Feb 26, 2020 · 6 min read
Automating the Art of Data Augmentation
Part IV New Direction
Karan Goel, Albert Gu, Sharon Li and Chris Ré
Data augmentation techniques have proven powerful in building machine learning models in applications such as image and text classification. However, most of the machine learning research today is still carried out solving fixed tasks. In the real world, machine learning models in deployment can fail in various ways, due to unanticipated changes in data. This raises the important question of how we can move from model building to model maintenance in an adaptive manner. In this post, we’d like to shed some light on this question through the lens of model patching—the first framework that exploits data augmentation to mitigate the performance issue of a flawed model in deployment.
What is Model Patching?
Model patching enables automating the process of model maintenance and improvement when a deployed model exhibits flaws. Model patching is becoming a late breaking area that would alleviate the major problem in safety-critical systems, including healthcare (e.g. improving models to produce MRI scans free of artifact) and autonomous driving (e.g. improving perception models that may have poor performance on irregular objects or road conditions).
To give a concrete example, in skin cancer detection, researchers have shown that standard classifiers have drastically different performance on two subgroups of the cancerous class, due to the classifier’s association between colorful bandages with benign images (see Figure 1, left). This subgroup performance gap has also been studied in parallel research from our group (Oakden-Rayner et al., 2019), and arises due to classifier's reliance on subgroup-specific features, e.g. colorful bandages.
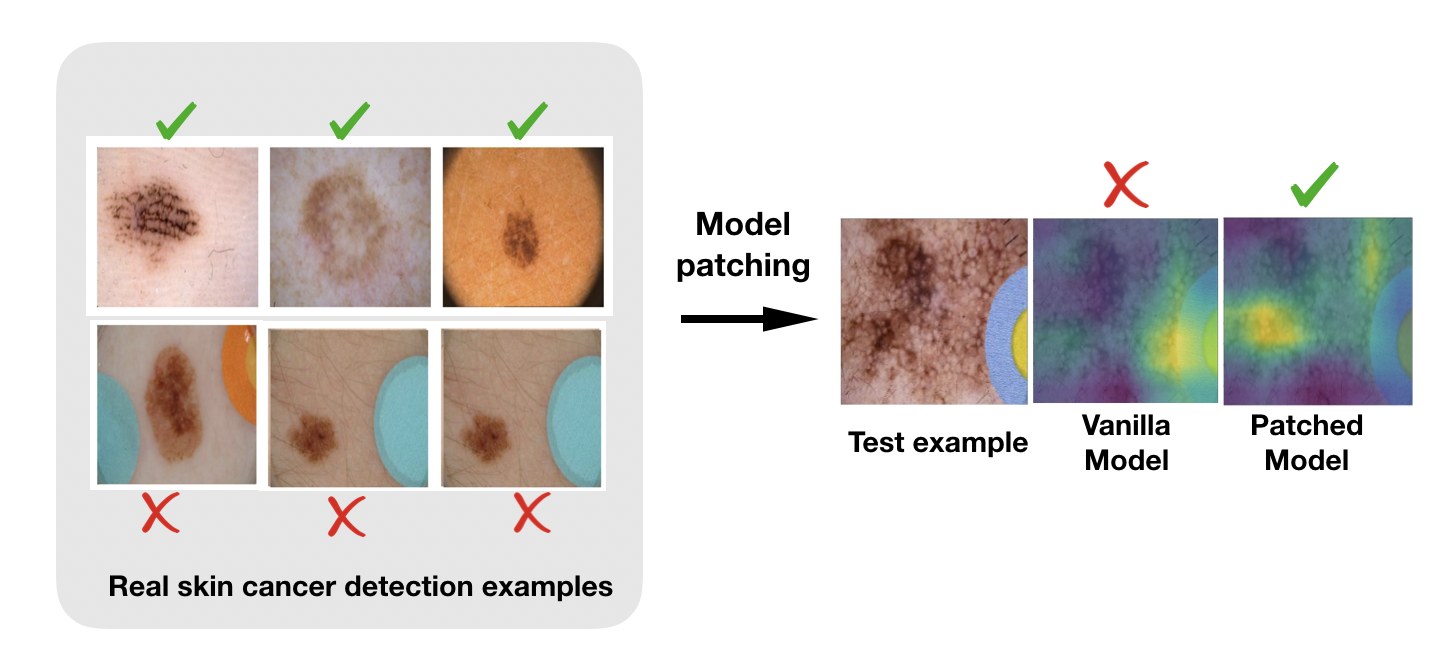
Figure 1: A standard model trained on a skin cancer dataset exhibits a subgroup performance gap between images of malignant lesions with and without colored bandages. GradCAM illustrates that the vanilla model spuriously associates the colored spot with benign skin lesions. With model patching, the malignancy is predicted correctly for both subgroups.
