables are shaded. Right: estimate the causal effect of smoking on heart attacks with cigarette price as an IV.
The notion of instrumental variables (IVs) dates back to the 1920s (Wright, 1928). Specifically, an IV can be described as a variable that is independent of the confounders and influences the outcome only through the risk factor. See Figure 1 for an illustration of how an IV, a risk factor, an outcome, and a confounder relate to each other.

Source: https://tobaccobusiness.com/wp-content/uploads/2018/06/new-york-city-cigarette-pricesfc.jpg
{kind=link}
In the smoking-heart attack example, a possible IV is the price of cigarettes (Figure 1). It is easy to see that cigarette price meets the definition of an IV: it is independent of confounders such as stress level, and it only influences the occurrence of heart attacks by influencing the demand for cigarettes (smoking rate). As a result, by quantifying how much a change in smoking rate due to the cigarette price change affects the occurrence rate of heart attacks, we can provide an estimate of the causal effect of smoking on heart attacks. We can view the IV as a proxy to an experiment when computing the correlation, specifically because an IV is not affected by confounders by definition.
How do we use these IVs? There are many IV-based causal effect estimators which we can plug the IVs into. One choice is the Wald estimator (Burgess and Thompson, 2015). The idea behind the Wald estimator is to compute a correlation between the IV and the outcome—which is an estimate of the causal effect since that is how we picked the IV—and then to normalize it by the correlation between the IV and the risk factor.
IVs Seem Great! Why Not Use Them More Often?
A perfect IV is usually difficult to find—It can take a lot of intuition and expertise to figure out if a measured variable has the properties of an IV. Fortunately, imperfect IVs are common in many real-world applications. These are variables with varying (potentially lower) quality compared to a perfect IV. They may be only weakly associated with the risk factor. Even more challenging among the imperfect IVs are the invalid IVs—variables that don’t satisfy all of the properties of an IV. We don’t know the validity of these imperfect IVs beforehand. Furthermore, these imperfect IVs can be statistically dependent on each other. This means that naively combing imperfect IVs without quality control may lead to unreliable causal estimates.
Ivy to the Rescue!
To understand how well we can make use of the more commonly available imperfect IVs, we explore how and when to synthesize an IV of better quality from a set of imperfect IVs. After synthesis, we can plug the resulting variable into existing IV methods for causal inference.

We call our procedure Ivy. The idea behind Ivy is to view the desired IV that we seek to synthesize as a latent variable. We assume that among all the imperfect IVs, there is a subset of valid IVs that can be viewed as noisy realizations of this latent variable. We infer the value of the latent variable based on these noisy realizations. We can separate valid from invalid IVs as long as the latter are independent of the valid synthesized IV. Below we show the relationships among a synthesized IV (z), imperfect IVs (, ..., ), risk factor (x), outcome (y), and confounder (c).
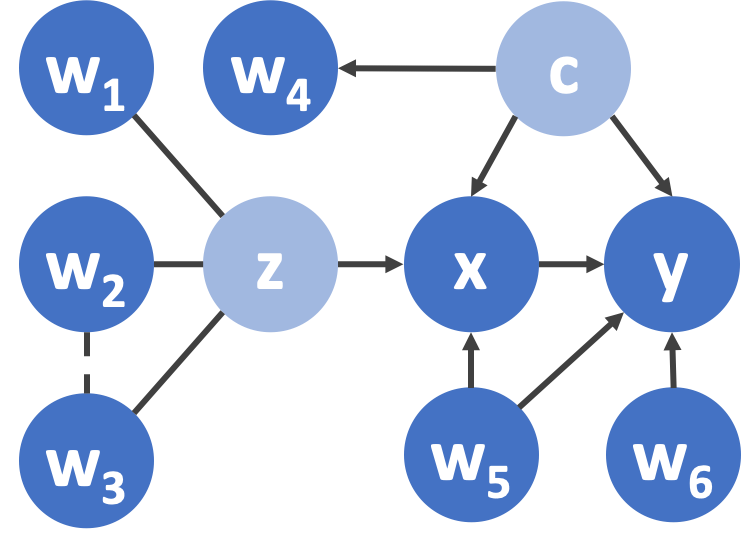
Figure 2. Using Ivy to synthesize an IV (z) for causal effect estimation. - are imperfect IVs. Ivy infers that - are valid IVs while - are invalid IVs. Meanwhile, Ivy infers the dependency between and . x: risk factor; y: outcome; c: confounder.
