Feb 28, 2020 · 11 min read
Towards Interactive Weak Supervision with FlyingSquid
Dan Fu, Mayee Chen, Fred Sala, Sarah Hooper, Kayvon Fatahalian, and Chris Ré
Modern machine learning models require a lot of training data to be successful. Over the past few years, we've been studying programatically creating labels with weak supervision to address this training data bottleneck; instead of relying on manual labels, data programming uses weak supervision---multiple noisy label sources---to automatically generate labeled datasets. With help from our awesome collaborators, these ideas have seen a surprisingly broad degree of impact and is in use in applications used by many people every day, including in Gmail, AI products at Apple, and search products at Google.
The key behind our weak supervision work has been a set of techniques to learn the accuracies of -- and potentially correlations between -- multiple noisy label sources. FlyingSquid is our latest work in this direction---it exploits a powerful three views technique to quickly generate a model producing labels. This helps speed up the the label generation process. This speedup brings us a step closer to faster and more interactive development cycles for weak supervision, with exciting implications for applications like video and online learning.
Modern machine learning models require a lot of training data to be successful. Over the past few years, we've been studying programatically creating labels with weak supervision to address this training data bottleneck; instead of relying on manual labels, data programming uses weak supervision---multiple noisy label sources---to automatically generate labeled datasets. With help from our awesome collaborators, these ideas have seen a surprisingly broad degree of impact and is in use in applications used by many people every day, including in Gmail, AI products at Apple, and search products at Google.
The key behind our weak supervision work has been a set of techniques to learn the accuracies of -- and potentially correlations between -- multiple noisy label sources. FlyingSquid is our latest work in this direction---it exploits a powerful three views technique to quickly generate a model producing labels. This helps speed up the the label generation process. This speedup brings us a step closer to faster and more interactive development cycles for weak supervision, with exciting implications for applications like video and online learning.
Our paper Fast and Three-rious: Speeding Up Weak Supervision with Triplet Methods is available on arXiv, and our code is available on GitHub (including a PyTorch integration for online learning)!
Latent Variables, Models, and Triplets, Oh My!
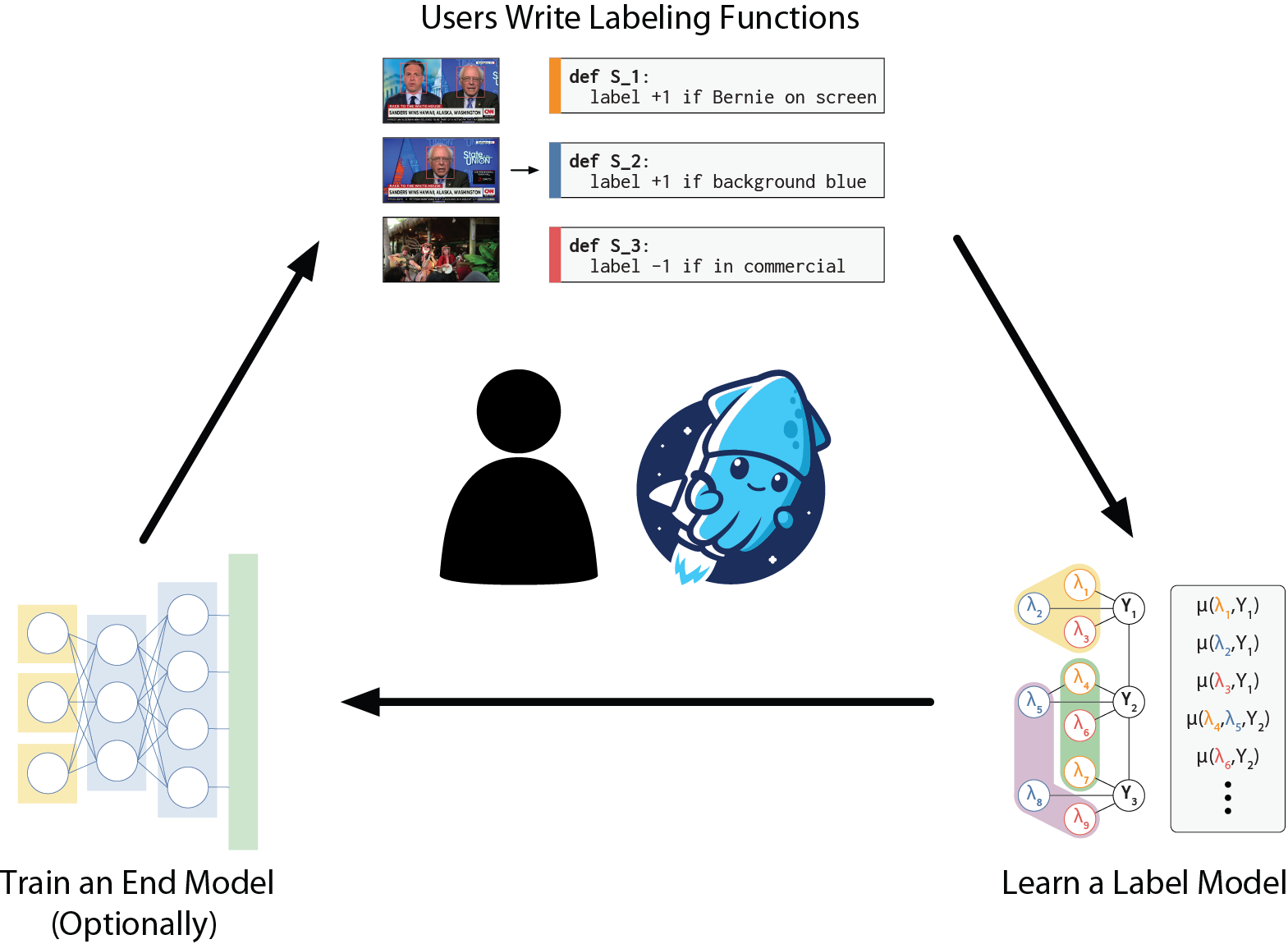
When generating datasets with weak supervision, the name of the game is letting users use their intuition to write labeling functions, and then aggregating their noisy outputs to automatically label training data.
