Mar 1, 2020 · 8 min read
When Multi-Task Learning Works -- And When It Doesn’t
Sen Wu, Hongyang Zhang and Chris Ré.
Multi-task learning applied to heterogeneous task data can often result in suboptimal models (or negative transfer in more technical terms). We provide conceptual insights to explain why negative transfer happens. Based on the explanation, we propose methods to improve multi-task training. Based on our work in ICLR’20.
One of the most powerful ideas in deep learning is that sometimes you can take the knowledge learned from one task and apply that knowledge to help another task. For example, maybe a neural network has learned to recognize objects like cats and then help you do a better job finding other objects such as leopards. This is transfer learning, where you learn from task A, and then transfer that to task B. In multi-task learning, you start off simultaneously trying to have one neural network learn several tasks at the same time. And then each of the tasks hopefully helps all the other tasks.
Imagine you are building an autonomous driving vehicle. As a simplified example, the vehicle will need to detect several things, such as traffic lights, road surface marking, other cars on the road and pedestrians. In this example, for each image, your classification task comprises 4 output labels.
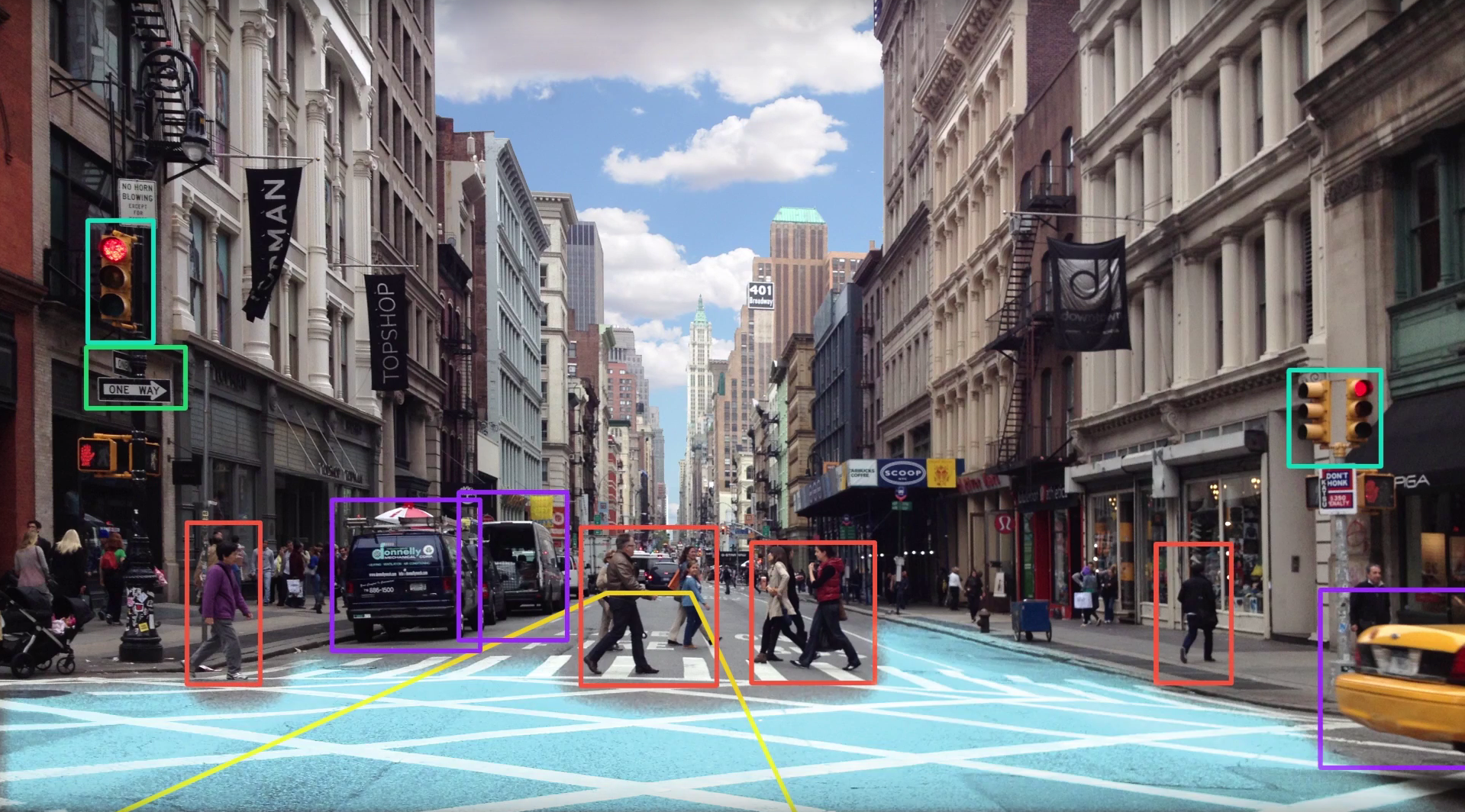
Figure 1: An autonomous driving car detecting unique details of the road scene.