How Does Ivy Work? It starts with a set of imperfect IVs (- in Figure 2) as input, and synthesize an IV (z in Figure 2) as output that can be used by downstream IV-based causal effect estimators. Ivy does not require us to know the dependencies (e.g. -) and validity of the imperfect IVs as input—it learns them from the data.
- Step 1 - Learning Dependencies and Validity (Synthesis Phase): Ivy applies a structure learning approach based on robust principal component analysis (Varma et al., 2019) to a graphical model in order to learn the validity of, and dependencies between, the IVs (in Figure 2, Ivy will learn that - are valid IVs and - are invalid, and that there is an edge between - in this step).
- Step 2 - Synthesize an IV (Synthesis Phase): Ivy exploits the dependencies between valid IVs given by the previous step to learn the parameter of M. It then synthesizes a valid higher-quality IV by computing the conditional probability given by (in Figure 2, Ivy will infer the value of z based on the values and edges among w1-w3 in this step).
- Step 3 - Estimate Causal Effects (Estimation Phase): the synthesized IV derived in Step 2 can be plugged into existing IV-based causal effect estimators (along with the risk factor and the outcome) to estimate causal effects (in Figure 2, the causal effect from x to y will be estimated).
Theory We harness recent advances in structure learning of graphical models with latent variables (Varma et al., 2019) to obtain theoretical results for the effectiveness of Ivy in handling dependencies and its robustness against invalid IVs. This lets us identify scenarios where Ivy can successfully synthesize a valid IV of high quality, bound its sample complexity, and characterize model misspecification due to invalid IVs and missed dependencies. Furthermore, we analyze the performance of the Wald estimator when the IV synthesized by Ivy is used in lieu of an observed valid IV.