For example, someone trying to build a model to detect interviews with Bernie Sanders on TV may write some simple Python code to look for his name in the transcript, or use an off-the-shelf face detector to detect his face in the video feed. Data programming frameworks take a few of these labeling functions, learn their accuracies and correlations, and then generate probabilistic training data for some powerful end model like a ResNet (all without ground truth labels).
We can model the outputs of the labeling functions (along with the unseen label) as a latent variable model. How is it possible to learn the parameters of a such a model without ever observing one of its components? Remarkably, sufficient signal is provided by independence. That is, we need some of our labeling functions to be independent conditioned on the true label.
The minimum amount of independence we need to learn our model is three conditionally independent labeling functions. These triplets provide three views of the unobserved true label. This elegant idea was observed by (Halpern and Sontag 2013, Joglekar et al. 2013, Chaganty and Liang 2014), and others.
In FlyingSquid, we learn the model parameters usnig triplets and obtain a set of closed-form solutions, instead of relying on SGD!
This has a few key advantages:
- Since we don't have to wait for SGD to take many small steps towards the solution, FlyingSquid runs orders of magnitude faster than previous weak supervision networks (especially for applications like image or video analysis where modeling spatial and temporal correlations was previously very slow).
- Removing SGD from the training loop also makes it easier to train an accurate label model with FlyingSquid, since there are fewer hyperparameters to tune (no more learning rates, momentum parameters, etc).
- In some cases, the label model even ends up being more accurate than the end model. This means we can remove the end model from the development loop, and it's often no worse than if we had spent hours training!
- We can provide tight theoretical bounds on model performance. Even without ground truth labels on our dataset, we can train a model whose generalization error scales at the same asymptotic rate as supervised approaches. Our result also takes potential model misspecification into account, showing that we can bound the generalization error even when our label model does not perfectly model the underlying data distribution!
In the rest of this blog post, we’ll discuss how we estimate label model parameters in FlyingSquid, and present some experimental results showing how FlyingSquid enables exciting applications in video analysis. We also show how FlyingSquid enables new online learning settings (we present an extension where we train the label model in the training loop of a deep network). Full details in our paper on arXiv!
