Feb 26, 2020 · 6 min read
Automating the Art of Data Augmentation
Part II Practical Methods
Instead of performing manual search, automated data augmentation approaches hold promise to search for more powerful parameterizations and compositions of transformations. Perhaps the biggest difficulty with automating data augmentation is how to search over the space of transformations. This can be prohibitively expensive due to the large number of transformation functions in the search space. How can we design learnable algorithms that explore the space of transformation functions efficiently and effectively, and find augmentation strategies that can outperform human-designed heuristics? In this blog post, we describe a few recent practical methods that address this important problem.
Learnable Data Augmentations
TANDA (Ratner et al. 2017) proposes a method to learn augmentations, which models data augmentations as sequences of Transformation Functions (TFs) provided by users. For example, these might include "rotate 5 degrees" or "shift by 2 pixels". This framework consists of two core components (1) learning a TF sequence generator that results in useful augmented data points, and (2) using the sequence generator to augment training sets for an downstream model. Under this framework, the objective and design choice of the TF sequence generator can be instantiated in various ways. Using a similar framework, a subsequent line of work including AutoAugment (Cubuk et al. 2018), RandAugment (Cubuk et al. 2019) and Adversarial AutoAugment (Zhang et al. 2019) have demonstrated state-of-the-art performance using learned augmentations.
In the following, we describe these methods that attempt to learn data augmentations in more detail.
TANDA
In TANDA, a TF sequence generator is trained to produce realistic images by having to fool a discriminator network, following the GANs framework (Goodfellow et al. 2014). That is, we can reasonably assume that we won't turn an image of a plane into one of a dog, but we might turn it into an indistinguishable garbage image! Such an assumption allows us to leverage generative adversarial networks (GANs), where we simultaneously learn a generator and a discriminator. As shown in Figure 1, the objective for the generator is to produce sequences of TFs such that the augmented data point can fool the discriminator; whereas the objective for the discriminator is to produce values close to 1 for data points in the original training set and values close to 0 for augmented data points.
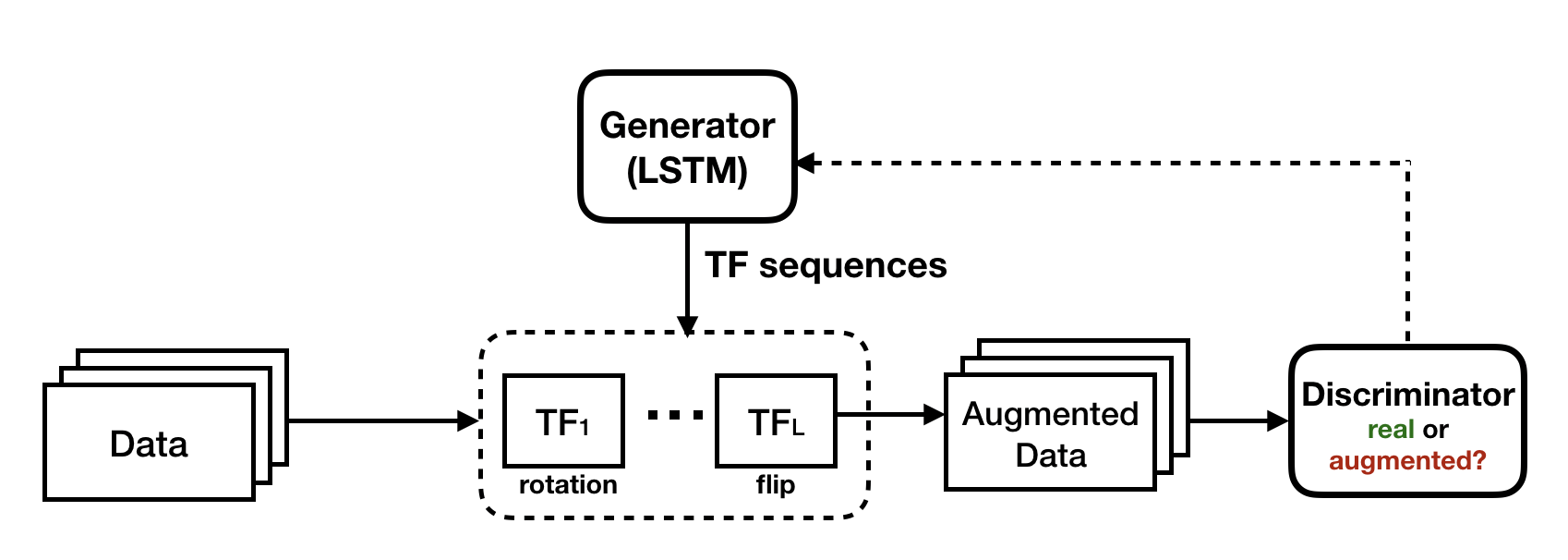
Figure 1: Automating data augmentation with TANDA (Ratner et al. 2017). A TF sequence generator is trained adversarially to produce augmented images that are realistic compared to training data.