As another example, imagine you are building a chatbot for customer service. The model will need to learn to execute a range of different linguistic tasks such as predicting whether the customer’s question reveals a positive or a negative sentiment, how to paraphrase a sentence. To help train a better model, you may also use publicly available data such as Yelp reviews using multi-task learning.


Figure 2: A sentiment analysis model can benefit from multi-task learning by learning from multiple related datasets.
The motivation of our study is that naive multi-task training of neural networks especially on heterogeneous tasks often results in suboptimal models for all the tasks.
To illustrate the phenomenon, we consider three tasks with the same number of data samples where tasks 2 and 3 have the same decision boundary but different data distributions. We observe that training task 1 with task 2 or task 3 can either improve or hurt task 1’s prediction accuracy, depending on the amount of contributing data along the decision boundary! Even though the three tasks have the same linear model, there is no guarantee that multi-task training always helps!
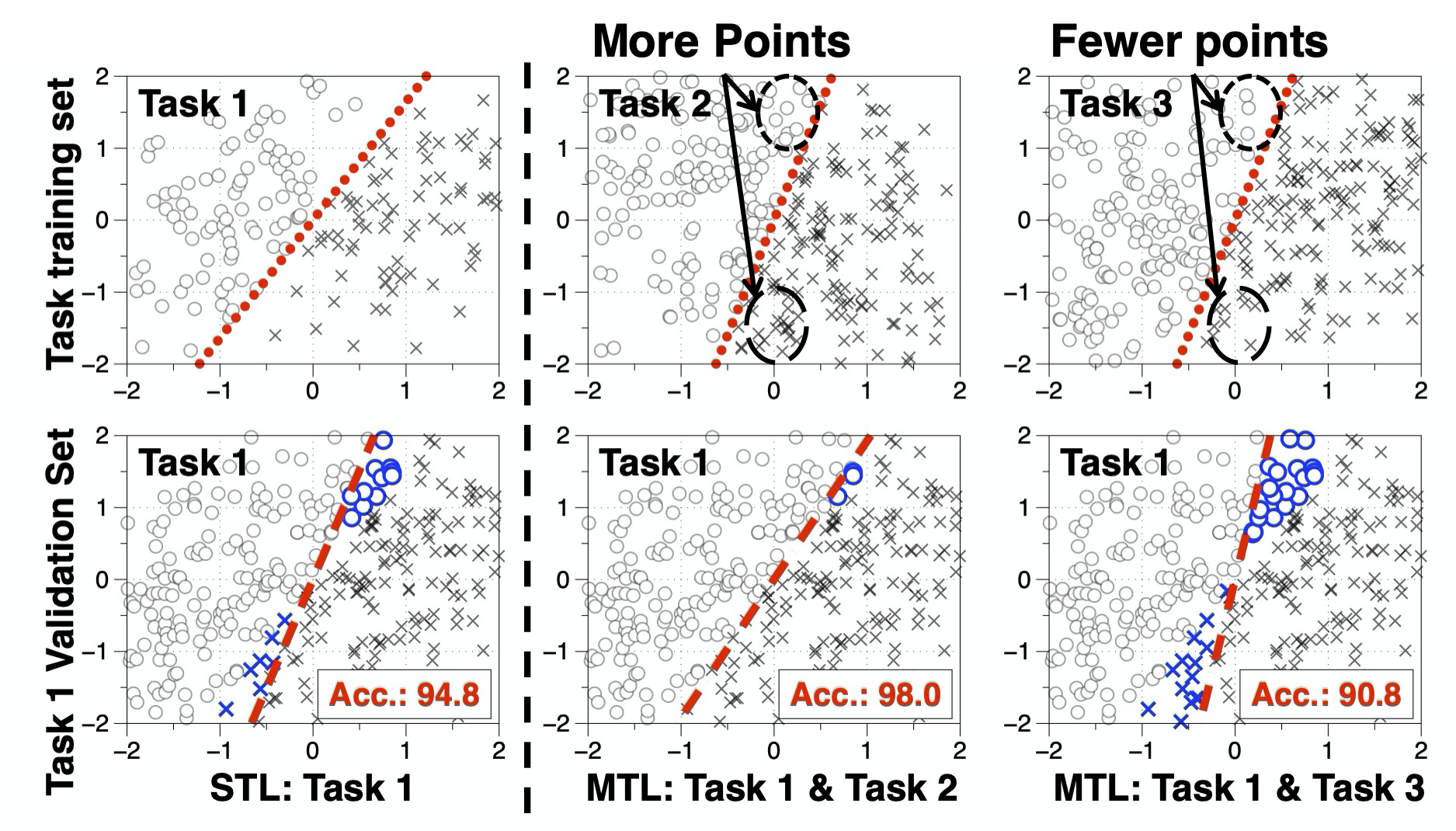
Figure 3: Positive vs. Negative transfer is affected by the data, not just the model. See lower right-vs-mid. Task 2 and 3 have the same model (dotted lines) but different data distributions. Notice the difference of data in circled areas.