In order to fix such flaws in a deployed model, domain experts have to resort to manual data cleaning to erase the differences between subgroups, e.g. removing markings on skin lesion data with Photoshop (Winkler et al. 2019), and retrain the model with the modified data. This can be extremely laborious!
How can we automate this tedious process for domain experts? Can we somehow learn transformations that allow augmenting examples to balance population among groups in a prescribed way? This is exactly what we are addressing through this new framework of model patching.
How Does Model Patching Work?
We start by presenting the conceptual framework of model patching, which consists of two stages (as shown in Figure 2).
- Learn inter-subgroup transformations between different subgroups. These transformations are class-preserving maps that allow semantically changing a datapoint's subgroup identity (e.g. add or remove colorful bandages).
- Retrain to patch the model with augmented data, encouraging the classifier to be robust to their variations.
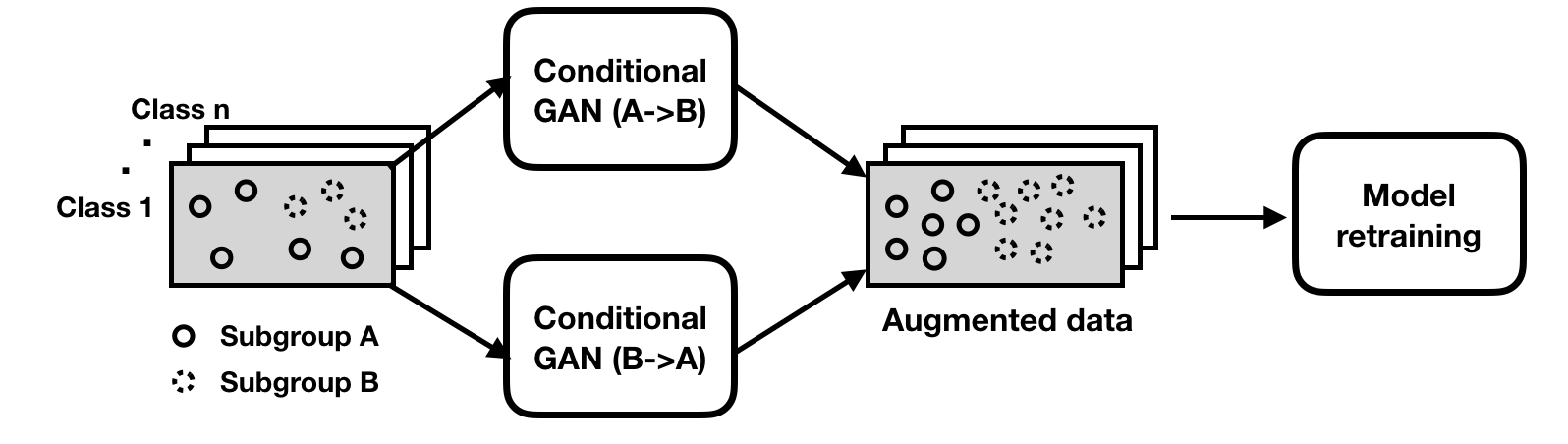
Figure 2: Model Patching framework with data augmentation. The highlighted box contains samples from a class with differing performance between subgroups A and B. Conditional generative models are trained to transform examples from one subgroup to another (A->B and B->A) respectively.
CLAMP: An Instantiation of Model Patching
Now we describe Class-conditional Learned Augmentations for Model Patching (CLAMP), an instantiation of our first end-to-end model patching framework.
CLAMP instantiates the first stage of model patching with CycleGANs (Zhu et al. 2017). The generative models are trained class-conditionally to transfer examples from one subgroup to another. The transformation functions learned are semantically meaningful, intended to capture the salient features between the subgroups of interest. This contrasts with previous data augmentation approaches where the generator learns to compose augmentations via generic transformation functions.