Does learning an augmentation model produce better end classifier results than heuristic data augmentation approaches? In our experiments, we show the efficacy of our approach on both image and text datasets, achieving improvements of 4.0% on CIFAR-10, 1.4 F1 points on the ACE relation extraction task, and 3.4% on a medical imaging dataset, as compared to standard heuristic augmentation approaches.
AutoAugment
Using a similar framework, AutoAugment (Cubuk et al. 2018) demonstrated state-of-the-art performance using learned augmentation policies. In this work, a TF sequence generator learns to directly optimize for validation accuracy on the end model (see Figure 2), instead of optimizing for realisticness of augmented images as in TANDA. However, the search process can be computationally expensive due to the need to train a classification model in every gradient step for the generator. To address this issue, AutoAugment searches for augmentation policies on a surrogate dataset that is orders of magnitude smaller than the original dataset.
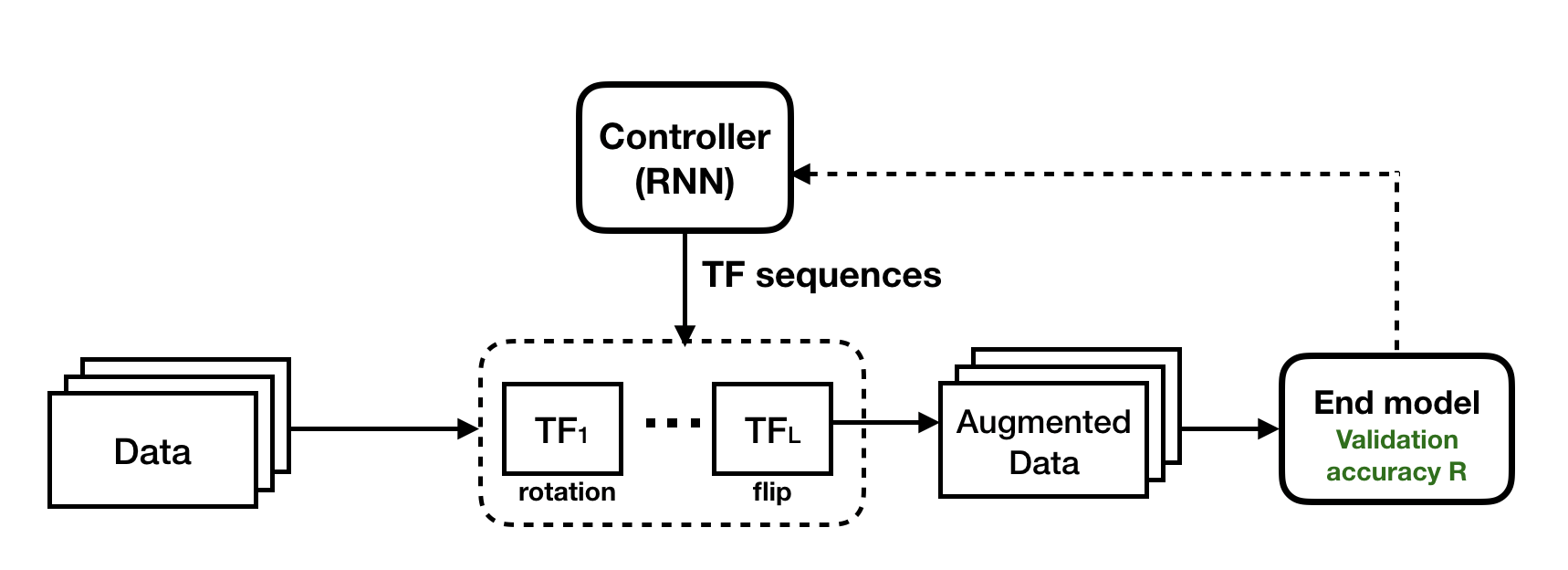
Figure 2: AutoAugment (Cubuk et al. 2018) can be seen as a variant similar to the TANDA framework. A TF sequence generator is trained to optimize for the validation accuracy on the end model.