Setup of Multi-Task Learning
We have several tasks as input for , where corresponds to task features (say a set of images or sentences) and corresponds to the labels of . In the autonomous driving example above, , corresponds to the images, and each corresponds to whether there are stop signs in the image or traffic lights, etc.
One way to solve the problem is by using the so-called hard parameter sharing architecture.
- There is a shared module that encodes the feature representation for all tasks. For image classification tasks, can be a CNN such as ResNet. For text classification tasks, can be pre-trained representations such as BERT.
- Each task has a specific output prediction head .
- To train the neural network, you write a loss function that sums over the losses of the predictions for each individual task:
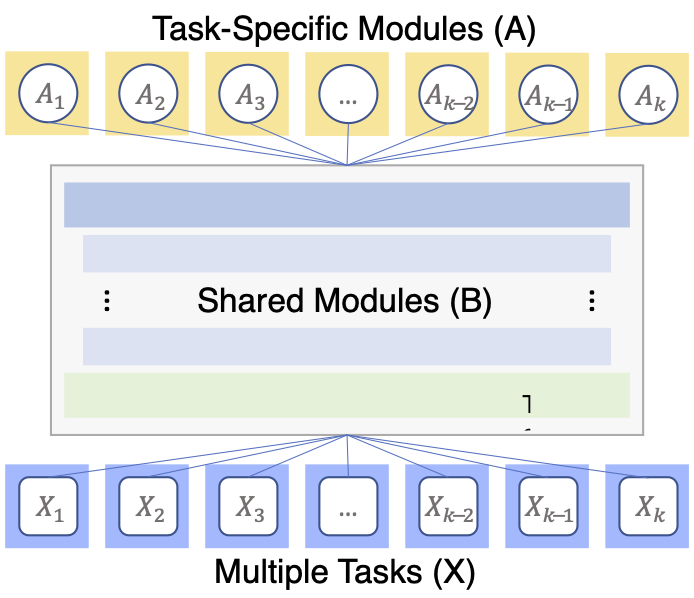
Figure 4: An illustration of the multi-task learning architecture with a shared lower module and task-specific modules .
And the loss function is the usual cross-entropy loss for multi-class classification problems. In our study, we ask:
What are the key components to determine whether multi-task learning (MTL) is better than single-task learning (STL)? In response, we identify three components: model capacity, task covariance and optimization scheme.