Triplets Are All You Need
The key technical challenge in weak supervision is estimating the accuracies of -- and potentially the correlations among -- multiple noisy labeling functions without any ground truth data. There’s been a lot of research showing that using latent variable probabilistic graphical models (PGMs) to model these dependencies is a good approach for getting high performance in weak supervision (Varma et al 2019, Sala et al 2019, Ratner et al 2018). We didn't want to reinvent the wheel, so we decided to take this approach in FlyingSquid as well. PGMs can model labeling functions as observed variables (’s), with the true unobserved ground-truth labels as a hidden variable ():
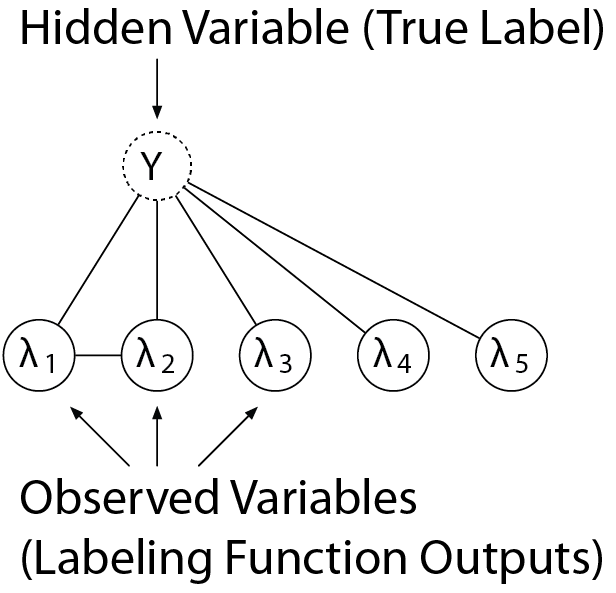
Edges indicate correlations between different variables. For example, the output of each labeling function (each ) is correlated with the ground truth label (). In this particular graph, we also have that two of the labeling functions ( and ) have an additional correlation that is not captured by their relationship to the ground truth label (for example, they could share a sub-routine or express similar heuristics). These dependency graphs can be user-provided, but previous work also suggests that they can be learned directly from labeling function outputs (Varma et al., 2019).
The nice thing about modeling labeling functions with PGMs is that we can capture a wide array of dependencies like the ones above and more. For example, we can model temporal dependencies in video tasks by saying that neighboring frames are correlated:
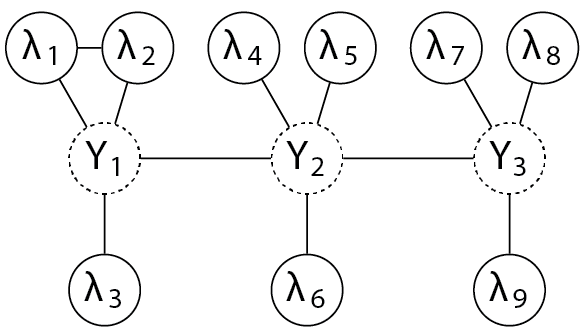
In the above graph, each models the ground-truth label of a single frame in a video sequence, and labeling functions label individual frames (which some previous work has suggested is important for achieving high accuracies in tasks with sequential dependencies like video).
Unfortunately, solving the parameters of these PGMs (e.g., learning the weights of the edges) can be difficult, especially for tasks like video where modeling more temporal dependencies can result in much wider graphs. In our previous work, we have often hand-crafted a black-box loss function based on the observed agreements and disagreements between labeling funcitons, and used SGD to learn graphical model parameters by optimizing the loss function (thanks PyTorch and autograd!). But this can be very expensive, and also often requires tuning SGD parameters like the number of iterations, learning rate, etc.
Luckily, there is a robust body of work on efficiently learning the parameters of graphical models (a lot of which has been used for similar applications like crowdsourcing, clinical tagging, and EMR phenotyping). We realized that we can apply similar techniques to our graphical modeling problem -- if we can identify triplets of conditionally-independent observable variables, we can construct a system of equations based on their agreements and disagreements that has an analytical solution (this method is sometimes called the method of moments, since the agreement rate between two labeling functions can be expressed as the second-order moment). For example, in the above two graphs, we can construct these highlighted groups of triplets:
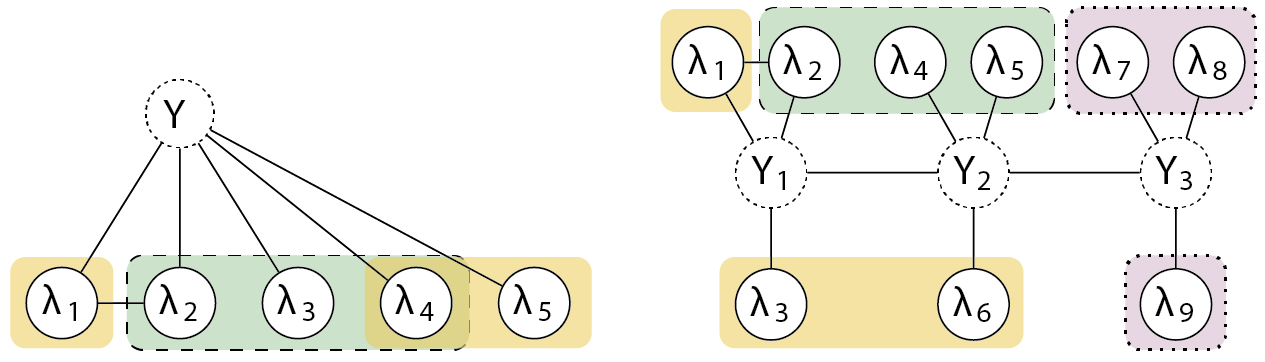
Since the systems of equations from this method have an analytical solution, it reduces the parameter estimation problem from optimizing a black-box loss function to making a few matrix calculations in numpy -- resulting in speedups of multiple orders of magnitude!