Where Can We Use Ivy?
An important use case of Ivy is in an area of genetic epidemiology called Mendelian randomization (MR). In MR, genetic markers such as single-nucleotide polymorphisms (SNPs) are used as imperfect IVs to infer causal relationships among clinical variables. One well-known example of a successful application of MR is also concerned with heart attacks as the outcome, but instead of considering smoking as the risk factor that has a positive causal effect on heart attacks, we are interested in understanding the role of high-density lipoprotein (HDL) as the risk factor, which turns out to be not causing the change in the occurrence of heart attacks:
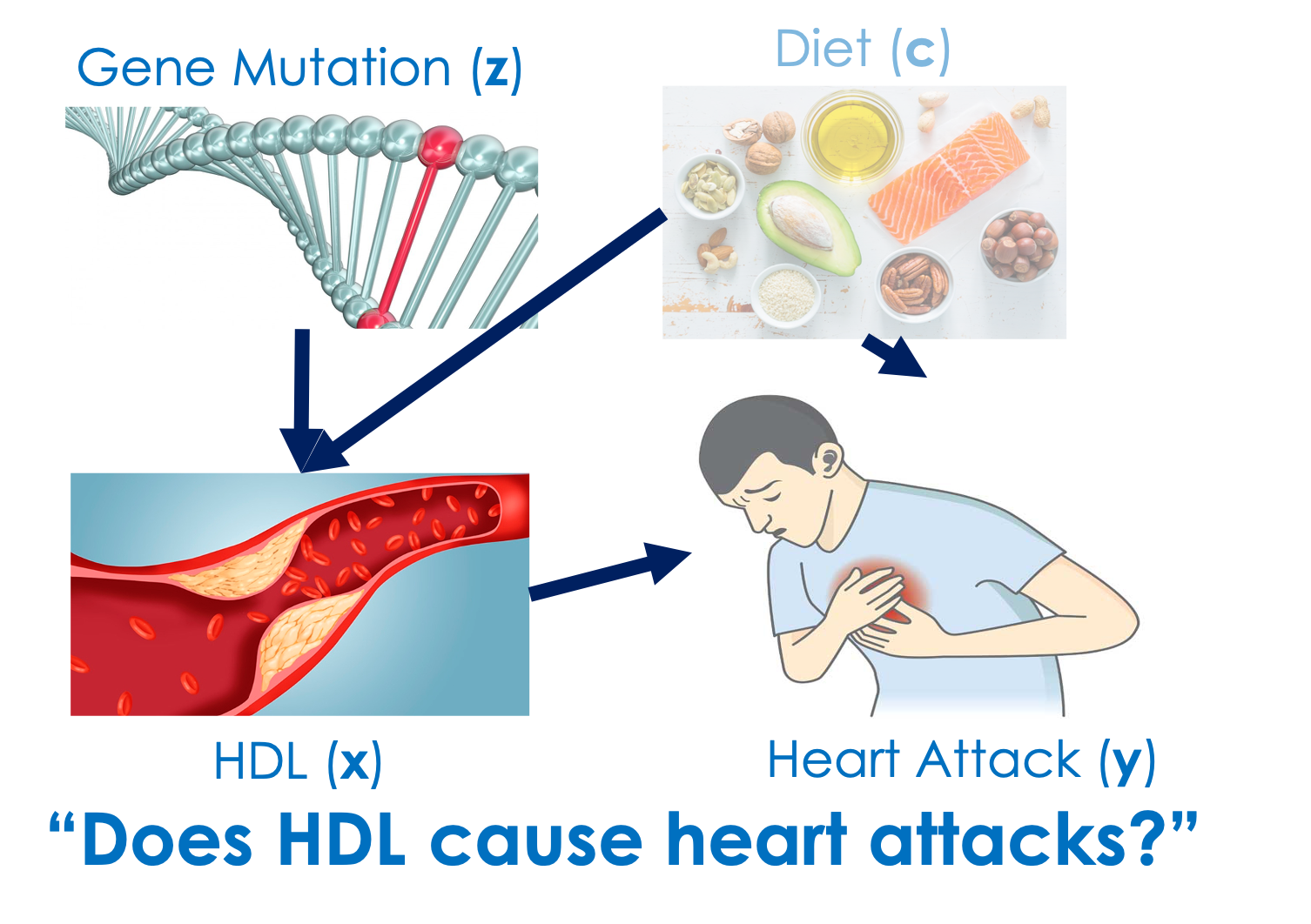
Example (continued): Can high-density lipoprotein (HDL) prevent heart attacks? From observational data, there is a negative correlation between HDL and the occurrence of heart attacks due to confounders such as other species of lipids and dietary habits. Since the negative correlation is so strong, for years HDL had been hypothesized to have a protective effect on the occurrence of heart attacks. It turns out, however, that this relationship is merely spurious. Nonetheless, billions of dollars were invested by pharmaceutical companies to develop drugs that raise HDL for the prevention of heart attacks, leading to futile clinical outcomes (Berenson, 2006). This spurious relationship was later dismissed by a series of Mendelian randomization studies (Voight et al., 2012; Holmes et al., 2014; Rader and Hovingh, 2014), which revealed that there are no preventive effects of HDL on heart attacks.