Three Factors that Can Result in Negative Transfer
Model capacity. The capacity of the shared module, i.e. its output dimension, plays a fundamental role because, if the shared module is too large, there can be no interference (or transfer of knowledge) between tasks since each of them can be memorized in the shared module which results in zero training loss. If it is too small, there can be destructive interference.
As a rule of thumb, we find that the shared module is best performing when its capacity is smaller than the total capacities of the single-task models. As an example, the right table contains the results for sentiment analysis on six language datasets.
- The best performing MTL model has capacity 100.
- The capacities of the best performing STL models are twice as large on average.
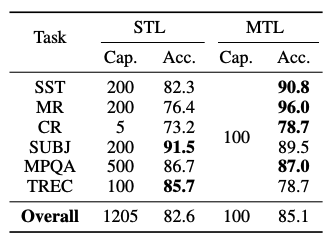
Figure 5: Comparing the model capacity between multi-task learning and single-task learning.
Task covariance. To determine the interference between different tasks, we measure how similar two tasks are by a fine-grained notion called task covariance. As an example, to measure the similarity of two tasks composed of sentences and paragraphs, we encode each sentence into an embedding by replacing each word with a word vector followed by average pooling. By measuring the cosine similarity between two embeddings, we can get information such as the semantic similarities and the use of similar words between the two tasks.
Task covariance measures the alignment of two task input data among their principal directions. Our intuition is that if the principal directions of two task input data are not well-aligned, feeding them into the shared module can cause suboptimal models. To deal with this issue, we propose a covariance alignment algorithm to improve multi-task training by adding an alignment module between task and the shared module .
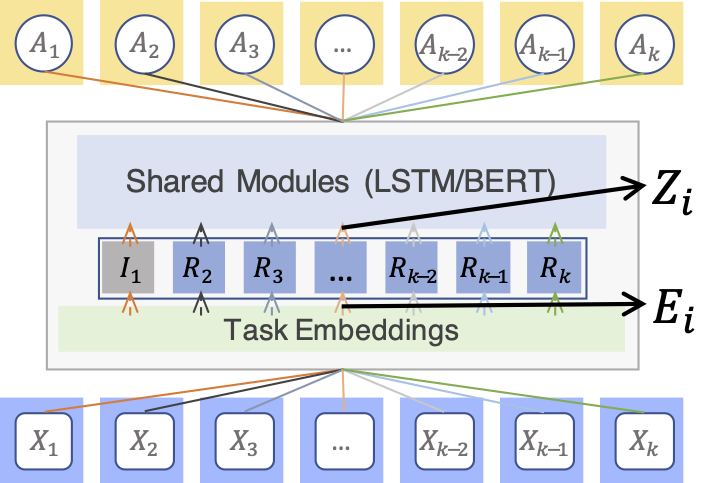
Figure 6: Illustration of the covariance alignment module on task embeddings.
Our experiments on five tasks from the GLUE benchmark using a state-of-the-art BERT LARGE model confirms that aligning the task covariances improves the performance of BERT LARGE by 2.35% average GLUE score.
Optimization scheme. The order in which we optimize a multi-task learning neural network can also determine the interference between tasks. A typical training strategy is to randomly mix the mini-batches of different task data. For an important task, we may also increase the task weight by duplicating its data. In our work, we propose a reweighting scheme to improve the robustness of multi-task training in the presence of label noise. We compute the per-task weights by identifying the importance of each task via an SVD procedure. Intuitively, a task is important is the task contains common knowledge that can be shared by other tasks. To identify an important task, we first compute the SVD of the aggregated task embeddings. Then we re-weight a task by its projection to the principal components from SVD.
Implementation via Emmental: A New Package for Building Multi-Task Models
We conduct our experiments using Emmental, which is a framework for building multi-modal multi-task learning systems quickly and easily. Emmental provides a higher-level abstraction of deep learning models which enables users to specify and train their applications in a declarative way. Users only need to provide data and specify how data flows during the model. Emmental can then automatically handle the training and optimization procedure.