Feb 26, 2020 · 8 min read
Automating the Art of Data Augmentation
Part III Theory
Edited by Hongyang Zhang, Sharon Li and Chris Ré. Referencing work by many other members of Hazy Research.
As we have seen in the previous blog post, data augmentation techniques have achieved remarkable gains when applied to neural network models. In this blog post, we reflect on the success story of various augmentation techniques and review our recent work that study theoretical properties of data augmentation.
We begin by describing the work of Dao et al. 2019 that consider what happens if data augmentation is applied to kernel methods. We show that data augmentation averages the feature map of kernel features after applying various transformations. Then we describe the work of Wu et al. 2020 that consider the generalization effect of linear transformations in an over-parametrized linear regression setting. As a consequence of our theory, we describe an uncertainty-based random sampling algorithm that achieves SoTA results over CIFAR and ImageNet datasets!
Data Augmentation in Kernel Methods
Inspired by the empirical success of TANDA, Dao et al. 2019 develop a theoretical framework to better understand data augmentation in kernel methods. The conceptual message is that the feature map of an augmented kernel using various transformations is equivalent to the average of all transformed feature maps.
Augmented kernel feature map. Dao et al. 2019 model data augmentation as a Markov Chain over various transformation functions. The Markov Chain is defined as follows: (i) we choose a data sample (say an image) uniformly at random from the training dataset; (ii) we define a transition from one data sample to another by applying a transformation chosen from a predefined set randomly according to some fixed probabilities; (iii) we terminate the Markov Chain with some probability, thus limiting the number of transformations in a composition. Suppose that we use a k-nearest neighbor classifier over the kernel features as our predictor. The question is, how does applying the Markov Chain over the training dataset affect the k-nearest neighbor classifier? As a remark, the result that we are going to descirbe is not specific to the k-nearest neighbor classifier and applies more generally.
Effect of augmentation: invariance and regularization. The main result of Dao et al. 2019 is that applying the Markov Chain on a training dataset is equivalent to a applying a k-nearest neighbor classifier over the set of all transformed samples (cf. Theorem 1). This general result has two implications as follows.
First, training a kernel linear classifier plus data augmentation is equivalent, to first order, to training a linear classifier on an augmented kernel. The new kernel has the effect of increasing the invariance of the model, as averaging the features from transformed inputsthat are not necessarily present in the original dataset makes the features less variable to transformation. Second, the second-order approximation of the objective on an augmented dataset is equivalentto variance regularization, making the classifier more robust. Dao et al. 2019 further validate the above two implications empirically and draw connections to other generalization-improving techniques, including recent work in invariant learning and robust optimization (Namkoong & Duchi, 2017).
Related work. We mention two closely related work. First, Chen et al. 2019 recently show a conceptually similar result to Dao et al. 2020 that the augmented classifier averages over a set of transformed classifiers using group theory. Second, a very interesting recent work by Shankar et al. 2020 show that a simple neural network arthicture applied on a composition of kernels achieves 90% accuracy on CIFAR-10.
Data Augmentation in an Over-Parametrized Setting
One limitation of the above works is that it is challenging to understand the precise effect of applying a particular transformation on the resulting kernel. In Wu et al. 2020, we consider an over-parametrized linear regression setting and study the generalization effect of applying a familar of linear transformations in this setting.
//: # (In the field of deep learning, data augmentation is commonly understood to act as a regularizer by increasing the number of data points and constraining the model (Zhang et al. 2017). The folklore wisdom behind data augmentation is that adding more labeled data improves generalization, i.e. the performance of the trained model on unseen test data (Shorten & Khoshgoftaar, 2019). However, even for simpler models, it is not well-understood how training on augmented data affects the learning process, the parameters, and the decision surface of the resulting model. This is exacerbated by the fact that data augmentation is performed in diverse ways in modern machine learning pipelines, for different tasks and domains, thus precluding a general model of transformation.)
Linear transformations. We consider a family of linear transformations that is capable of modeling a wide variety of image transformations. We consider three categories.
- Label-invariant base transformation functions such as rotation and horizontal flip;
- Label-mixing transformations including mixup (Zhang et al., 2017; Inoue, 2018), which produce new data by randomly interpolating the features of two data points (e.g. a cat and a dog) as well as the associated labels;
- Compositions of label-invariant base transformations such as random cropping and rotation followed by horizontal flipping (as in TANDA and AutoAugment).
Theoretical insights. We show the following theoretical insights by considering a conceptually simple over-parametrized linear model, where the training data lies in a low-dimensional subspace. This setting captures the need to add more labeled data as in image classification tasks.
- Our first insight is that label-invariant transformations can add new information to the training data. In our conceptualized model, we show that the estimation error of the ridge estimator can be reduced by adding new points that are outside the span of the training data.