In MR, the idea of synthesizing a higher-quality IV from imperfect IVs is exemplified by the allele score methods, which are commonly used by MR practitioners. There are two commonly used variants (Burgess and Thompson, 2013):
- Unweighted allele score (UAS), which equally weights each imperfect IV to derive a synthesized IV in a majority vote fashion;
- Weighted allele score (WAS), which weights each imperfect IV based on how predictive the variable is of the risk factor. Allele scores implicitly assume that all the imperfect IVs are valid and are conditionally independent given the synthesized IV. In certain cases, Ivy weakens these assumptions: it can by identifying invalid IVs and can recover dependencies among valid IVs.
How Well Does Ivy Work in Practice?
We empirically validate Ivy in the Mendelian randomization setting. We use real-world data from the UK Biobank database (Sudlow et al., 2015) to study three biomarkers—HDL, C-reactive protein (CRP), and Vitamin D (VTD)—which have spurious effects on the occurrence of heart attacks, using SNPs as imperfect IVs whose dependencies and validity are unknown. Since we investigate spurious relationships, we expect the estimated causal effects to be close to zero if a method can effectively dismiss these relationships. We compare Ivy with UAS and WAS:
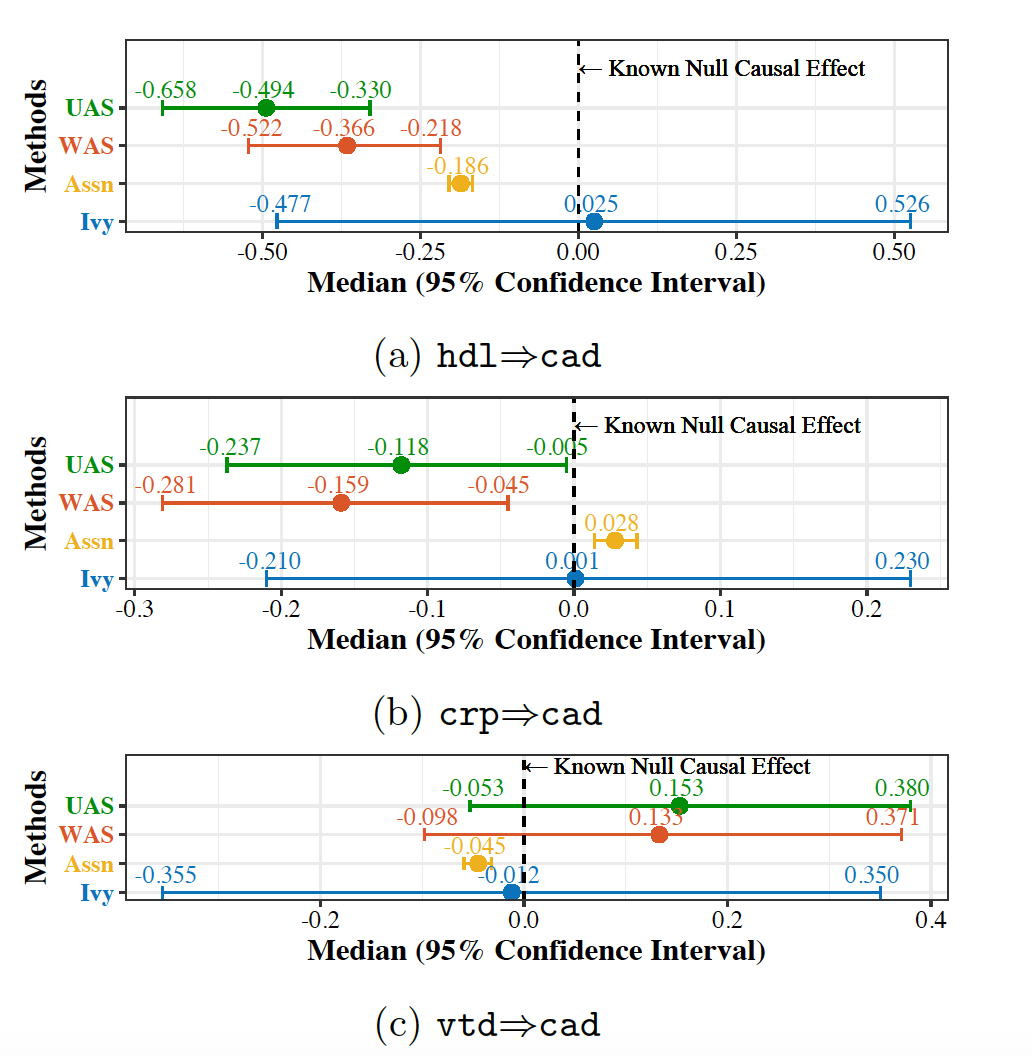
Figure 3. Dismissal of spurious correlations in Mendelian randomization by synthesizing an IV from SNPs with potential dependencies and invalidity as imperfect IVs. cad: coronary artery disease (a.k.a. heart attacks). Assn: association estimated by regressing the outcome on the risk factor. The X-axis is the causal effect estimate returned by the Wald estimator.