Perhaps the major challenge of model patching lies in the second stage—model retraining. While seemingly straightforward, solutions that directly use augmented data for training can fail, since the augmentations will typically introduce artifacts that may distort class information. To mitigate this issue, we introduce a novel subgroup consistency regularizer which provably forces the classifier to (1) preserve the class information; and (2) become invariant to subgroup-specific features.
We use Figure 3 to illustrate how our regularizer works. For a given data point x, we apply the transformations learned through CycleGAN and obtain augmented examples in subgroup A and B respectively. Our regularizer Lt encourages the prediction on x to be similar to the average prediction of CycleGAN-translated examples, and Ls encourages the predictions on corresponding augmented examples to be consistent with each other. In our training objective, this can be formulated in terms of KL-divergence in the output space.
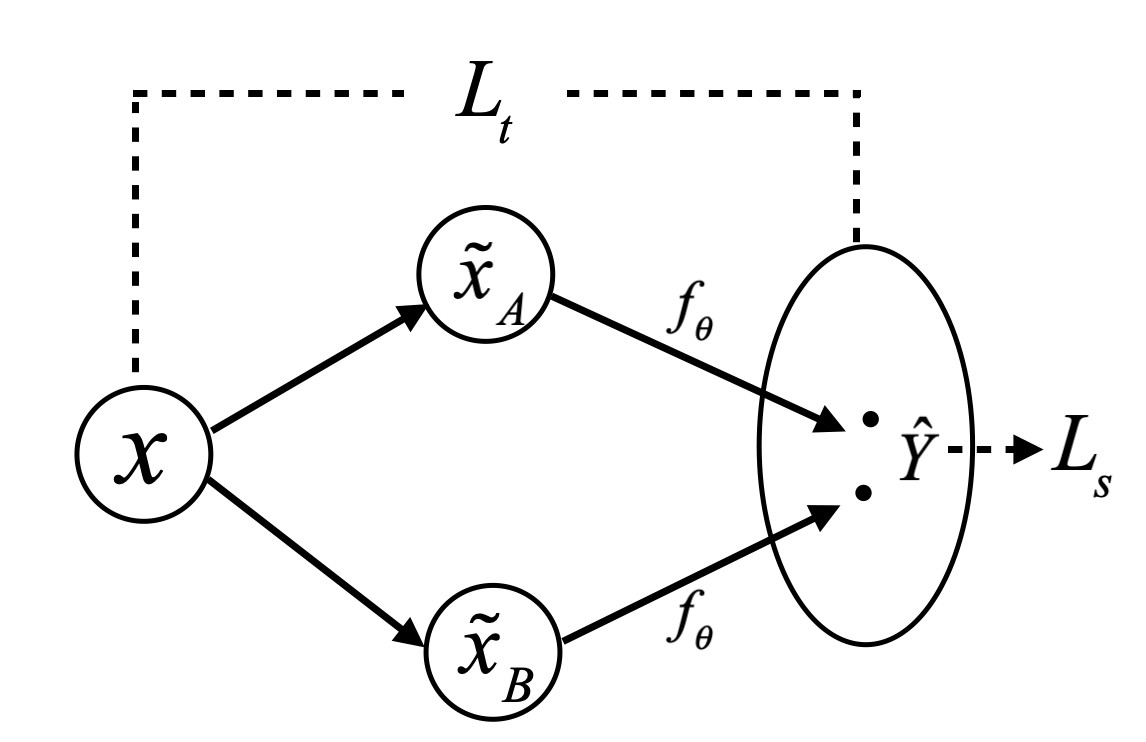
Figure 3. Illustration of subgroup consistency regularizer.
We further combine this regularizer with a robust training objective that is inspired by recent work of Group Distributionally Robust Optimization (GDRO, Sagawa et al. 2019). We extend GDRO to a class-conditional training objective that jointly optimizes for the worst-subgroup performance in each class. Taken together, these steps comprise our full method Class-conditional Learned Augmentations for Model Patching (CLAMP), the first end-to-end instantiation of our model patching framework.
CLAMP’s Performance
Does our model patching method produce better end classifier results than vanilla ERM and robust training baselines? To answer this question, we evaluate CLAMP on various benchmark datasets including MNIST, CelebA, Waterbirds, and a real-world skin cancer dataset ISIC. For each model, we measure overall average accuracy, as well as robust accuracy on the worst-performing subgroup.