- Our second insight is that mixup (Zhang et al. 2017) can play an effect of regularization through shrinking the weight of the training data relative to the L2 regularization term on the training data. We validate this insight on MNIST by showing that mixing same-class digits can reduce the variance (instability) of the predictions made by the trained model.
- Finally, for compositions of label-invariant transformations, we can show that they have an effect akin to adding new information as a corollary of combining multiple label-invariant transformations. However, the effect can be either positive or negative.
Related work. We mention two closely related work. First, Raghunathan et al. 2020 study a similar over-parametrized linear setting but focuses more on the robustness of the trained model in the presence of adversarial examples. The difference between our setting and Raghunathan et al. 2020 is that we do need add fresh noise to a transformed sample and we study the ridge estimator as opposed to the minimum norm estimator. Second, Rajput et al. analyze the robustness of applying data augmentation by quantifying the margin that data augmentation enforces on empirical risk minimizers.
From Theory to Practice: Establishing State-of-the-art Performance
Based on the theory of Wu et al. 2020,
//: # (For RandAugment, since the algorithm samples over the space of transformations uniformly at random, the resulting trained model averages the effect of each transformation.)
we propose an uncertainty-based random sampling scheme which, among the transformed data points, picks those with the highest losses, i.e. those “providing the most information” (see Figure 1). We find that there is a large variance among the performance of different transformations and their compositions. Unlike RandAugment (Cubuk et al., 2019), which averages the effect of all transformations, the idea behind our sampling scheme is to better select the transformations that can improve the accuracy of the trained model more than others.
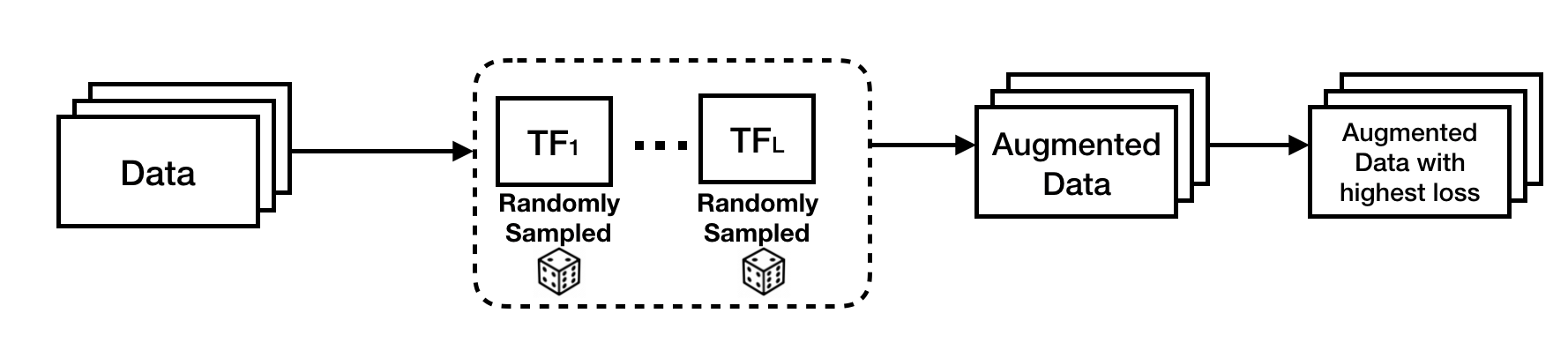
Figure 1: An illustration of our proposed uncertainty-based random sampling scheme. Each transformation function is randomly sampled from a set of pre-specified operations. We select among the transformed data points with highest loss for end model training.
We show that our proposed scheme improves performance on a wide range of datasets and models. Our sampling scheme achieves higher accuracy by finding more useful transformations compared to RandAugment on three different CNN architectures. For example, our method outperforms RandAugment by 0.59% on CIFAR-10, 1.24% on CIFAR-100 using Wide-ResNet-28-10, and 1.54% on ImageNet using ResNet-50. Our method also achieves comparable test accuracy to a state-of-the-art method, Adversarial AutoAugment (Zhang et al. 2019). Since we only need to do inference on the augmented data without needing to train an additional adversarial network, our method reduces the cost of training the model by 5x compared to Adversarial AutoAugment.
References
- A kernel theory of modern data augmentation. Tri Dao, Albert Gu, Alexander J. Ratner, Virginia Smith, Christopher De Sa, and Chris Ré. ICML 2019.
- On the generalization effects of linear transformations in data augmentation. Sen Wu, Hongyang Zhang, Greg Valiant, and Chris Ré. ICML 2020.
- Code repository for our uncertainty-based random sampling algorithm.