We see that Ivy produces the least biased causal estimate (median closest to zero) when compared to UAS and WAS, showing a practical use of Ivy in Mendelian randomization. Ivy also has a wider confidence interval since it only uses the subset of valid IVs to infer causation, instead of using all imperfect IVs without certifying their validity as do UAS and WAS.
A Word on Caution
Ivy is not a panacea! Here we show an example of failure in dismissing spurious relationships on synthetic data where there are no valid IVs in the underlying data generation process.
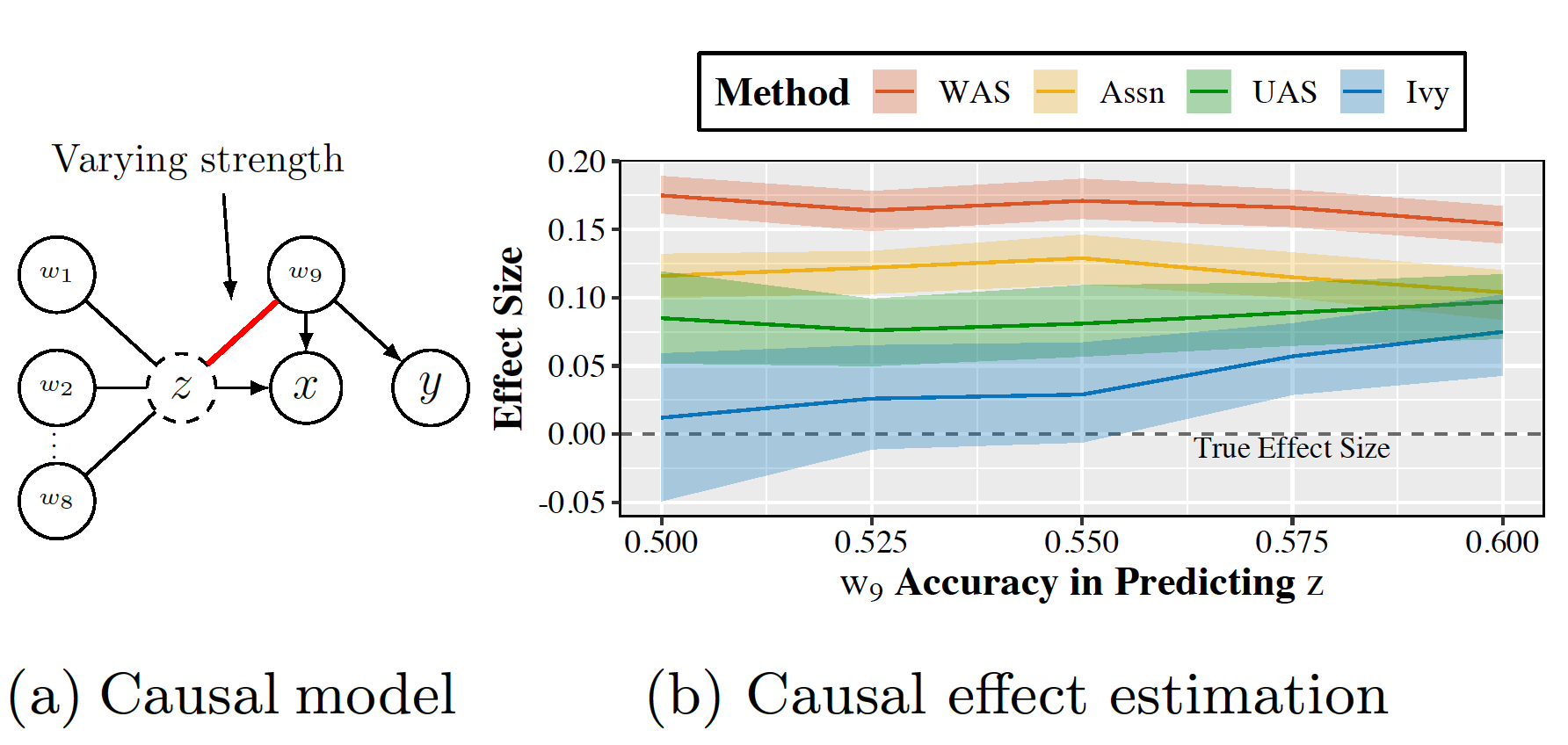
FIgure 4. Failure of Ivy. z violates the IV assumptions more severely as its association to the invalid IV gets stronger. As a result, all imperfect IVs are invalid. Ivy is more resilient to the violation compared to other methods, but eventually fails as the invalidity of z becomes significant enough.
Conclusion
We described Ivy, an instrumental variable synthesis framework that seeks to synthesize an IV of better quality for causal inference from a set of imperfect IVs that are potentially interdependent and even invalid. Ivy builds on existing approaches for IV synthesis and provides an additional way to derive IVs from imperfect IVs for causal inference. We look forward to extending the utility and applicability of Ivy to power modern IV-based causal inference methods (Hartford et al., 2017; Athey et al., 2019) with IVs of higher quality, as well as improving the expressiveness and generality of Ivy by leveraging formal causal inference frameworks such as the potential outcome framework (Imbens and Rubin, 2015) and the do-calculus (Pearl, 2009).
An Overview of Causal Inference
