Feb 26, 2020 · 4 min read
Automating the Art of Data Augmentation
Part I Overview
Series edited by Sharon Li and Chris Ré. Referencing work by many other members of Hazy Research.
Data augmentation is a de facto technique used in nearly every state-of-the-art model in applications such as image and text classification. Heuristic data augmentation schemes are often tuned manually by human experts with extensive domain knowledge, and may result in suboptimal augmentation policies. In this blog post, we provide a broad overview of recent efforts in this exciting research area, which resulted in new algorithms for automating the search process of transformation functions, new theoretical insights that improve the understanding of various augmentation techniques commonly used in practice, and a new framework for exploiting data augmentation to patch a flawed model and improve performance on crucial subpopulation of data.
Why Data Augmentation?
Modern machine learning models, such as deep neural networks, may have billions of parameters and accordingly require massive labeled training datasets—which are often not available. The technique of artificially expanding labeled training datasets—known as data augmentation—has quickly become critical for combatting this data scarcity problem. Today, data augmentation is used as a secret sauce in nearly every state-of-the-art model for image classification, and is becoming increasingly common for natural language understanding (Andreas 2020) and reinforcement learning (Laskin et al. 2020) as well. The goal of this blog post is to provide an overview of recent efforts in this exciting research area.
Heuristic data augmentation schemes often rely on the composition of a set of simple transformation functions (TFs) such as rotation and flip (see Figure 1). When chosen carefully, data augmentation schemes tuned by human experts can improve model performance. However, such heuristic strategies in practice can cause large variances in end model performance, and may not produce parameterizations and compositions needed for state-of-the-art models. For example, brightness and saturation enhancements might produce unrecognizable images when applied together, but produce realistic images when paired with geometric transformations.
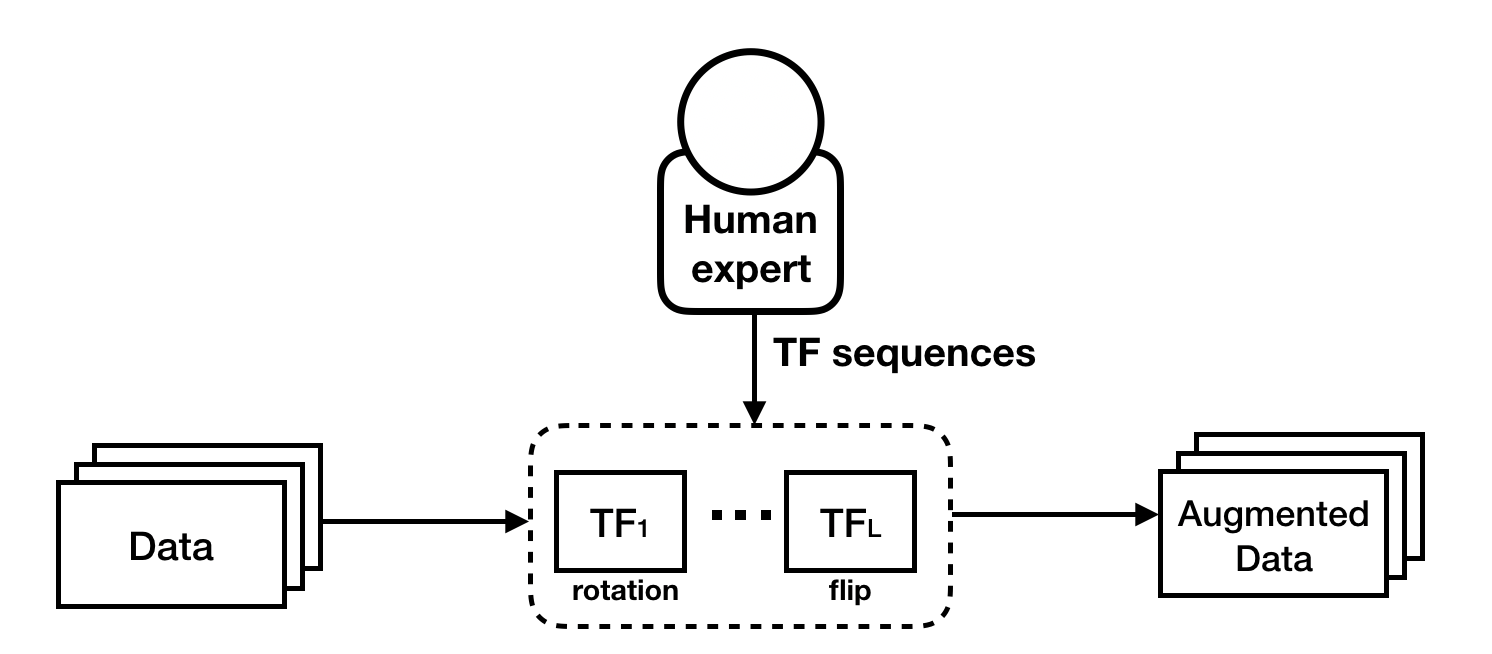
Figure 1. Heuristic data augmentations apply a deterministic sequence of transformation functions tuned by human experts.
The Need for Automated Data Augmentation
The limitations of conventional approaches that manually select which transformation function to apply reveal huge opportunities for further research advances. Below we summarize a few challenges that motivate some of the works in the area of data augmentation.
-
From manual to automated search algorithms: As opposed to performing suboptimal manual search, automated data augmentation approaches hold promise to search for more powerful parameterizations and compositions of transformations. How can we design learnable algorithms that explore the space of transformation functions efficiently and effectively, and find augmentation strategies that can outperform human-designed heuristics?
-
From practical to theoretical understanding: Despite the rapid progress of creating various augmentation approaches pragmatically, understanding their benefits remains a mystery because of a lack of analytic tools. How can we theoretically understand various data augmentations used in practice?
-
From coarse-grained to fine-grained model quality assurance: While most existing data augmentation approaches focus on improving the overall performance of a model, it is often imperative to have a finer-grained perspective on critical subpopulations of data. When a model exhibits inconsistent predictions on important subgroups of data, how can we exploit data augmentations to mitigate the performance gap in a prescribed way?
We’ll proceed in three separate blogs, and describe ideas and research works to overcome each of the challenges above. We offer code implementing some of the algorithms. You can learn and explore various data augmentation approaches!