The nice thing about this method is that we can also theoretically analyze the downstream performance of our method and prove bounds on its sampling and generalization error. In particular,
- We show that the sampling error of the parameters of the graphical model scales as in the number of training samples, and prove that this bound is information-theoretically tight.
- We prove that the generalization error for the end model also scales in , which is the same asymptotic rate as supervised approaches.
- We show that this generalization bound holds even when the underlying data distribution cannot be represented with our PGM, and our new analysis approach quantifies these tradeoffs in model selection (more complex models may represent the data better, but also require more training data to learn).
Check out our paper on arXiv for more details on our method and analysis results!
Applications in Video and Online Learning
Now we’ll give a short preview of some of the ways that we were able to exploit this technique to push towards faster and more interactive weak supervision with FlyingSquid -- more details about all these experiments and applications in our paper!
We validated FlyingSquid on a number of video analysis applications, ranging from media applications like commercial detection in TV news to sports analysis applications like segmenting tennis rally segments from broadcast tennis footage. FlyingSquid runs up to 4,000 times faster than a previous weak supervision framework for sequential data, while achieving comparable or higher model performance:
| End Model Performance (F1), best in bold | ||
|---|---|---|
| Task | Sequential Snorkel | FlyingSquid (label model in paren.) |
| Interviews | 92.0 | 91.9 (94.3) |
| Commercials | 89.8 | 92.3 (88.4) |
| Tennis Rally | 80.6 | 82.8 (87.3) |
| Label Model Training Time (s), best in bold | ||
| Interviews | 256.6 | 0.423 |
| Commercials | 265.6 | 0.067 |
| Tennis Rally | 398.4 | 0.199 |
Sometimes, we found that we could use the label model directly to get better (or comparable) performance as the end models. Often these tasks can take advantage of powerful pre-trained models to express higher-level concepts that are difficult to learn directly (for example, the labeling functions for the tennis rally task use off-the-shelf object detectors that already know what people look like). In these cases, completing the weak supervision loop with FlyingSquid is instantaneous, since you don’t have to train an end model. This means that we can rapidly iterate on labeling functions and immediately see how they affect end performance. We’re really excited about what this means for interactive video analysis applications -- especially in conjunction with previous work like Rekall.
We can also exploit FlyingSquid’s speed to enable new online learning applications, where we can continuously update label model and end model parameters over time. This means that we now adapt to distributional drift over time (when the underlying data distribution is changing in some way). Here’s a synthetic experiment that demonstrates when this can be helpful:
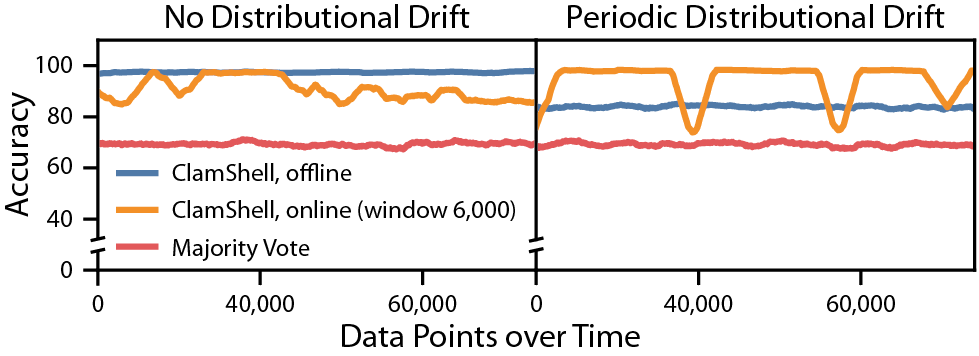
In situations with little to no distributional drift (left), offline learning often works better, since learning methods can optimize over more data; but in settings with heavy distributional drift (right), online learning can continuously adapt the model to changing data streams (whereas offline learning has trouble finding a single model that can account for all the data).
Our paper has more details on these and other experiments -- we show simple proofs of concept about how we can use online learning over large video datasets, and we also validate FlyingSquid on benchmark weak supervision tasks that have been used to evaluate previous frameworks like Snorkel. We also release a PyTorch layer that automatically integrates FlyingSquid into the end model training loop.
For more details, check out our paper on arXiv, and our code on Github!