Causal inference is the study of causes and effects. It includes many schools of thought drawing on computer science (Pearl, 2009), economics (Angrist and Pischke, 2008), epidemiology (Hernán and Robins, 2020), social science (Morgan and Winship, 2015), and statistics (Shvarev, 2018), among others.
One of the main goals in this field is to estimate the causal effect between a pair of variables called the risk factor and the outcome from observational (non-experimental) data. This is challenging because of confounders that obscure causal relationships. To perform reliable causal effect estimation, different schools of causal inference propose various solutions that impose different assumptions: from using the potential outcome framework (Imbens and Rubin, 2015) by assuming that all the confounders are known, to using the do-calculus (Pearl, 2009) by assuming that we have access to an intermediate variable (a.k.a. mediator) in the causal path between the risk factor and the outcome, to machine learning based approaches (Schölkopf, 2019) by making assumptions on the causes (Wang and Blei, 2019), the noise (Peters et al., 2014), and the complexity of the confounders (Peters et al., 2017).
In our work, we consider the use of instrumental variables. Intuitively, IVs are akin to RCEs conducted by nature, and hence have the potential to provide reliable causal estimates. Indeed, IV methods are quintessential in fields ranging from econometrics (Angrist and Krueger, 1991), to computational advertising (Hartford et al., 2017), genetic epidemiology (Burgess and Thompson, 2015), biomedical science (Millwood et al., 2019), and pharmacology (Walker et al., 2017).
Reference
Angrist, J. D., & Krueger, A. B. (1991) Does compulsory school attendance affect schooling and earnings? The Quarterly Journal of Economics, 106(4).
Angrist, J. D., & Pischke, J. S. (2008). Mostly harmless econometrics: An empiricist's companion. Princeton university press.