RandAugment
More recently, RandAugment (Cubuk et al. 2019) found that simple random sampling over the transformation functions with grid search over the parameters of each transformation can outperform AutoAugment. Specifically, they replace the learned TF sequences and probabilities for applying each TF with a parameter-free procedure, which always selects a transformation with uniform probability. They reduce the search space by only learning the magnitude of each transformation function. The overview of RandAugment learning framework is illustrated in Figure 3 below. RandAugment demonstrated 0.6% increase over the previous state-of-the-art on ImageNet classification with less computational cost. In a related work by Xie et al., RandAugment also plays a crucial role in advancing the performance of semi-supervised learning, achieving an error rate of 2.7% on CIFAR-10 with only 4,000 examples.
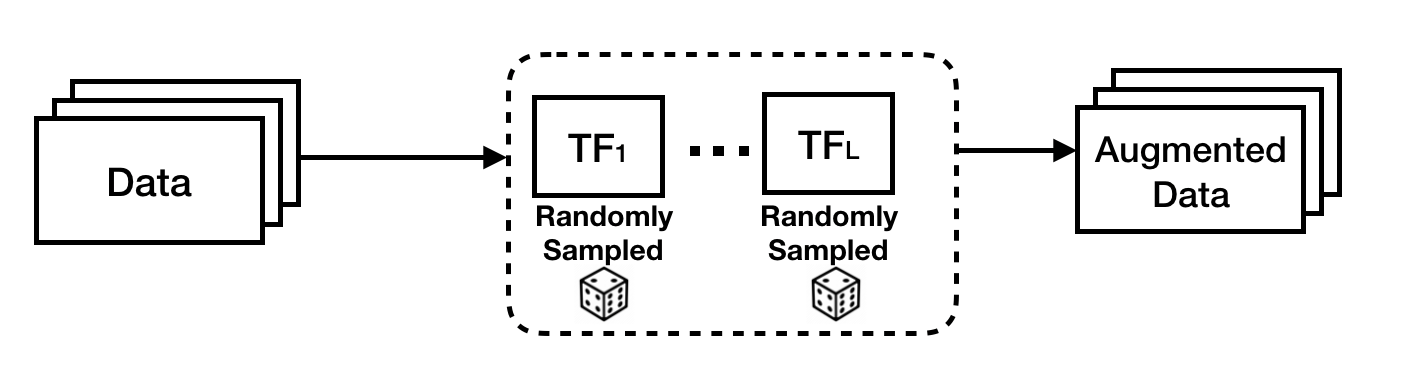
Figure 3: RandAugment (Cubuk et al. 2019) reduces the computational cost by performing random sampling over the transformation function space. Only the magnitude parameters associated with each TF are learned.
Adversarial AutoAugment
Very recently, Zhang et al. proposed a computationally-affordable data augmentation method called Adversarial AutoAugment, establishing a new state-of-the-art on several image classification tasks. They propose an adversarial framework to jointly optimize the end model training and augmentation policy search. As shown in Figure 4, the TF sequence generator attempts to increase the training loss of the end model through generating adversarial augmentation policies, while the end model is trained to be robust against those hard examples and therefore improves the generalization. Compared to AutoAugment, this leads to about 12× reduction in computing cost and 11× shortening in time overhead on ImageNet, although the overall search can still be expensive (1280 GPU hours estimated on 64 NVIDIA Tesla V100s!).