On several benchmark datasets, Table 1 shows that CLAMP can improve both the aggregate and robust accuracy, mitigating the tradeoff between the two that ERM and GDRO experience. Furthermore, CLAMP is able to balance the performance of subgroups within each class, reducing the performance gap by up to 24x. On real-world clinical dataset ISIC, CLAMP improves robust accuracy by 11.7% compared to the robust training baseline. Through visualization, we also show in Figure 1 that CLAMP successfully removes the model’s reliance on the spurious feature (colorful bandages), shifting its attention to the skin lesion—true feature of interest.
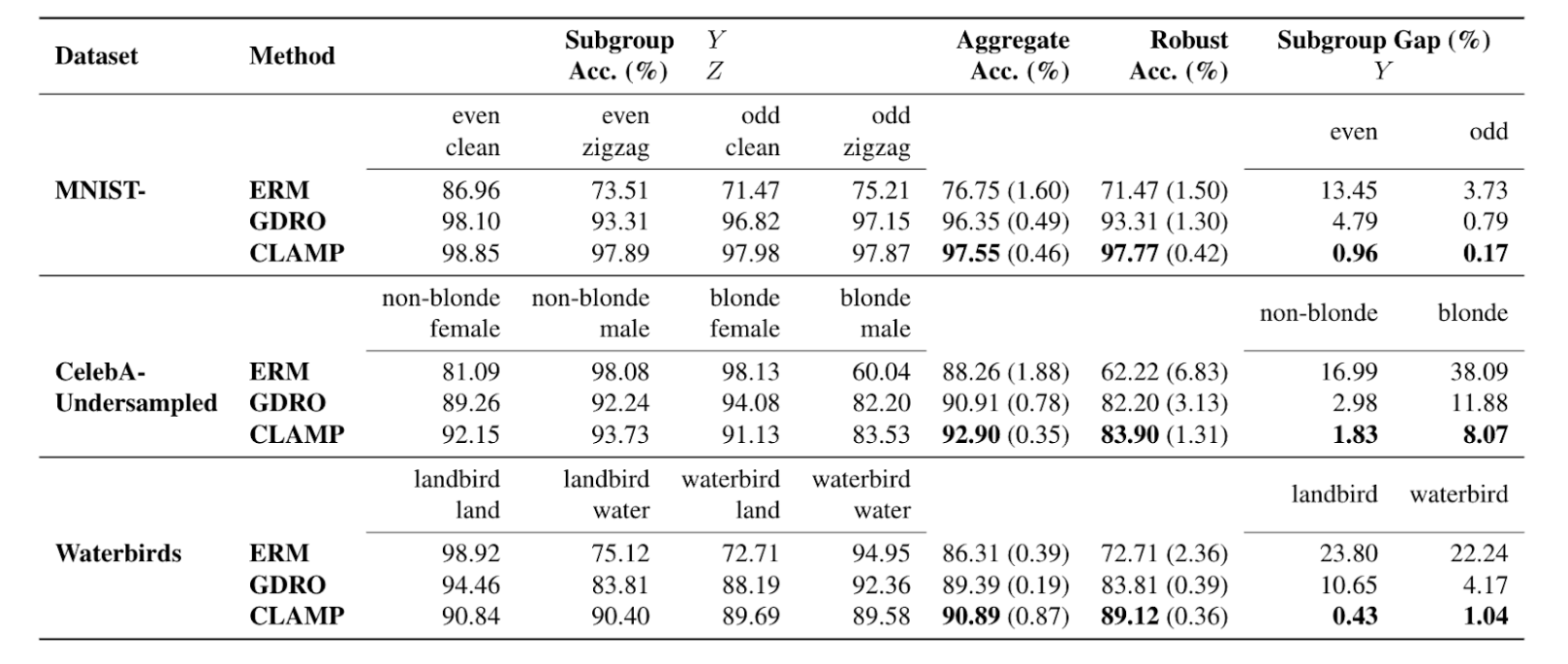
Table 1. A comparison between CLAMP and other methods. For each dataset, Y denotes class label and Z denotes subgroup label. Evaluation metrics include robust accuracy (i.e. worst-performance among all subgroups), aggregate accuracy and the subgroup performance gap. Results are averaged over 3 trials (one standard deviation is indicated in parentheses).
Our results suggest that the model patching framework is a promising direction for automating the process of model maintenance. We envision that model patching can be widely useful for many other domain applications. If you are intrigued by the latest research on model patching, please follow our Hazy Research repository on Github where the code will be released soon.
Our work is still in progress. If you have any feedback, we’d like to hear from you!