Athey, S., Tibshirani, J., & Wager, S. (2019). Generalized random forests. The Annals of Statistics, 47(2), 1148-1178.
Berenson, Alex. (2006). Pfizer Ends Studies on Drug for Heart Disease. The New York Times.
Burgess, S., & Thompson, S. G. (2013). Use of allele scores as instrumental variables for Mendelian randomization. International journal of epidemiology, 42(4), 1134-1144.
Burgess, S., & Thompson, S. G. (2015). Mendelian randomization: methods for using genetic variants in causal estimation. Chapman and Hall/CRC.
Burgess, S., Small, D. S., & Thompson, S. G. (2017). A review of instrumental variable estimators for Mendelian randomization. Statistical methods in medical research, 26(5), 2333-2355.
Hartford, J., Lewis, G., Leyton-Brown, K., & Taddy, M. (2017, August). Deep IV: A flexible approach for counterfactual prediction. In Proceedings of the 34th International Conference on Machine Learning-Volume 70 (pp. 1414-1423). JMLR. org.
Hernán MA, Robins JM (2020). Causal Inference: What If. Boca Raton: Chapman & Hall/CRC.
Holmes, M. V., Asselbergs, F. W., Palmer, T. M., Drenos, F., Lanktree, M. B., Nelson, C. P., ... & Tragante, V. (2015). Mendelian randomization of blood lipids for coronary heart disease. European heart journal, 36(9), 539-550.
Imbens, G. W., & Rubin, D. B. (2015). Causal inference in statistics, social, and biomedical sciences. Cambridge University Press.
Millwood, I. Y., Walters, R. G., Mei, X. W., Guo, Y., Yang, L., Bian, Z., ... & Zhou, G. (2019). Conventional and genetic evidence on alcohol and vascular disease aetiology: a prospective study of 500 000 men and women in China. The Lancet, 393(10183), 1831-1842.
Morgan, S. L., & Winship, C. (2015). Counterfactuals and causal inference. Cambridge University Press.
Pearl, J. (2009). Causality. Cambridge university press.
Peters, J., Mooij, J. M., Janzing, D., & Schölkopf, B. (2014). Causal discovery with continuous additive noise models. The Journal of Machine Learning Research, 15(1), 2009-2053.
Peters, J., Janzing, D., & Schölkopf, B. (2017). Elements of causal inference: foundations and learning algorithms. MIT press.
Rader, D. J., & Hovingh, G. K. (2014). HDL and cardiovascular disease. The Lancet, 384(9943), 618-625.
Schölkopf, B. (2019). Causality for Machine Learning. arXiv.
Shvarev, Y. (2018). Observation and Experiment: An Introduction to Causal Inference.
Sudlow, C., Gallacher, J., Allen, N., Beral, V., Burton, P., Danesh, J., ... & Liu, B. (2015). UK biobank: an open access resource for identifying the causes of a wide range of complex diseases of middle and old age. PLoS medicine, 12(3).
Varma, P., Sala, F., He, A., Ratner, A., & Ré, C. (2019). Learning dependency structures for weak supervision models. arXiv preprint arXiv:1903.05844.
Voight, B. F., Peloso, G. M., Orho-Melander, M., Frikke-Schmidt, R., Barbalic, M., Jensen, M. K., ... & Schunkert, H. (2012). Plasma HDL cholesterol and risk of myocardial infarction: a mendelian randomisation study. The Lancet, 380(9841), 572-580.
Wang, Y., & Blei, D. M. (2019). The blessings of multiple causes. Journal of the American Statistical Association, 1-71.
Walker, V. M., Davey Smith, G., Davies, N. M., & Martin, R. M. (2017). Mendelian randomization: a novel approach for the prediction of adverse drug events and drug repurposing opportunities. International journal of epidemiology, 46(6), 2078-2089.
Wright, P. G. (1928). Tariff on animal and vegetable oils. Macmillan Company, New York.