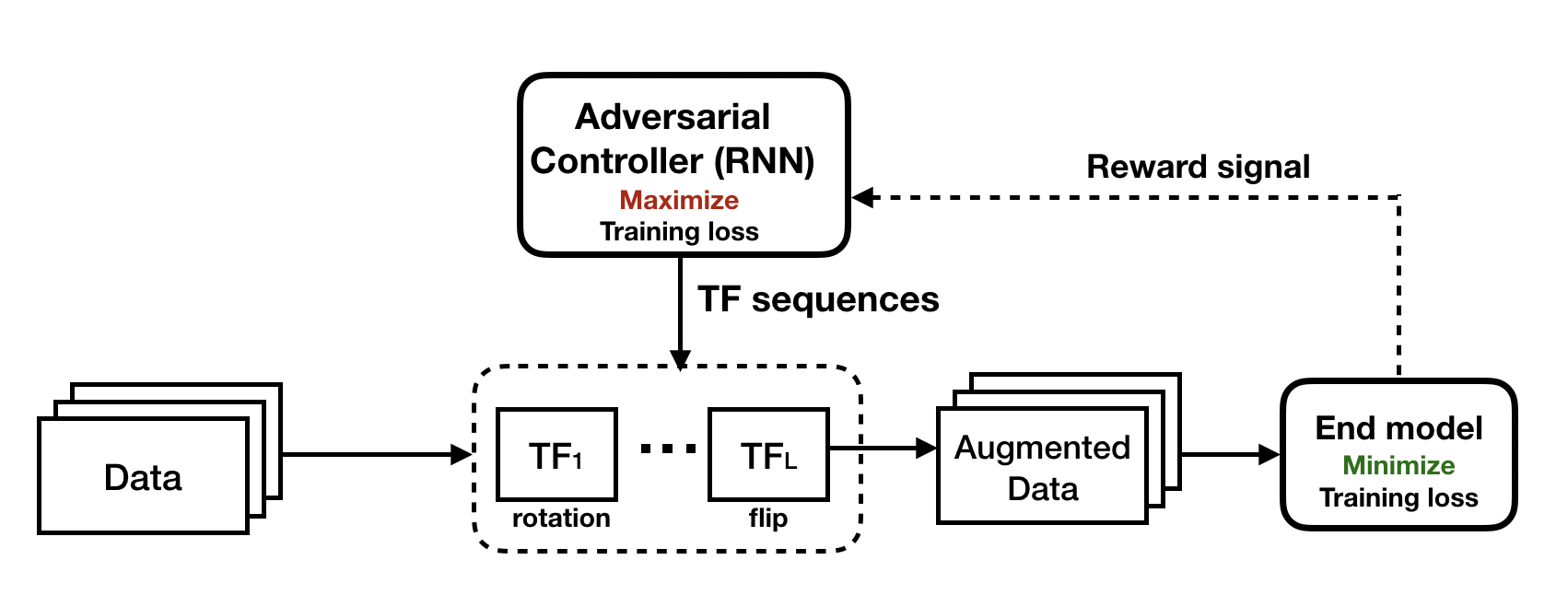
Figure 4. Adversarial AutoAugment training framework (Zhang et al. 2019) is formulated as an adversarial min-max game.
Summary
In this blog post, we have described a few recents practical methods that can automatically learn augmentation policy, showing promise to replace human-designed data augmentations. TANDA proposes a method to learn data augmentations as sequences of Transformation Functions (TFs) provided by users. Using a similar framework, AutoAugment demonstrated state-of-the-art performance using learned augmentation, although the search search process can be computationally expensive. Subsequent works RandAugment and Adversarial AutoAugment have been proposed to reduce the computational cost, establishing state-of-the-art performance on image classification benchmarks.
Links:
- TANDA: https://github.com/HazyResearch/tanda
- AutoAugment: https://github.com/tensorflow/models/tree/master/research/autoaugment
- RandAugment: https://github.com/ildoonet/pytorch-randaugment
- Adversarial AutoAugment: https://arxiv.org/abs/1912.11188
- We will do something that’s faster soon!